

Nvidia ha annunciato un nuovo software open source che, a suo dire, aumenterà le prestazioni di inferenza sulle sue GPU H100.
Gran parte dell'attuale domanda di GPU Nvidia riguarda la potenza di calcolo per l'addestramento di nuovi modelli. Ma una volta addestrati, questi modelli devono essere utilizzati. L'inferenza nell'IA si riferisce alla capacità di un LLM come ChatGPT di trarre conclusioni o fare previsioni dai dati su cui è stato addestrato e di generare output.
Quando si cerca di usare ChatGPT e appare un messaggio che dice che i suoi server sono sotto sforzo, è perché l'hardware di calcolo sta lottando per tenere il passo con la domanda di inferenza.
Nvidia afferma che il suo nuovo software, TensorRT-LLM, può rendere l'hardware esistente molto più veloce e più efficiente dal punto di vista energetico.
Il software include versioni ottimizzate dei modelli più diffusi, tra cui Meta Llama 2, OpenAI GPT-2 e GPT-3, Falcon, Mosaic MPT e BLOOM.
Utilizza alcune tecniche intelligenti come il batching più efficiente dei compiti di inferenza e le tecniche di quantizzazione per ottenere un aumento delle prestazioni.
I LLM utilizzano generalmente valori in virgola mobile a 16 bit per rappresentare i pesi e le attivazioni. La quantizzazione prende questi valori e li riduce a valori in virgola mobile a 8 bit durante l'inferenza. La maggior parte dei modelli riesce a mantenere la propria accuratezza con questa precisione ridotta.
Le aziende che dispongono di infrastrutture di calcolo basate sulle GPU H100 di Nvidia possono aspettarsi un enorme miglioramento delle prestazioni di inferenza senza dover spendere un centesimo utilizzando TensorRT-LLM.
Nvidia ha utilizzato un esempio di esecuzione di un piccolo modello open source, GPT-J 6, per riassumere gli articoli del dataset CNN/Daily Mail. Il suo vecchio chip A100 viene utilizzato come velocità di base e poi confrontato con l'H100 senza e con TensorRT-LLM.
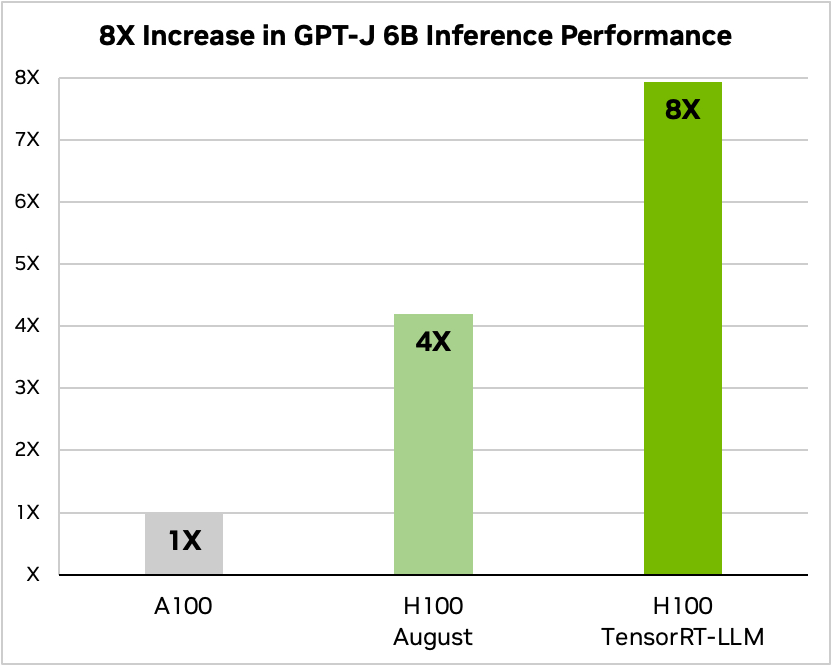
Fonte: Nvidia
Ed ecco un confronto con Meta's Llama 2
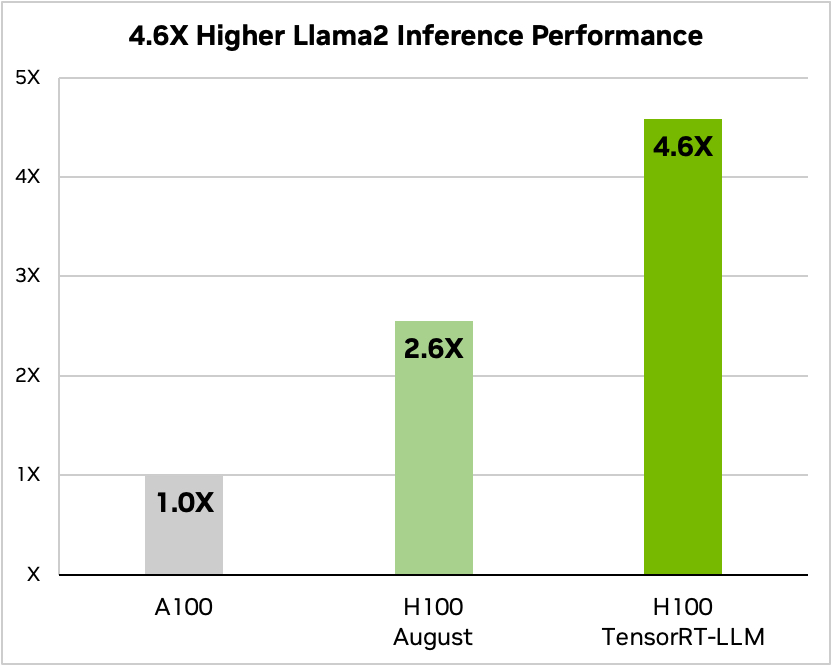
Fonte: Nvidia
Nvidia ha dichiarato che i suoi test hanno dimostrato che, a seconda del modello, un H100 con TensorRT-LLM consuma da 3,2 a 5,6 volte meno energia di un A100 durante l'inferenza.
Se si eseguono modelli di intelligenza artificiale su hardware H100, ciò significa che non solo le prestazioni di inferenza saranno quasi raddoppiate, ma anche che la bolletta energetica sarà molto più bassa una volta installato questo software.
TensorRT-LLM sarà disponibile anche per il sistema Nvidia Superchip Grace Hopper ma l'azienda non ha rilasciato dati sulle prestazioni della GH200 con il nuovo software.
Il nuovo software non era ancora pronto quando Nvidia ha sottoposto il suo Superchip GH200 ai test di benchmarking delle prestazioni MLPerf AI, standard del settore. I risultati hanno mostrato che il GH200 ha ottenuto prestazioni fino a 17% migliori rispetto a un H100 SXM a chip singolo.
Se Nvidia riuscirà a ottenere anche solo un modesto incremento delle prestazioni di inferenza utilizzando TensorRT-LLM con il GH200, metterà l'azienda davanti ai suoi più vicini rivali. Essere un rappresentante di Nvidia deve essere il lavoro più facile del mondo in questo momento.



