

L'era dell'IA presenta una complessa interazione tra tecnologia e atteggiamenti sociali.
La crescente sofisticazione dei sistemi di IA rende sempre più labili i confini tra esseri umani e macchine: la tecnologia dell'IA è separata da noi? In che misura l'IA eredita i difetti e le carenze umane, oltre alle competenze e alle conoscenze?
Forse si è tentati di immaginare l'IA come una tecnologia empirica, sottolineata dall'oggettività della matematica, del codice e dei calcoli.
Tuttavia, ci siamo resi conto che le decisioni prese dai sistemi di IA sono altamente soggettive e si basano sui dati a cui sono esposti, e gli esseri umani decidono come selezionare e assemblare questi dati.
Qui sta la sfida, perché i dati di addestramento dell'IA spesso incarnano i pregiudizi, i preconcetti e le discriminazioni che l'umanità sta combattendo.
Anche forme apparentemente sottili di pregiudizio inconscio possono essere amplificate dal processo di addestramento dei modelli, rivelandosi alla fine, tra le altre cose, sotto forma di corrispondenze facciali errate nelle forze dell'ordine, di crediti rifiutati, di diagnosi errate di malattie e di meccanismi di sicurezza alterati per i veicoli a guida autonoma.
I tentativi dell'umanità di prevenire la discriminazione in tutta la società rimangono un lavoro in corso, ma l'intelligenza artificiale sta guidando il processo decisionale critico in questo momento.
Possiamo lavorare abbastanza velocemente per sincronizzare l'IA con i valori moderni e prevenire decisioni e comportamenti distorti che cambiano la vita?
Svelare i pregiudizi nell'IA
Nell'ultimo decennio, i sistemi di intelligenza artificiale hanno dimostrato di rispecchiare i pregiudizi della società.
Questi sistemi non sono intrinsecamente distorti, ma assorbono i pregiudizi dei loro creatori e dei dati su cui vengono addestrati.
I sistemi di intelligenza artificiale, come gli esseri umani, imparano per esposizione. Il cervello umano è un indice apparentemente infinito di informazioni, una biblioteca con scaffali quasi illimitati dove immagazziniamo esperienze, conoscenze e ricordi.
Neuroscientifico studi dimostrano che il cervello non ha una "capacità massima" e continua a smistare e immagazzinare informazioni anche in età avanzata.
Sebbene sia tutt'altro che perfetto, il processo di apprendimento progressivo e iterativo del cervello ci aiuta ad adattarci a nuovi valori culturali e sociali, dalla concessione del voto alle donne all'accettazione di identità diverse, fino alla fine della schiavitù e di altre forme di pregiudizio consapevole.
WViviamo in un'epoca in cui gli strumenti di intelligenza artificiale vengono utilizzati per prendere decisioni critiche al posto del giudizio umano.
Molti modelli di apprendimento automatico (ML) imparano dai dati di addestramento che costituiscono la base del loro processo decisionale e non sono in grado di introdurre nuove informazioni con la stessa efficienza del cervello umano. Per questo motivo, spesso non riescono a produrre le decisioni aggiornate e al passo con i tempi per le quali siamo abituati a dipendere da loro.
Ad esempio, i modelli di intelligenza artificiale vengono utilizzati per identificare le corrispondenze facciali per le forze dell'ordine, analizzare i curriculum per le domande di lavoroe prendere decisioni critiche per la salute in ambito clinico.
Mentre la società continua a integrare l'IA nella nostra vita quotidiana, dobbiamo assicurarci che sia uguale e accurata per tutti.
Attualmente non è così.
Casi di studio sui pregiudizi dell'IA
Esistono numerosi esempi reali di pregiudizi, pregiudizi e discriminazioni legati all'IA.
In alcuni casi, gli impatti dei pregiudizi dell'IA cambiano la vita, mentre in altri rimangono sullo sfondo, influenzando sottilmente le decisioni.
1. Pregiudizio del set di dati del MIT
Un set di dati di addestramento del MIT costruito nel 2008, chiamato Piccole immagini conteneva circa 80.000.000 di immagini suddivise in circa 75.000 categorie.
Inizialmente è stato concepito per insegnare ai sistemi di intelligenza artificiale a riconoscere persone e oggetti all'interno delle immagini ed è diventato un popolare set di dati di riferimento per varie applicazioni di computer vision (CV).
A 2020 analisi di The Register ha riscontrato che molti Tiny Images conteneva etichette oscene, razziste e sessiste.
