

Luke Farritor, een 21-jarige student informatica aan de Universiteit van Nebraska-Lincoln, heeft de tekst onthuld in een verkoolde rol uit het oude Herculaneum.
Deze rol is onleesbaar sinds de vulkaanuitbarsting in 79 na Christus die ook Pompeii overspoelde. Farritor's algoritme voor machinaal leren lokaliseerde met succes Griekse letters op de opgerolde papyrus, waaronder het woord πορϕυρας (porphyras), wat 'paars' betekent.
Zijn techniek was gebaseerd op het identificeren van kleine, genuanceerde verschillen in de textuur van het oppervlak om zijn neurale netwerk te trainen in het detecteren van inkt, en op zijn beurt, leterring.
"Toen ik het eerste beeld zag, was ik geschokt," zei hij. zei Federica Nicolardi, een papyroloog van de Universiteit van Napels. "Het was zo'n droom," vervolgt ze, "ik kan echt iets zien van de binnenkant van een rol."
De rollen, die bedolven werden door de uitbarsting van de Vesuvius in 79 na Christus, zijn grotendeels ontoegankelijk gebleven vanwege hun fragiele staat.
Het handmatig afrollen van de verkoolde rollen zorgt ervoor dat ze uit elkaar vallen, waardoor geleerden vrezen dat de inhoud voor altijd een mysterie zal blijven.

Zoals Nicolardi uitlegde: "Dit zijn zulke gekke voorwerpen. Ze zijn allemaal verfrommeld en geplet."
De uitdaging van het ontcijferen van de rollen herkende de Vesuvius Uitdaging opgezet, waarbij verschillende prijzen werden uitgereikt, waaronder een hoofdprijs van US$700.000 voor het ontcijferen van meerdere passages uit een boekrol.
Op 12 oktober werd bekendgemaakt dat Farritor een prijs van $40.000 had gewonnen voor het identificeren van meer dan 10 tekens in een klein gedeelte van de papyrus.
Een andere deelnemer, Youssef Nader van de Vrije Universiteit Berlijn, ontving $10.000 voor de tweede plaats.
Thea Sommerschield, historica van het oude Griekenland en Rome, beschreef de mogelijkheid om eindelijk letters en woorden in de rollen te onderscheiden als "extreem opwindend".
Sommerschield zei dat de interpretatie hiervan "een revolutie teweeg zou kunnen brengen in onze kennis van de oude geschiedenis en literatuur" uit de regio.
Het is niet de eerste keer dat onderzoekers hebben geprobeerd om deze oude verkoolde rollen te lezen. In 2019 probeerde Brent Seales, een professor in computerwetenschappen die gespecialiseerd is in het virtueel lezen en bewaren van oude rollen, de rollen "virtueel uit te pakken" met behulp van CT-scans (X-ray computed tomography).
In 2016 slaagde Seales erin om met een oud Hebreeuws perkament dat in 1970 in Ein Gedi, Israël werd gevonden, delen van het Boek Leviticus te onthullen.
De rollen uit Herculaneum vormden echter een andere uitdaging: de inkt, gemaakt van houtskool en water, viel niet op in de scans.
Dit is waar Farritor in slaagde door zich te richten op een specifieke subtiele textuur, 'craquelé' genaamd, voor sporen van inkt.
Farritor zei: "Ik stond op en neer te springen," nadat zijn algoritme vijf letters onthulde uit een pas uitgebracht segment. "Oh mijn hemel, dit gaat echt werken," realiseerde hij zich.
Kort daarna verfijnde hij zijn model en identificeerde hij de vereiste tien letters voor de prijs, waarbij het woord 'paars' nog niet eerder was geïdentificeerd in de rollen van Herculaneum.
De hoofdprijs van de Vesuvius Challenge moet nog onthuld worden, met 31 december als deadline.
AI voor het decoderen van oude talen
Zes millennia geleden vestigden de Sumeriërs zich in Mesopotamië, het land tussen de rivieren de Tigris en de Eufraat.
Deze regio, die het huidige Irak, Koeweit, Turkije en Syrië omvat, was getuige van de evolutie van kleine agrarische gemeenschappen tot grote stedelijke beschavingen. Steden als Uruk bloeiden op en integreerden ingewikkelde kanalen, irrigatiestructuren en bestuurscentra. Het was een cruciaal tijdperk voor de vooruitgang en evolutie van de mensheid.
De Soemeriërs schreven in een schrift dat bekend staat als spijkerschrift. Voor dit schrift moest riet in klei worden gedrukt, waardoor complexe logo-lettergrepige inscripties ontstonden. Spijkerschrift is geen taal - het is een schrift dat in drie millennia zo'n 15 talen omvatte.

