

Uno studio dell'Università di Oxford ha sviluppato un metodo per verificare quando i modelli linguistici sono "insicuri" dei loro risultati e rischiano di avere allucinazioni.
Le "allucinazioni" dell'intelligenza artificiale si riferiscono a un fenomeno in cui i modelli linguistici di grandi dimensioni (LLM) generano risposte fluenti e plausibili che non sono veritiere o coerenti.
Le allucinazioni sono difficili, se non impossibili, da separare dai modelli di IA. Sviluppatori di IA come OpenAI, Google e Anthropic hanno tutti ammesso che le allucinazioni rimarranno probabilmente un sottoprodotto dell'interazione con l'IA.
Come spiega il dottor Sebastian Farquhar, uno degli autori dello studio, spiega in un post sul blogI laureati in Lettere sono molto capaci di dire la stessa cosa in molti modi diversi, il che può rendere difficile capire quando sono certi di una risposta e quando invece si stanno letteralmente inventando qualcosa".
Il Dizionario di Cambridge ha persino aggiunto un Definizione legata all'AI della parola nel 2023 e l'ha nominata "Parola dell'anno".
L'Università di Oxford studiopubblicato su Nature, cerca di capire come individuare quando è più probabile che si verifichino queste allucinazioni.
Introduce un concetto chiamato "entropia semantica", che misura l'incertezza dei risultati di un LLM a livello di significato piuttosto che di parole o frasi specifiche utilizzate.
Calcolando l'entropia semantica delle risposte di un LLM, i ricercatori possono stimare la fiducia del modello nei suoi risultati e identificare i casi in cui è probabile che abbia delle allucinazioni.
Spiegazione dell'entropia semantica nei LLM
L'entropia semantica, come definita dallo studio, misura l'incertezza o l'incoerenza del significato delle risposte di un LLM. Aiuta a individuare quando un LLM potrebbe avere delle allucinazioni o generare informazioni inaffidabili.
In termini più semplici, l'entropia semantica misura quanto sia "confuso" l'output di un LLM.
Il LLM fornirà probabilmente informazioni affidabili se il significato dei suoi risultati è strettamente correlato e coerente. Ma se i significati sono sparsi e incoerenti, è un segnale di allarme che il LLM potrebbe avere delle allucinazioni o generare informazioni imprecise.
Ecco come funziona:
- I ricercatori hanno sollecitato attivamente il LLM a generare diverse possibili risposte alla stessa domanda. Ciò si ottiene somministrando la domanda al LLM più volte, ogni volta con un seme casuale diverso o con una leggera variazione dell'input.
- L'entropia semantica esamina le risposte e raggruppa quelle che hanno lo stesso significato di fondo, anche se utilizzano parole o frasi diverse.
- Se il LLM è sicuro della risposta, le sue risposte dovrebbero avere significati simili, con un conseguente basso punteggio di entropia semantica. Ciò suggerisce che il LLM comprende in modo chiaro e coerente le informazioni.
- Tuttavia, se il LLM è incerto o confuso, le sue risposte avranno una più ampia varietà di significati, alcuni dei quali potrebbero essere incoerenti o non correlati alla domanda. Ciò si traduce in un punteggio di entropia semantica elevato, che indica che il LLM può avere allucinazioni o generare informazioni inaffidabili.
Per valutarne l'efficacia, i ricercatori hanno applicato l'entropia semantica a una serie di compiti di risposta alle domande. Si trattava di benchmark come domande di curiosità, comprensione della lettura, problemi con le parole e biografie.
In generale, l'entropia semantica ha superato i metodi esistenti per individuare quando è probabile che un LLM generi una risposta errata o incoerente.