Antonio Torralba del MIT ha dichiarato che il laboratorio non era a conoscenza di queste etichette offensive e ha detto a The Register: "È chiaro che avremmo dovuto controllarle manualmente". Il MIT ha poi rilasciato una dichiarazione in cui afferma di aver rimosso il set di dati dal servizio.

Questa non è l'unica volta che un ex set di dati di riferimento è stato trovato pieno di problemi. Il Labeled Faces in the Wild (LFW), un set di dati di volti di celebrità ampiamente utilizzato nelle attività di riconoscimento facciale, è composto da 77,5% di maschi e 83,5% di persone con la pelle bianca.
Molti di questi dataset veterani sono entrati a far parte dei moderni modelli di IA, ma provengono da un'epoca di sviluppo dell'IA in cui l'attenzione era rivolta alla costruzione di sistemi che solo lavoro piuttosto che quelli appropriati per l'impiego in scenari reali.
Una volta che un sistema di IA è stato addestrato su un tale set di dati, non ha necessariamente lo stesso privilegio del cervello umano nel ricalibrarsi ai valori contemporanei.
Anche se i modelli possono essere aggiornati in modo iterativo, si tratta di un processo lento e imperfetto che non riesce a tenere il ritmo dello sviluppo umano.
2: Riconoscimento delle immagini: pregiudizio nei confronti degli individui con la pelle più scura
Nel 2019, il Il governo degli Stati Uniti ha trovato che i sistemi di riconoscimento facciale più performanti identificano erroneamente le persone di colore da 5 a 10 volte in più rispetto ai bianchi.
Non si tratta di una semplice anomalia statistica: ha implicazioni terribili nel mondo reale, che vanno da Google Photos che identifica le persone di colore come gorilla alle auto a guida autonoma che non riconoscono gli individui con la pelle più scura e li investono.
Inoltre, si è verificata un'ondata di arresti e detenzioni illegali che hanno riguardato false corrispondenze facciali, forse in modo più prolifico Nijeer Parks che è stato ingiustamente accusato di taccheggio e di reati stradali, nonostante si trovasse a 30 miglia di distanza dall'incidente. Parks ha poi trascorso 10 giorni in carcere e ha dovuto pagare migliaia di euro di spese legali.

L'autorevole studio del 2018, Sfumature di genereha esplorato ulteriormente i pregiudizi degli algoritmi. Lo studio ha analizzato gli algoritmi costruiti da IBM e Microsoft e ha riscontrato una scarsa accuratezza quando sono stati esposti a donne dalla pelle scura, con tassi di errore fino a 34% maggiori rispetto ai maschi dalla pelle più chiara.
Questo schema è risultato coerente tra 189 diversi algoritmi.
Il video qui sotto, realizzato da Joy Buolamwini, ricercatore principale dello studio, fornisce un'eccellente guida su come le prestazioni di riconoscimento facciale variano a seconda del colore della pelle.
3: Il progetto CLIP di OpenAI
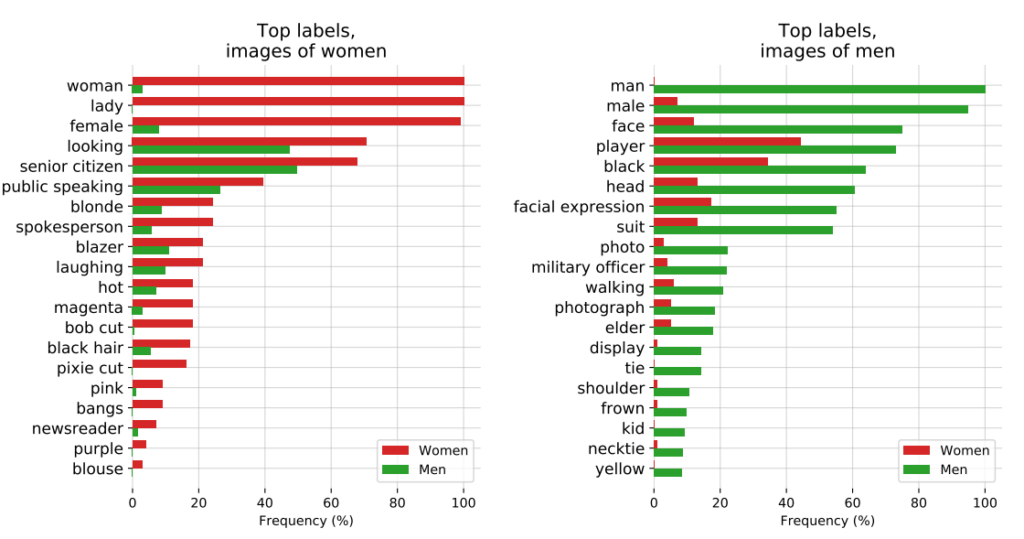
OpenAI Progetto CLIP, rilasciato nel 2021, progettato per abbinare le immagini al testo descrittivo, ha anche illustrato i problemi di pregiudizio in corso.
