

OpenAI-sjef Sam Altman gikk i rette med EU og antydet at EUs utkast til AI-lov var overregulerende og umulig å tilfredsstille. Noen dager senere tvitret han at OpenAI er glade for å kunne fortsette virksomheten i EU.
Altman har reist rundt i Europa og møtt politikere fra Tyskland, Frankrike, Spania, Polen og Storbritannia. Han skal imidlertid ha avlyst et møte i Brussel, der lovgiverne er i ferd med å utforme EUs AI Act.
Han har tidligere uttalt at OpenAI vil kjempe for å overholde loven: "Hvis vi kan overholde den, vil vi gjøre det, og hvis vi ikke kan det, vil vi legge ned virksomheten. Vi kommer til å prøve. Men det finnes tekniske grenser for hva som er mulig."
Etter reaksjoner på sosiale medier, syntes Altman å snu i kommentarene sine: "Vi er glade for å fortsette å operere her, og har selvfølgelig ingen planer om å forlate stedet."
veldig produktiv uke med samtaler i europa om hvordan vi best kan regulere AI! vi er glade for å kunne fortsette å operere her, og har selvsagt ingen planer om å forlate stedet.
- Sam Altman (@sama) 26. mai 2023
Altman hadde tidligere fortalte Reuters"Det nåværende utkastet til EUs AI-lov vil være overregulerende, men vi har hørt at det kommer til å bli trukket tilbake."
EU reagerte - den nederlandske EU-parlamentarikeren Kim van Sparrentak sa at lovgiverne som utarbeider AI-loven, "ikke bør la seg presse av amerikanske selskaper".
Hun fortsatte med å si: "Hvis OpenAI ikke kan oppfylle grunnleggende krav til datastyring, åpenhet, sikkerhet og trygghet, er ikke systemene deres egnet for det europeiske markedet."
AI-loven kan plassere store språkmodeller (LLM-er) i en "høyrisikokategori"
EUs AI-lov definerer ulike kategorier av AI, inkludert en "høyrisikokategori" som er underlagt strenge regler for åpenhet og overvåking. Dette ser ut til å være det Altman frykter mest.
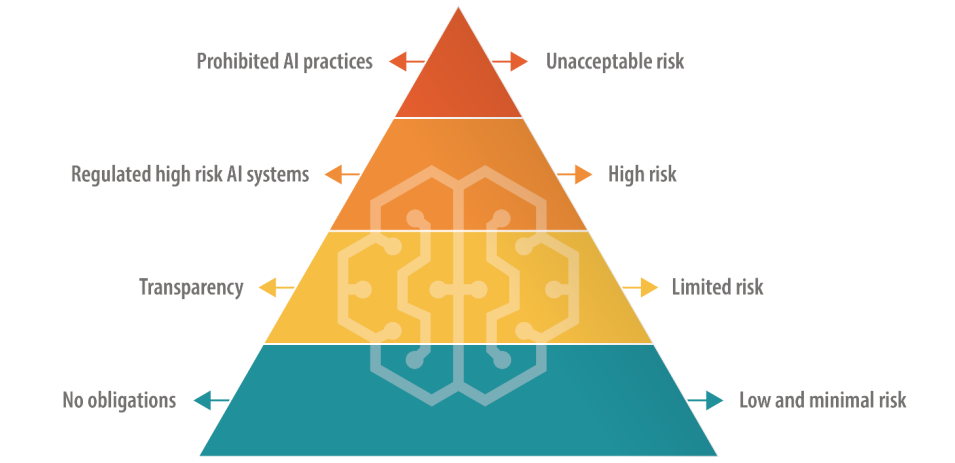
I det nåværende utkastet må selskaper som bruker høyrisiko-KI, opplyse om alt opphavsrettsbeskyttet materiale som inngår i opplæringsdata og loggaktivitet for å sikre at resultatene kan replikeres og spores. Dette kan bli kostbart og byrdefullt for mindre AI-selskaper.
Opphavsrettslig beskyttet materiale er fortsatt et springende punkt
OpenAI er langt fra en åpen bok når det gjelder opphavsrettslig beskyttet materiale i treningsdataene.
Den kunstige intelligensen har vist seg å gjenta linjer fra flere romaner, blant annet Harry Potter og Game of Thrones. Forskere foreslår Dette skyldes sannsynligvis at passasjer fra bøker ofte er offentlig tilgjengelige.
Det finnes mange verserende opphavsrettsrelaterte rettssaker mot OpenAI, Microsoft og skaperne bak bildegeneratorer som Midt på reisen. Akkurat nå vet vi rett og slett ikke omfanget av AIs bruk av opphavsrettslige data og metodene for å hente dem ut.
EU ønsker å endre dette ved å innføre regler for åpenhet, noe som kan endre hvordan kunstig intelligens læres opp, og dermed også ytelsen deres.
Vi lever kanskje i en uregulert AI-boble som er i ferd med å sprekke.



