

Microsoft lanserte Phi-3 Mini, en liten språkmodell som er et ledd i selskapets strategi for å utvikle lette, funksjonsspesifikke AI-modeller.
Utviklingen av språkmodeller har gått i retning av stadig større parametere, treningsdatasett og kontekstvinduer. Skalering av størrelsen på disse modellene har gitt kraftigere funksjoner, men til en viss pris.
Den tradisjonelle måten å trene opp en LLM på er å la den bruke enorme datamengder, noe som krever enorme databehandlingsressurser. Opplæring av en LLM som GPT-4, for eksempel, anslås å ha tatt rundt tre måneder og å ha kostet over $21 millioner.
GPT-4 er en flott løsning for oppgaver som krever komplekse resonnementer, men overkill for enklere oppgaver som innholdsproduksjon eller en salgschatbot. Det er som å bruke en sveitsisk lommekniv når alt du trenger er en enkel brevåpner.
Med bare 3,8B parametere er Phi-3 Mini bitteliten. Likevel sier Microsoft at den er en ideell, lett og rimelig løsning for oppgaver som å oppsummere et dokument, trekke ut innsikt fra rapporter og skrive produktbeskrivelser eller innlegg i sosiale medier.
MMLUs referansetall viser at Phi-3 Mini og de større Phi-modellene som ennå ikke er lansert, slår større modeller som Mistral 7B og Gemma 7B.
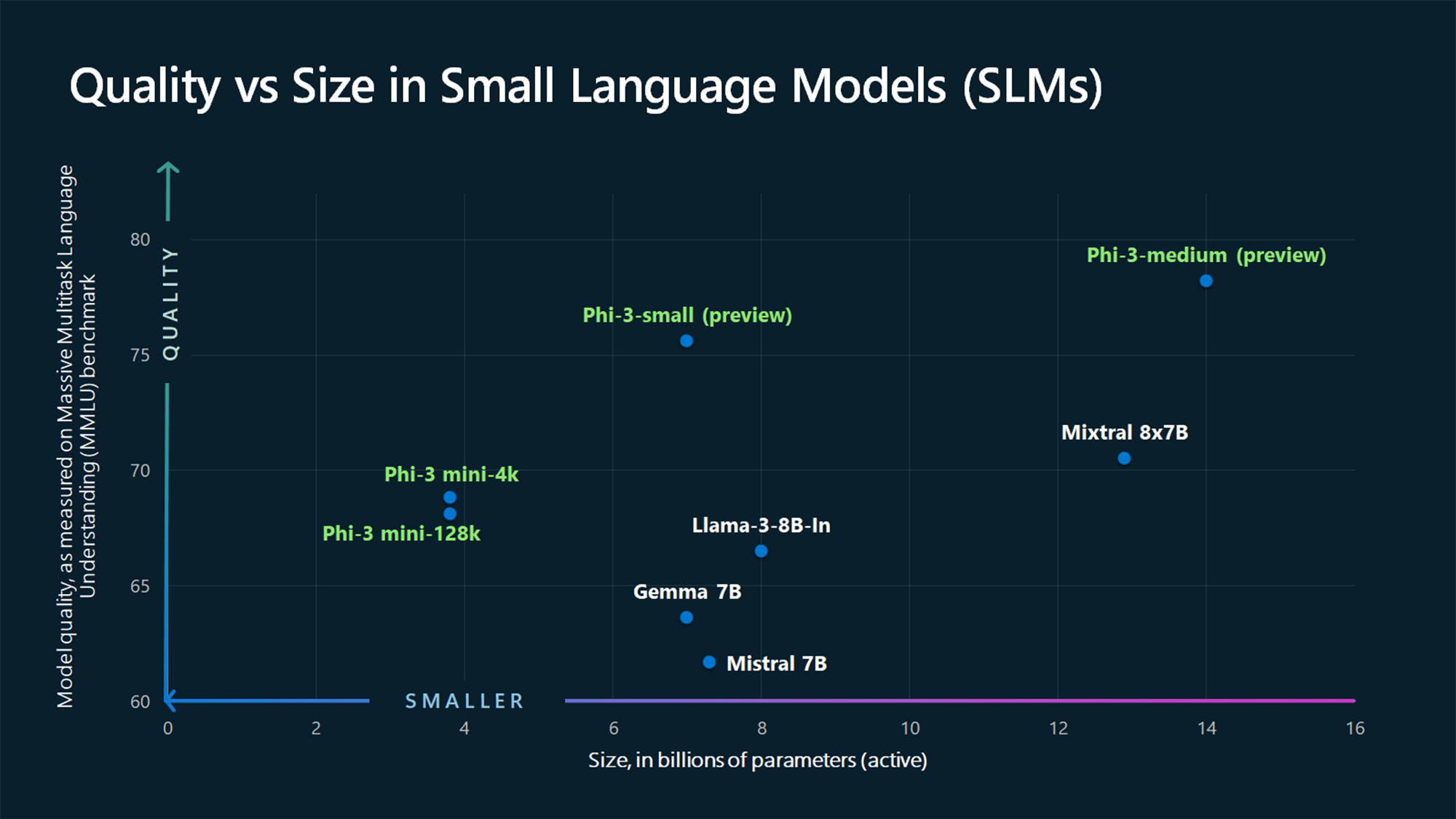
Microsoft sier at Phi-3-small (7B parametere) og Phi-3-medium (14B parametere) vil være tilgjengelig i Azure AI Model Catalog "om kort tid".
Større modeller som GPT-4 er fortsatt gullstandarden, og vi kan nok forvente at GPT-5 blir enda større.
SLM-er som Phi-3 Mini har noen viktige fordeler som større modeller ikke har. SLM-er er billigere å finjustere, krever mindre databehandling og kan kjøres på enheten selv i situasjoner der det ikke er tilgang til Internett.
En SLM i utkanten gir mindre ventetid og maksimalt personvern fordi det ikke er behov for å sende data frem og tilbake til skyen.
Her er Sebastien Bubeck, VP for GenAI-forskning hos Microsoft AI, med en demonstrasjon av Phi-3 Mini. Den er superrask og imponerende til å være en så liten modell.