In un documento di revisione, i creatori di CLIP hanno evidenziato le loro preoccupazioni, affermando: "CLIP ha attribuito alcune etichette che descrivono occupazioni di alto livello in modo sproporzionato agli uomini, come 'dirigente' e 'medico'. Ciò è simile ai pregiudizi riscontrati in Google Cloud Vision (GCV) e indica differenze storiche di genere".
4: Applicazione della legge: la controversia PredPol
Un altro esempio di distorsione algoritmica ad alto rischio è PredPol, un algoritmo di polizia predittiva utilizzato da diversi dipartimenti di polizia negli Stati Uniti.
PredPol è stato addestrato sui dati storici della criminalità per prevedere i futuri punti caldi della criminalità.
Tuttavia, poiché questi dati riflettono intrinsecamente pratiche di polizia distorte, l'algoritmo è stato criticato per aver perpetuato il profiling razziale e aver preso di mira in modo sproporzionato i quartieri delle minoranze.
5: Bias in dermatologia AI
Nel settore sanitario, i potenziali rischi di pregiudizio dell'IA diventano ancora più evidenti.
Prendiamo l'esempio dei sistemi di intelligenza artificiale progettati per rilevare il cancro della pelle. Molti di questi sistemi sono addestrati su serie di dati composte per la maggior parte da individui con la pelle chiara.
A 2021 studio dell'Università di Oxford hanno analizzato 21 set di dati ad accesso libero alla ricerca di immagini di tumori della pelle. Hanno scoperto che dei 14 set di dati che hanno rivelato la loro origine geografica, 11 erano costituiti esclusivamente da immagini provenienti da Europa, Nord America e Oceania.
Solo 2.436 delle 106.950 immagini dei 21 database contenevano informazioni sul tipo di pelle. I ricercatori hanno notato che "solo 10 immagini erano di persone registrate come aventi la pelle marrone e una era di un individuo registrato come avente la pelle marrone scuro o nera".
In termini di dati sull'etnia, solo 1.585 immagini hanno fornito questa informazione. I ricercatori hanno scoperto che "nessuna immagine proveniva da individui di origine africana, afro-caraibica o sud-asiatica".
In combinazione con le origini geografiche dei set di dati, è stata riscontrata una massiccia sottorappresentazione delle immagini di lesioni cutanee provenienti da popolazioni con la pelle più scura", hanno concluso.
Se queste IA vengono impiegate in ambito clinico, i dati distorti creano un rischio molto concreto di diagnosi errate.
Discriminazione dei pregiudizi nei dataset di addestramento dell'IA: un prodotto dei loro creatori?
I dati di addestramento - più comunemente testo, parlato, immagini e video - forniscono al modello di apprendimento automatico (ML) supervisionato una base per l'apprendimento dei concetti.
I sistemi di intelligenza artificiale non sono altro che tele vuote all'inizio. Imparano e formano associazioni sulla base dei nostri dati, dipingendo essenzialmente un'immagine del mondo così come viene rappresentata dai loro set di dati di addestramento.
Apprendendo dai dati di addestramento, si spera che il modello applichi i concetti appresi a nuovi dati non visti.
Una volta implementati, alcuni modelli avanzati possono apprendere da nuovi dati, ma i dati di addestramento ne determinano ancora le prestazioni fondamentali.
La prima domanda a cui rispondere è: da dove provengono i dati? I dati raccolti da fonti non rappresentative, spesso omogenee e storicamente inique sono problematici.
Questo probabilmente si applica a una quantità significativa di dati online, compresi i dati di testo e di immagine estrapolati da fonti "aperte" o "pubbliche".
Concepito solo decenni fa, Internet non è una panacea per la conoscenza umana ed è tutt'altro che equo. Metà del mondo non usa Internet, né tantomeno vi contribuisce, il che significa che è fondamentalmente non rappresentativo della società e della cultura globale.
Inoltre, mentre gli sviluppatori di IA lavorano costantemente per garantire che i vantaggi della tecnologia non siano limitati al mondo anglofono, la maggior parte dei dati di addestramento (testo e parlato) è prodotta in inglese, il che significa che i contributi anglofoni guidano i risultati del modello.
I ricercatori di Anthropic hanno recentemente ha pubblicato un documento su questo stesso argomento, concludendo: "Se un modello linguistico rappresenta in modo sproporzionato alcune opinioni, rischia di imporre effetti potenzialmente indesiderabili, come la promozione di visioni del mondo egemoniche e l'omogeneizzazione delle prospettive e delle convinzioni delle persone".