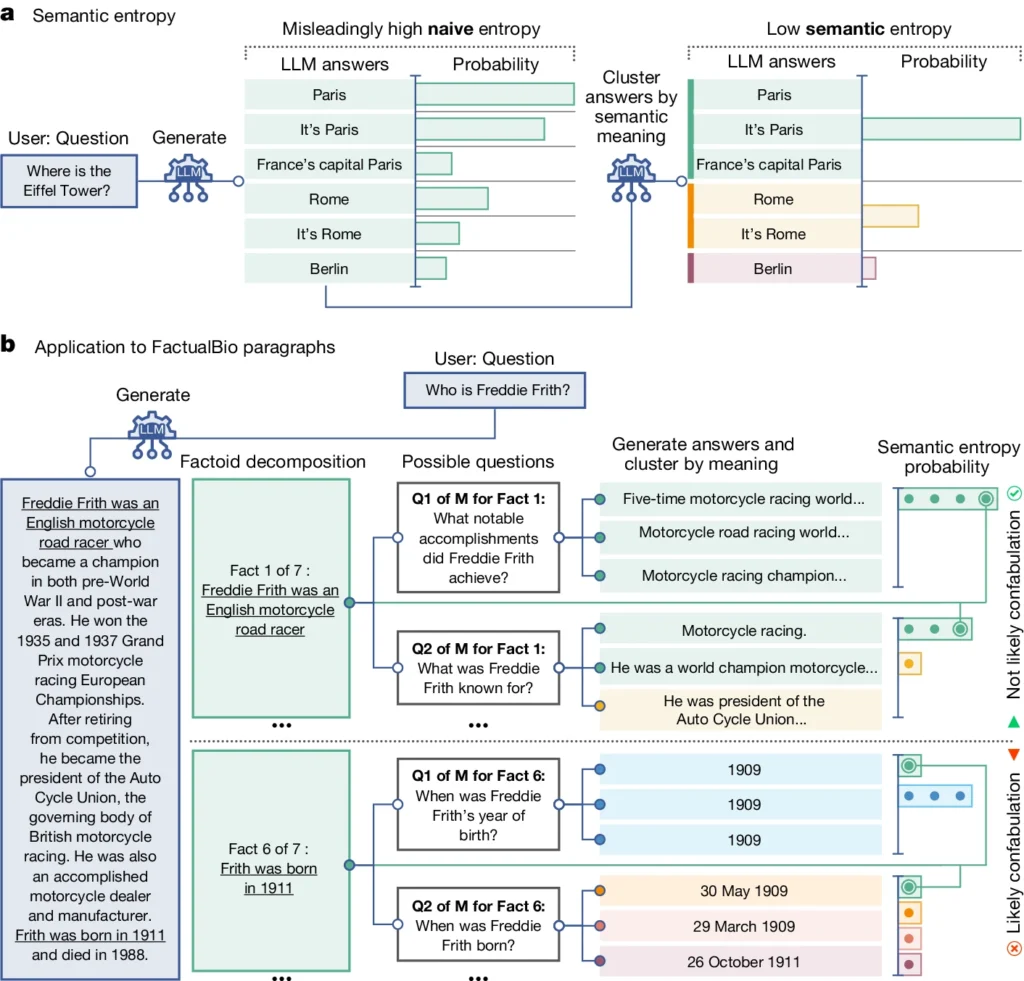
Nel diagramma qui sopra, si può notare come alcuni prompt spingano l'LLM a generare una risposta confabulata (imprecisa, allucinatoria). Ad esempio, produce un giorno e un mese di nascita per le domande in fondo al diagramma quando le informazioni necessarie per rispondere non sono state fornite nelle informazioni iniziali.
Implicazioni del rilevamento delle allucinazioni
Questo lavoro può aiutare a spiegare le allucinazioni e a rendere le LLM più affidabili e attendibili.
Fornendo un modo per rilevare quando un LLM è incerto o incline all'allucinazione, l'entropia semantica apre la strada all'impiego di questi strumenti di IA in settori ad alta concentrazione in cui l'accuratezza dei fatti è fondamentale, come la sanità, la legge e la finanza.
I risultati errati possono avere impatti potenzialmente catastrofici quando influenzano situazioni di grande importanza, come dimostrato da alcuni fallimento dell'attività di polizia predittiva e sistemi sanitari.
Tuttavia, è anche importante ricordare che le allucinazioni sono solo un tipo di errore che i LLM possono commettere.
Come spiega il dott. Farquhar, "se un LLM commette errori costanti, questo nuovo metodo non li coglie. I fallimenti più pericolosi dell'IA si verificano quando un sistema fa qualcosa di sbagliato ma è sicuro e sistematico. C'è ancora molto lavoro da fare".
Tuttavia, il metodo dell'entropia semantica del team di Oxford rappresenta un importante passo avanti nella nostra capacità di comprendere e mitigare i limiti dei modelli linguistici dell'IA.
Fornire un mezzo oggettivo per rilevarli ci avvicina a un futuro in cui potremo sfruttare il potenziale dell'IA assicurandoci che rimanga uno strumento affidabile e degno di fiducia al servizio dell'umanità.