phi-3 er her, og den er ... god :-).
Jeg har laget en kort demo for å gi deg en følelse av hva phi-3-mini (3.8B) kan gjøre. Følg med for utgivelsen av åpne vekter og flere kunngjøringer i morgen tidlig!
(Og selvfølgelig ville ikke dette vært komplett uten den vanlige tabellen med referanseverdier!) pic.twitter.com/AWA7Km59rp
- Sebastien Bubeck (@SebastienBubeck) 23. april 2024
Kuraterte syntetiske data
Phi-3 Mini er et resultat av at man har forkastet ideen om at store datamengder er den eneste måten å trene opp en modell på.
Sebastien Bubeck, Microsofts visepresident for generativ AI-forskning, spurte: "I stedet for å trene på bare rå nettdata, hvorfor ser du ikke etter data som er av ekstremt høy kvalitet?"
Microsoft Researchs maskinlæringsekspert Ronen Eldan leste godnatthistorier for datteren sin da han lurte på om en språkmodell kunne lære bare ved hjelp av ord som en fireåring kunne forstå.
Dette førte til et eksperiment der de skapte et datasett som startet med 3000 ord. Ved hjelp av dette begrensede ordforrådet fikk de en LLM til å lage millioner av korte barnefortellinger som ble samlet i et datasett kalt TinyStories.
Forskerne brukte deretter TinyStories til å trene opp en ekstremt liten modell med 10 millioner parametere, som deretter var i stand til å generere "flytende fortellinger med perfekt grammatikk".
De fortsatte å iterere og skalere denne syntetiske datagenereringsmetoden for å skape mer avanserte, men nøye kuraterte og filtrerte syntetiske datasett som til slutt ble brukt til å trene Phi-3 Mini.
Resultatet er en liten modell som er rimeligere i drift, samtidig som ytelsen er sammenlignbar med GPT-3.5.
Mindre, men mer kapable modeller vil føre til at selskaper går bort fra å bare bruke store LLM-er som GPT-4 som standard. Vi kan også snart se løsninger der en LLM tar seg av de tunge løftene, mens enklere oppgaver delegeres til lettvektsmodeller.



