

OpenAI baas Sam Altman haalde uit naar de EU door te suggereren dat het EU-ontwerp voor een AI-wet overregulerend was en onmogelijk om aan te voldoen. Dagen later tweette hij dat OpenAI enthousiast is om zijn activiteiten in de EU voort te zetten.
Altman vliegt door Europa en ontmoet politici uit Duitsland, Frankrijk, Spanje, Polen en het Verenigd Koninkrijk. Naar verluidt heeft hij echter een afspraak in Brussel afgezegd, waar wetgevers bezig zijn met het opstellen van de AI-wet van de EU.
Hij had eerder verklaard dat OpenAI moeite zou hebben om aan de wet te voldoen: "Als we kunnen voldoen, zullen we dat doen, en als we dat niet kunnen, zullen we onze activiteiten staken. We zullen het proberen. Maar er zijn technische grenzen aan wat mogelijk is."
Na wat reacties op sociale media leek Altman op zijn commentaar terug te komen; "we zijn enthousiast om hier te blijven werken en hebben natuurlijk geen plannen om te vertrekken."
zeer productieve week van gesprekken in europa over hoe we AI het beste kunnen reguleren! we zijn verheugd dat we hier kunnen blijven opereren en hebben natuurlijk geen plannen om te vertrekken.
- Sam Altman (@sama) 26 mei 2023
Altman had eerder vertelde aan Reuters"Het huidige ontwerp van de AI-wet van de EU zou overregulerend zijn, maar we hebben gehoord dat het wordt teruggetrokken."
De EU reageerde - de Nederlandse Europarlementariër Kim van Sparrentak zei dat wetgevers die de AI-wet opstellen "zich niet moeten laten chanteren door Amerikaanse bedrijven".
Ze zei verder: "Als OpenAI niet kan voldoen aan de basisvereisten voor gegevensbeheer, transparantie, veiligheid en beveiliging, dan zijn hun systemen niet geschikt voor de Europese markt."
AI-wet zou grote taalmodellen (LLM's) in een "hoog risico" categorie kunnen plaatsen
De EU AI Act definieert verschillende categorieën van AI, waaronder een "hoog risico" categorie die onderworpen is aan strenge regels voor transparantie en monitoring. Dit lijkt de kern van Altmans angsten te zijn.
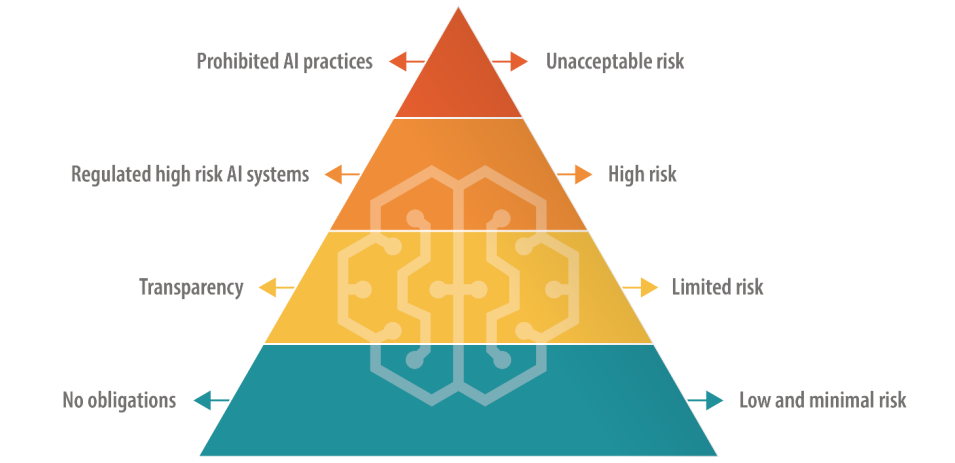
Volgens het huidige ontwerp moeten bedrijven die AI's met een hoog risico inzetten, al het auteursrechtelijk beschermde materiaal in opleidingsgegevens en logboekactiviteiten openbaar maken om de repliceerbaarheid en traceerbaarheid van outputs te garanderen. Dit kan kostbaar en lastig zijn voor kleinere AI-bedrijven.
Auteursrechtelijk beschermd materiaal blijft een knelpunt
OpenAI is geen open boek als het gaat om auteursrechtelijk beschermd materiaal in zijn trainingsgegevens.
Gebleken is dat de AI regels herhalen van verschillende romans, waaronder Harry Potter en Game of Thrones. Onderzoekers suggereren Dit is waarschijnlijk omdat passages uit boeken vaak in het publieke domein verschijnen.
Er zijn veel hangende rechtszaken in verband met auteursrecht tegen OpenAI, Microsoft en de makers achter afbeeldingsgeneratoren zoals Reis halverwege. Op dit moment weten we gewoon niet in welke mate AI gebruik maakt van auteursrechtelijk beschermde gegevens en welke methoden er zijn om deze gegevens te achterhalen.
De EU wil daar verandering in brengen door transparantieregels in te voeren, die kunnen veranderen hoe AI's worden getraind en dus hoe ze presteren.
We leven misschien in een ongereguleerde AI-zeepbel die op het punt staat te barsten.



