

Nvidia heeft nieuwe open source software aangekondigd die naar eigen zeggen de inferentieprestaties op de H100 GPU's zal verbeteren.
Veel van de huidige vraag naar Nvidia's GPU's is om rekenkracht op te bouwen voor het trainen van nieuwe modellen. Maar zodra die modellen zijn getraind, moeten ze worden gebruikt. Inferentie in AI verwijst naar het vermogen van een LLM zoals ChatGPT om conclusies te trekken of voorspellingen te doen op basis van gegevens waarop het getraind is en output te genereren.
Als je ChatGPT probeert te gebruiken en er verschijnt een bericht dat de servers overbelast zijn, dan komt dat omdat de computerhardware moeite heeft om de vraag naar inferentie bij te houden.
Nvidia zegt dat zijn nieuwe software, TensorRT-LLM, de bestaande hardware een stuk sneller en ook energiezuiniger kan maken.
De software bevat geoptimaliseerde versies van de populairste modellen, waaronder Meta Llama 2, OpenAI GPT-2 en GPT-3, Falcon, Mosaic MPT en BLOOM.
Het maakt gebruik van een aantal slimme technieken zoals het efficiënter bundelen van inferentietaken en kwantisatietechnieken om de prestaties te verbeteren.
LLM's gebruiken over het algemeen 16-bits waarden met drijvende komma om gewichten en activeringen weer te geven. Tijdens de inferentie worden deze waarden met behulp van quantisatie gereduceerd tot 8-bits drijvendekommawaarden. De meeste modellen slagen erin hun nauwkeurigheid te behouden met deze verminderde precisie.
Bedrijven die beschikken over computerinfrastructuur gebaseerd op de H100 GPU's van Nvidia kunnen een enorme verbetering in inferentieprestaties verwachten zonder een cent te hoeven uitgeven door TensorRT-LLM te gebruiken.
Nvidia gebruikte een voorbeeld van het uitvoeren van een klein open source model, GPT-J 6, om artikelen in de CNN/Daily Mail dataset samen te vatten. De oudere A100-chip wordt gebruikt als basissnelheid en vervolgens vergeleken met de H100 zonder en vervolgens met TensorRT-LLM.
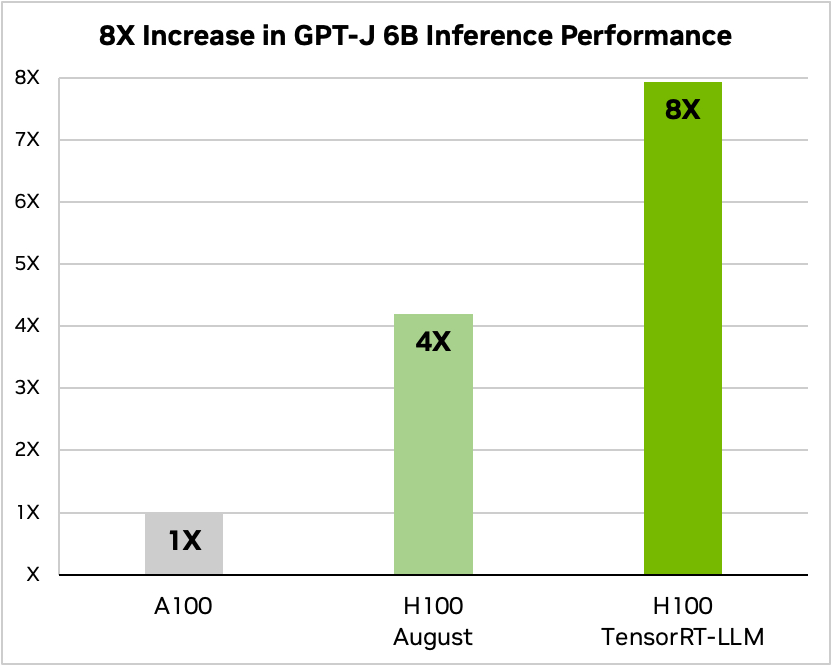
Bron: Nvidia
En hier is een vergelijking met Meta's Llama 2
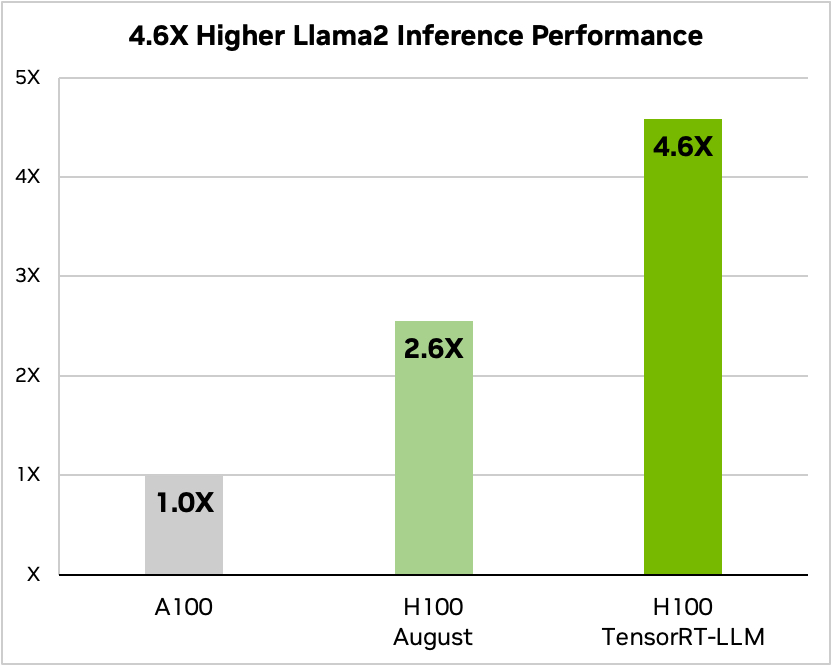
Bron: Nvidia
Nvidia zegt dat zijn tests hebben aangetoond dat, afhankelijk van het model, een H100 met TensorRT-LLM tussen 3,2 en 5,6 keer minder energie verbruikt dan een A100 tijdens inferentie.
Als je AI-modellen draait op H100 hardware, betekent dit niet alleen dat je inferentieprestaties bijna verdubbelen, maar ook dat je energierekening een stuk lager wordt als je deze software installeert.
TensorRT-LLM zal ook beschikbaar worden gemaakt voor Nvidia's Grace Hopper Superchips maar het bedrijf heeft nog geen prestatiecijfers vrijgegeven voor de GH200 met de nieuwe software.
De nieuwe software was nog niet klaar toen Nvidia zijn GH200 Superchip aan de industriestandaard MLPerf AI prestatie-benchmarkingstests onderwierp. Uit de resultaten bleek dat de GH200 tot 17% beter presteerde dan een single-chip H100 SXM.
Als Nvidia met de GH200 zelfs maar een bescheiden prestatiestijging kan realiseren door TensorRT-LLM te gebruiken, dan zal het bedrijf zijn naaste concurrenten ver achter zich laten. Verkoper zijn voor Nvidia moet op dit moment de makkelijkste baan ter wereld zijn.