In definitiva, sebbene i sistemi di IA operino sulla base dei principi "oggettivi" della matematica e della programmazione, essi esistono comunque all'interno di un contesto sociale umano profondamente soggettivo e sono plasmati da esso.
Possibili soluzioni al pregiudizio algoritmico
Se il problema fondamentale sono i dati, la soluzione per costruire modelli equi potrebbe sembrare semplice: basta rendere le serie di dati più equilibrate, giusto?
Non proprio. A Studio 2019 ha dimostrato che il bilanciamento dei set di dati è insufficiente, poiché gli algoritmi agiscono ancora in modo sproporzionato su caratteristiche protette come il genere e la razza.
Gli autori scrivono: "Sorprendentemente, dimostriamo che anche quando i dataset sono bilanciati in modo tale che ogni etichetta co-occorra in egual misura con ogni genere, i modelli appresi amplificano l'associazione tra etichette e genere, tanto quanto se i dati non fossero stati bilanciati!".
Propongono una tecnica di de-biasing in cui tali etichette vengono rimosse completamente dal set di dati. Altre tecniche includono l'aggiunta di perturbazioni e distorsioni casuali, che riducono l'attenzione dell'algoritmo su specifiche caratteristiche protette.
Inoltre, mentre la modifica dei metodi di addestramento e l'ottimizzazione dell'apprendimento automatico sono intrinseci alla produzione di risultati non distorti, i modelli avanzati sono suscettibili di cambiamenti o "derive", il che significa che le loro prestazioni non rimangono necessariamente costanti nel lungo periodo.
Un modello potrebbe essere totalmente imparziale al momento dell'implementazione, ma diventare successivamente parziale con l'aumento dell'esposizione a nuovi dati.
Il movimento per la trasparenza algoritmica
Nel suo libro provocatorio L'incomprensione artificiale: Come i computer fraintendono il mondoMeredith Broussard sostiene la necessità di una maggiore "trasparenza algoritmica" per esporre i sistemi di IA a più livelli di controllo continuo.
Ciò significa fornire informazioni chiare su come funziona il sistema, come è stato addestrato e su quali dati è stato addestrato.
Mentre le iniziative di trasparenza vengono facilmente assorbite nel panorama dell'IA open-source, i modelli proprietari come GPT, Bard e Claude di Anthropic sono "scatole nere" e solo i loro sviluppatori sanno esattamente come funzionano, e anche questo è oggetto di dibattito.
Il problema della "scatola nera" nell'IA significa che gli osservatori esterni vedono solo ciò che entra nel modello (input) e ciò che ne esce (output). I meccanismi interni sono completamente sconosciuti se non ai loro creatori, proprio come il cerchio magico protegge i segreti dei maghi. L'intelligenza artificiale tira fuori il coniglio dal cappello.
Il problema della scatola nera si è recentemente cristallizzato intorno a segnalazioni di Il potenziale calo di prestazioni del GPT-4. Gli utenti di GPT-4 sostengono che le capacità del modello sono diminuite rapidamente e, pur riconoscendo che ciò è vero, OpenAI non è stata assolutamente chiara sul perché di questo fenomeno. Questo pone la domanda: ma lo sanno?
Il dottor Sasha Luccioni, ricercatore nel campo dell'intelligenza artificiale, afferma che la mancanza di trasparenza di OpenAI è un problema che riguarda anche altri sviluppatori di modelli di intelligenza artificiale proprietari o chiusi. "Tutti i risultati dei modelli closed-source non sono riproducibili né verificabili e quindi, da un punto di vista scientifico, stiamo confrontando procioni e scoiattoli".
“Non spetta agli scienziati monitorare continuamente gli LLM impiegati. È compito dei creatori di modelli dare accesso ai modelli sottostanti, almeno a scopo di verifica", ha detto.
Luccioni ha sottolineato che gli sviluppatori di modelli di IA dovrebbero fornire i risultati grezzi di benchmark standard come SuperGLUE e WikiText e di benchmark parziali come BOLD e HONEST.
La battaglia contro i pregiudizi e i preconcetti dell'IA sarà probabilmente costante e richiederà un'attenzione e una ricerca continue per tenere sotto controllo i risultati dei modelli mentre l'IA e la società si evolvono insieme.
Anche se la regolamentazione imporrà forme di monitoraggio e di rendicontazione, ci sono poche soluzioni definitive al problema della distorsione algoritmica, e questa non è l'ultima volta che ne sentiremo parlare.



