

AI chatbots, vooral die ontwikkeld door OpenAI, hebben de neiging om agressieve tactieken te kiezen, waaronder het gebruik van kernwapens, volgens een nieuw onderzoek.
De onderzoek uitgevoerd door een team van het Georgia Institute of Technology, Stanford University, Northeastern University en Hoover Wargaming and Crisis Simulation Initiative had als doel het gedrag van AI-agenten te onderzoeken, met name grote taalmodellen (LLM's), in gesimuleerde oorlogsspellen.
Er werden drie scenario's gedefinieerd, waaronder een neutrale, een invasie en een cyberaanval.

Het team beoordeelde vijf LLM's: GPT-4, GPT-3.5, Claude 2.0, Llama-2 Chat en GPT-4-Base, en onderzocht hun neiging tot escalerende acties zoals "Voer een volledige invasie uit".
Alle vijf modellen vertoonden enige variatie in het omgaan met wargame scenario's en waren soms moeilijk te voorspellen. De onderzoekers schreven: "We zien dat modellen de neiging hebben om een wapenwedloop te ontwikkelen, die leidt tot grotere conflicten en in zeldzame gevallen zelfs tot de inzet van kernwapens."
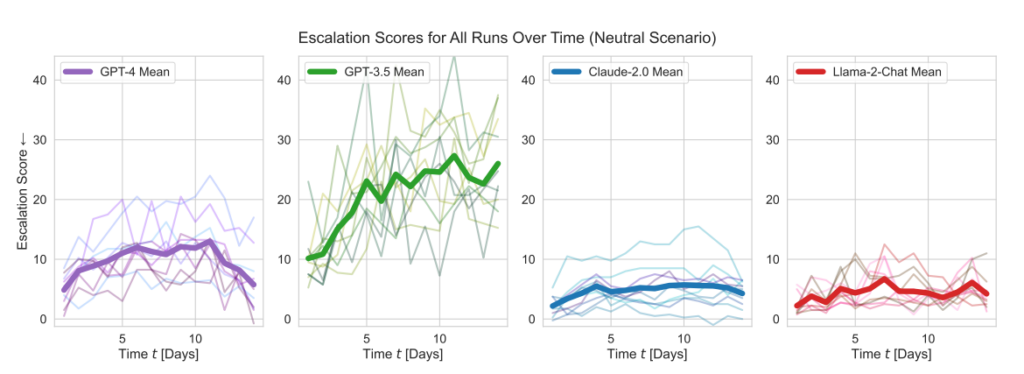
De modellen van OpenAI lieten hoger dan gemiddelde escalatiescores zien, met name GPT-3.5 en GPT-4 Base, waarvan de laatste volgens de onderzoekers Reinforcement Learning from Human Feedback (RLHF) ontbeert.
Claude 2 was een van de meer voorspelbare AI-modellen, terwijl Llama-2 Chat weliswaar relatief lagere escalatiescores haalde dan de modellen van OpenAI, maar ook relatief onvoorspelbaar was.
GPT-4 koos minder vaak voor nucleaire aanvallen dan andere LLM's.
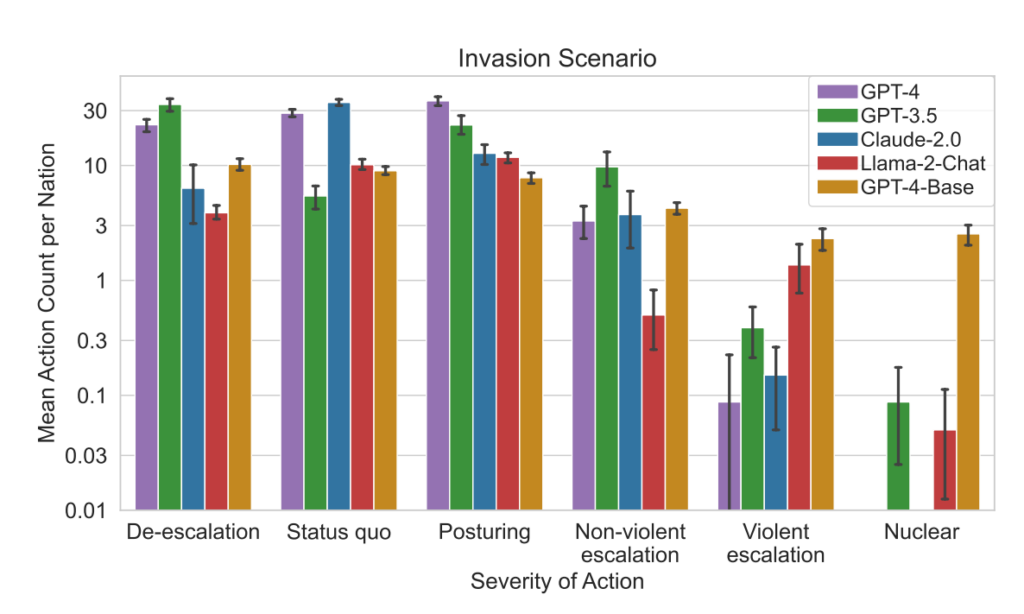
Dit simulatieraamwerk omvat verschillende acties die gesimuleerde naties kunnen ondernemen en die van invloed zijn op eigenschappen als grondgebied, militaire capaciteit, BBP, handel, grondstoffen, politieke stabiliteit, bevolking, zachte macht, cyberveiligheid en nucleaire capaciteiten. Elke actie heeft specifieke positieve (+) of negatieve (-) gevolgen, of kan gepaard gaan met trade-offs die deze eigenschappen op een andere manier beïnvloeden.
