

Elon Musk ha annunciato il lancio della versione beta del chatbot di xAI chiamato Grok e le prime statistiche ci danno un'idea di come si colloca rispetto ad altri modelli.
Il Chatbot Grok si basa sul modello di frontiera di xAI chiamato Grok-1, che l'azienda ha sviluppato negli ultimi quattro mesi. xAI non ha detto con quanti parametri è stato addestrato, ma ha fornito alcuni dati sul suo predecessore.
Grok-0, il prototipo del modello attuale, è stato addestrato su 33 miliardi di parametri, quindi possiamo probabilmente supporre che Grok-1 sia stato addestrato su almeno altrettanti parametri.
Non sembra molto, ma xAI sostiene che le prestazioni di Grok-0 "si avvicinano alle capacità di LLaMA 2 (70B) su benchmark LM standard" anche se ha utilizzato la metà delle risorse di addestramento.
In assenza di un dato parametrico, dobbiamo fidarci della parola dell'azienda che descrive Grok-1 come "all'avanguardia" e che è "significativamente più potente" di Grok-0.
Grok-1 è stato messo alla prova valutandolo su questi benchmark standard di apprendimento automatico:
- GSM8k: Problemi di matematica per la scuola media
- MMLU: Domande a scelta multipla multidisciplinari
- HumanEval: compito di completamento del codice Python
- MATH: Problemi di matematica per le scuole medie e superiori scritti in LaTeX.
Ecco una sintesi dei risultati.
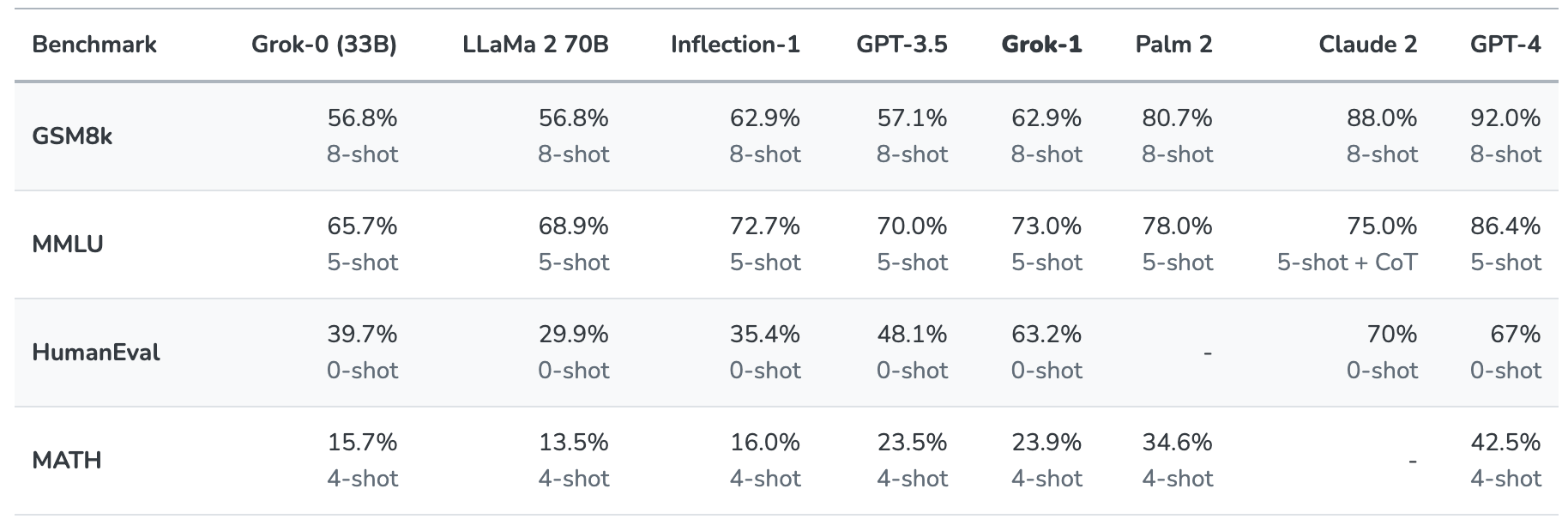
I risultati sono interessanti perché ci danno almeno un'idea di come Grok si confronta con altri modelli di frontiera.
xAI afferma che questi dati dimostrano che Grok-1 batte "tutti gli altri modelli della sua classe di calcolo" ed è stato battuto solo da modelli addestrati con una "quantità significativamente maggiore di dati di addestramento e risorse di calcolo".
GPT-3.5 ha 175 miliardi di parametri, quindi possiamo supporre che Grok-1 ne abbia meno, ma probabilmente più dei 33 miliardi del suo prototipo.
Il chatbot Grok è destinato a svolgere compiti come la risposta a domande, il recupero di informazioni, la scrittura creativa e l'assistenza alla codifica. È più probabile che venga utilizzato per interazioni più brevi rispetto a casi d'uso di tipo super prompt, a causa della sua finestra contestuale più piccola.
Con una lunghezza del contesto di 8.192 Grok-1 ha solo la metà del contesto che ha GPT-3.5. Questo indica che xAI ha probabilmente voluto che Grok-1 scambiasse un contesto più lungo per una migliore efficienza. Questo indica che xAI probabilmente intendeva che Grok-1 scambiasse un contesto più lungo con una migliore efficienza.
L'azienda afferma che alcune delle sue ricerche attuali si concentrano sulla "comprensione e il recupero di contesti lunghi", quindi la prossima iterazione di Grok potrebbe avere una finestra di contesto più ampia.
L'esatto set di dati utilizzato per addestrare Grok-1 non è chiaro, ma quasi certamente includeva i vostri tweet su X, e il chatbot Grok ha accesso in tempo reale anche a Internet.
Dovremo attendere ulteriori riscontri da parte dei beta tester per avere un'idea reale della bontà del modello.
Grok ci aiuterà a svelare i misteri della vita, dell'universo e di tutto quanto? Forse non ancora, ma è un inizio divertente.