Terwijl spijkerschrift voornamelijk werd gebruikt als administratief hulpmiddel voor taken als het registreren van vee of transacties, ontstond er rond 2700 v.Chr. een breed scala aan meer filosofische en creatieve geschriften.
Een van de meest opmerkelijke van deze geschriften is de Epos van Gilgamesjdie zich uitstrekt over twaalf tabletten.
Enrique Jiménez van de Ludwig Maximilians Universiteit in München stelt: "De helft van de menselijke geschiedenis ligt ingekapseld in deze spijkerschrifttabletten."
Echter, slechts 75 individuen, volgens Nieuwe Wetenschapperkan spijkerschrift decoderen, ondanks tienduizenden onvertaalde tabletten wereldwijd.
Machine learning helpt onderzoekers nu bij het ontrafelen van de verhalen die op de stenen tafelen staan. Het helpt hen bij het opvullen van hiaten en het chronologisch ordenen van de teksten om meer te ontdekken over hoe de oude Sumeriërs leefden.
De rol van machinaal leren bij het ontcijferen van oude teksten
Enrique Jiménez en zijn team hebben de Elektronische Babylonische literatuur, een samenwerking tussen archeologen, datawetenschappers en historici.
Om spijkerschrifttabletten te analyseren, gebruikte het team een machine learning-techniek die oorspronkelijk was ontworpen voor het vergelijken van gensequenties. Deze AI voorspelt de inhoud van ontbrekende delen en de grenzen waarop fragmenten op elkaar aansluiten.
Deze techniek leidde tot ontdekkingen zoals ontbrekende delen van het Epos van Gilgamesj en een nieuwgevonden Mesopotamisch genre dat educatieve parodieën en grappen voor kinderen beschrijft.
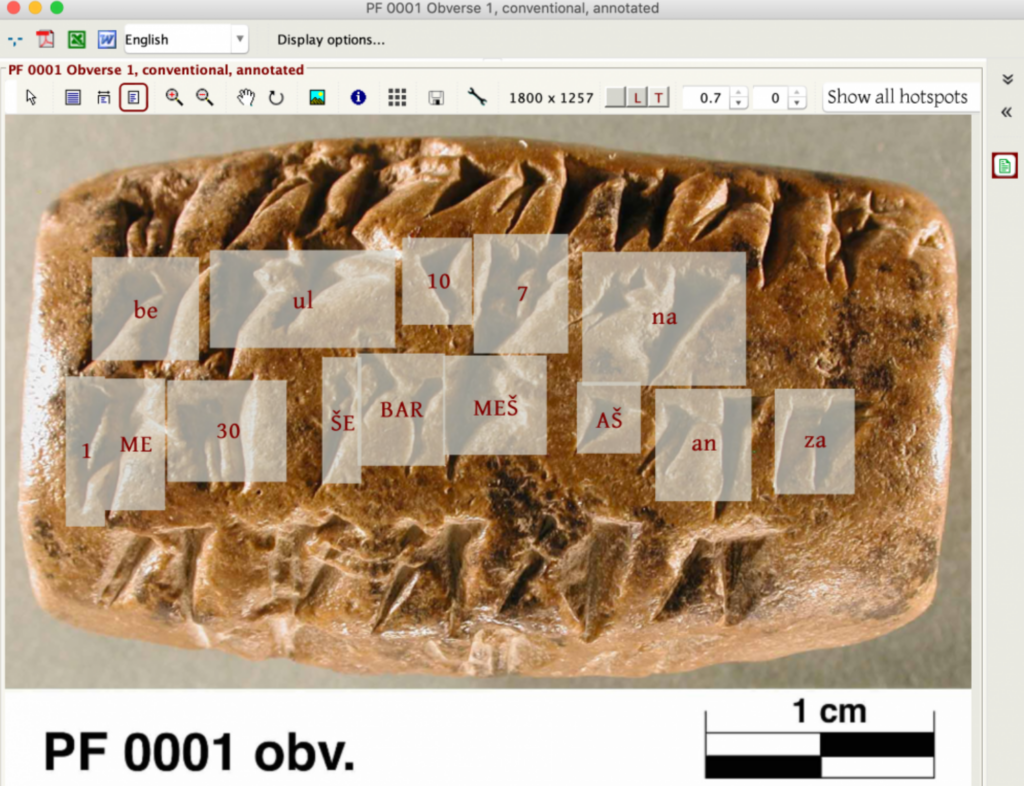
In 2020, een apart model, DeepScribewerd getraind op 6.000 geannoteerde afbeeldingen uit de Archief vestingwerken Persepolisdie ongeveer 100.000 symbolen uit de Elamitische taal (uit het huidige Iran) specificeert, gedateerd rond 500 voor Christus.
Door gebruik te maken van de middelen van het UChicago Research Computing Center hebben Krishnan en Eddie Williams een model getraind dat deze tekens kan decoderen met een indrukwekkende nauwkeurigheid van 80%.
Het team is van plan DeepScribe te ontwikkelen tot een veelzijdig ontcijferingshulpmiddel, dat kan worden omgeschoold voor andere talen dan het Elamiet.
DeepMind heeft ook onderzoek gedaan naar het decoderen van oude talen met behulp van machine learning - in dit geval beschadigde Oudgriekse tabletten.
Genoemd IthacaDit model restaureerde teksten met een precisie van 72%, benaderde hun leeftijd binnen drie decennia en vermoedde zelfs hun oorsprong met een nauwkeurigheid van 71%.

De training van Ithaca bestond uit 60.000 teksten van 700 voor Christus tot 500 na Christus, gelabeld met gegevens over hun tijd en plaats in 84 oude gebieden.
De kruising van oude teksten en geavanceerde AI laat zien hoe zelfs millennia oude mysteries niet immuun zijn voor de vooruitgang van moderne technologie.
Door het oude met het nieuwe te vermengen, bewaren onderzoekers zowel de geschiedenis als het in gebruik nemen van tot nu toe onbekende archeologische kennis.
Deze doorbraken onderstrepen de grenzeloze mogelijkheden wanneer we menselijke nieuwsgierigheid samenvoegen met technologische bekwaamheid en bewijzen dat er een nieuwe lens is waardoor we de wonderen van ons collectieve verleden kunnen bekijken.




{kind=link}