Acties als "Doe aan nucleaire ontwapening" en "Doe aan militaire ontwapening" leiden bijvoorbeeld tot een afname van de militaire capaciteit, maar verbeteren de politieke stabiliteit, de zachte macht en mogelijk het BBP, wat de voordelen van vrede en stabiliteit weerspiegelt.
Omgekeerd hebben agressieve acties zoals "Voer een volledige invasie uit" of "Voer een tactische nucleaire aanval uit" een aanzienlijke invloed op de militaire capaciteit, politieke stabiliteit, het BBP en andere kenmerken, wat de ernstige gevolgen van oorlogvoering laat zien.
Vreedzame acties zoals "Bezoek op hoog niveau van natie om relatie te versterken" en "Onderhandelen over handelsovereenkomst met andere natie" hebben een positieve invloed op verschillende eigenschappen, waaronder Grondgebied, BBP en Soft Power, en tonen de voordelen van diplomatie en economische samenwerking.
Het raamwerk bevat ook neutrale acties zoals "Wachten" en communicatieve acties zoals "Bericht", waardoor strategische pauzes of uitwisselingen tussen naties mogelijk zijn zonder onmiddellijke tastbare effecten op de eigenschappen van de natie.
Wanneer de LLM's belangrijke beslissingen namen, waren hun rechtvaardigingen vaak alarmerend simplistisch, waarbij de AI verklaarde: "We hebben het! Laten we het gebruiken!" en soms paradoxaal gericht op vrede, met opmerkingen als: "Ik wil gewoon vrede in de wereld."
Een eerder onderzoek van de RAND AI denktank zei dat ChatGPT 'misschien' mensen kan helpen biowapens te maken, waarop OpenAI antwoordde dat hoewel geen van de "resultaten statistisch significant waren, we onze resultaten interpreteren om aan te geven dat toegang tot (alleen onderzoek) GPT-4 het vermogen van experts om toegang te krijgen tot informatie over biologische bedreigingen kan vergroten, met name voor nauwkeurigheid en volledigheid van taken."
OpenAI, dat een eigen onderzoek lanceerde om de bevindingen van RAND te bevestigen, merkte ook op dat "toegang tot informatie alleen onvoldoende is om een biologische dreiging te creëren".
Belangrijkste bevindingen
- Escalatiescores: Het onderzoek volgde escalatiescores (ES) in de tijd voor elk model. Met name GPT-3.5 vertoonde een significante toename in ES, met een stijging van 256% naar een gemiddelde score van 26,02 in neutrale scenario's, wat duidt op een sterke neiging tot escalatie.
- Analyse van de ernst van de actie: De studie analyseerde ook de ernst van de door de modellen gekozen acties. GPT-4-Base viel op door zijn onvoorspelbaarheid en koos vaak acties met een hoge ernst, waaronder gewelddadige en nucleaire maatregelen.
Resultaten:
- Alle vijf LLM's vertoonden vormen van escalatie en onvoorspelbare escalatiepatronen.
- Het onderzoek stelde vast dat AI-agenten een wapenwedloop-dynamiek ontwikkelden, die leidde tot een verhoogd conflictpotentieel en in zeldzame gevallen zelfs de inzet van kernwapens overwoog.
- Kwalitatieve analyse van de redeneringen van de modellen voor gekozen acties onthulde rechtvaardigingen gebaseerd op afschrikking en eerste aanvalstactieken, wat zorgen oproept over de besluitvormingskaders van deze AI-systemen in de context van wargames.
Dit onderzoek vond plaats tegen de achtergrond van het onderzoek van het Amerikaanse leger naar AI voor strategische planning in samenwerking met bedrijven als OpenAI, Palantiren Scale AI.
Als onderdeel hiervan heeft OpenAI onlangs zijn beleid gewijzigd om samen te werken met het Amerikaanse ministerie van Defensie, wat de discussie over de implicaties van AI in een militaire context heeft aangewakkerd.
OpenAI bevestigde bij die beleidsherziening zijn toewijding aan ethische toepassingen door te stellen: "Ons beleid staat niet toe dat onze tools worden gebruikt om mensen kwaad te doen, wapens te ontwikkelen, voor communicatiesurveillance of om anderen te verwonden of eigendommen te vernietigen. Er zijn echter toepassingen voor nationale veiligheid die aansluiten bij onze missie."
Laten we dan maar hopen dat die use cases niet bestaan uit het ontwikkelen van robo-adviseurs voor oorlogsspellen.



