

Elon Musk kunngjorde betalanseringen av xAIs chatbot Grok, og den første statistikken gir oss en idé om hvordan den står seg i forhold til andre modeller.
Den Grok chatbot er basert på xAIs frontier-modell Grok-1, som selskapet har utviklet i løpet av de siste fire månedene. xAI har ikke sagt hvor mange parametere den ble trent med, men kom med noen tall for forgjengeren.
Grok-0, prototypen for den nåværende modellen, ble trent på 33 milliarder parametere, så vi kan sannsynligvis anta at Grok-1 ble trent på minst like mange.
Det høres ikke mye ut, men xAI hevder at Grok-0-ytelsen "nærmer seg LLaMA 2 (70B)-kapasiteten på standard LM-benchmarks", selv om den brukte halvparten av treningsressursene.
I mangel av et parametertall må vi ta selskapet på ordet når det beskriver Grok-1 som "state-of-the-art" og at den er "betydelig kraftigere" enn Grok-0.
Grok-1 ble testet ved å evaluere den på disse standard benchmarkene for maskinlæring:
- GSM8k: Matteoppgaver for ungdomsskolen
- MMLU: Tverrfaglige flervalgsspørsmål
- HumanEval: Oppgave for fullføring av Python-kode
- MATH: Matematikkoppgaver for ungdomsskolen og videregående skole skrevet i LaTeX
Her er et sammendrag av resultatene.
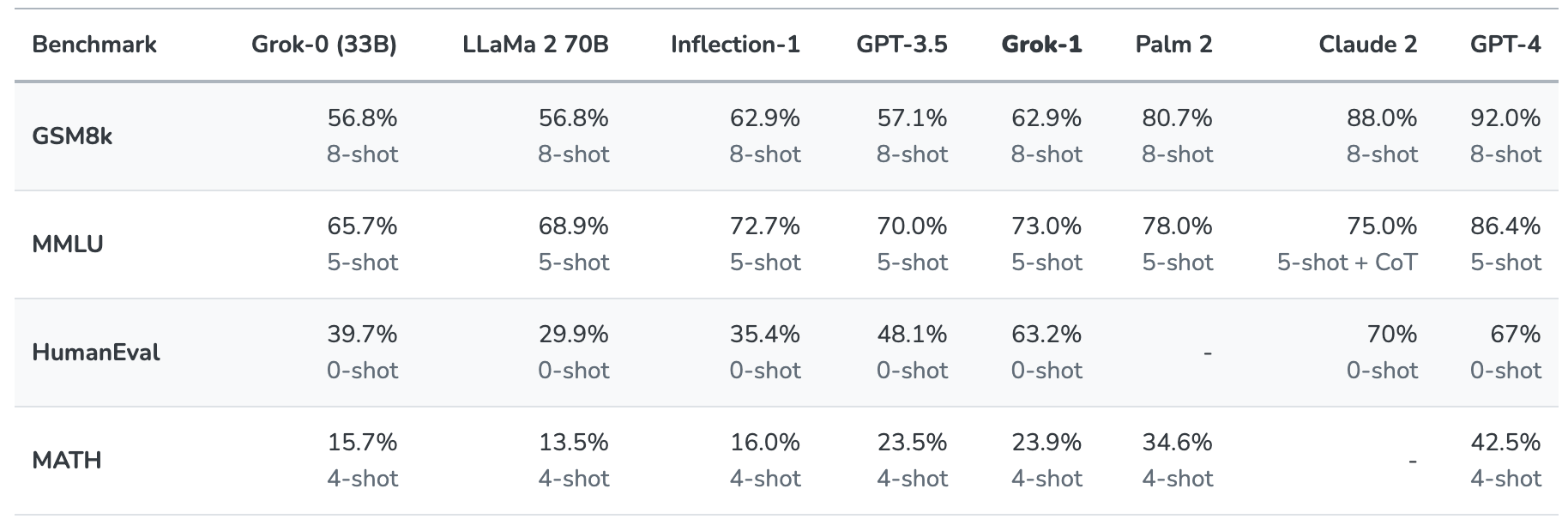
Resultatene er interessante fordi de i det minste gir oss en viss pekepinn på hvordan Grok står seg i forhold til andre frontier-modeller.
xAI sier at disse tallene viser at Grok-1 slår "alle andre modeller i sin beregningsklasse" og bare ble slått av modeller som var trent opp med "betydelig større mengder treningsdata og beregningsressurser".
GPT-3.5 har 175 milliarder parametere, så vi kan anta at Grok-1 har mindre enn det, men sannsynligvis mer enn de 33 milliardene som prototypen har.
Grok-chatboten er beregnet på oppgaver som å svare på spørsmål, hente informasjon, skrive kreative tekster og hjelpe til med koding. På grunn av det mindre kontekstvinduet er det mer sannsynlig at den vil bli brukt til kortere interaksjoner enn superprompt-brukstilfeller.
Med en kontekstlengde på 8192 har Grok-1 bare halvparten så lang kontekst som GPT-3.5 har. Dette er en indikasjon på at xAI sannsynligvis hadde til hensikt at Grok-1 skulle bytte ut en lengre kontekst med bedre effektivitet.
Selskapet sier at noe av den nåværende forskningen fokuserer på "forståelse og gjenfinning av lange kontekster", så den neste versjonen av Grok kan godt ha et større kontekstvindu.
Det nøyaktige datasettet som ble brukt til å trene Grok-1 er ikke klart, men det inkluderte nesten helt sikkert tweets på X, og Grok-chatboten har også tilgang til internett i sanntid.
Vi må vente på flere tilbakemeldinger fra betatestere for å få en reell følelse av hvor god modellen faktisk er.
Vil Grok hjelpe oss med å løse livets, universets og altings mysterier? Kanskje ikke helt ennå, men det er en underholdende start.



