

Un nuovo studio dimostra che l'addestramento dei generatori di immagini AI con immagini generate dall'AI alla fine porta a una riduzione significativa della qualità dell'output.
Baraniuk e il suo team hanno dimostrato come questo ciclo di formazione problematico influisca sulle IA generative, tra cui StyleGAN e i modelli di diffusione. Questi sono tra i modelli utilizzati per i generatori di immagini AI come Stable Diffusion, DALL-E e MidJourney.
Nel loro esperimentoIl team ha addestrato le IA su immagini generate dall'IA o reali. 70.000 volti umani reali provenienti da Flickr.
Quando ogni intelligenza artificiale è stata addestrata sulle proprie immagini generate dall'intelligenza artificiale, i risultati del generatore di immagini StyleGAN hanno iniziato a mostrare modelli visivi distorti e ondulati, mentre i risultati del generatore di immagini a diffusione sono diventati più sfocati.
In entrambi i casi, l'addestramento delle IA su immagini generate dalle IA ha comportato una perdita di qualità.
Uno dei studio Gli autori, Richard Baraniuk della Rice University in Texas, avvertono: "Ci sarà un pendio scivoloso verso l'uso di dati sintetici, sia intenzionalmente che inconsapevolmente".
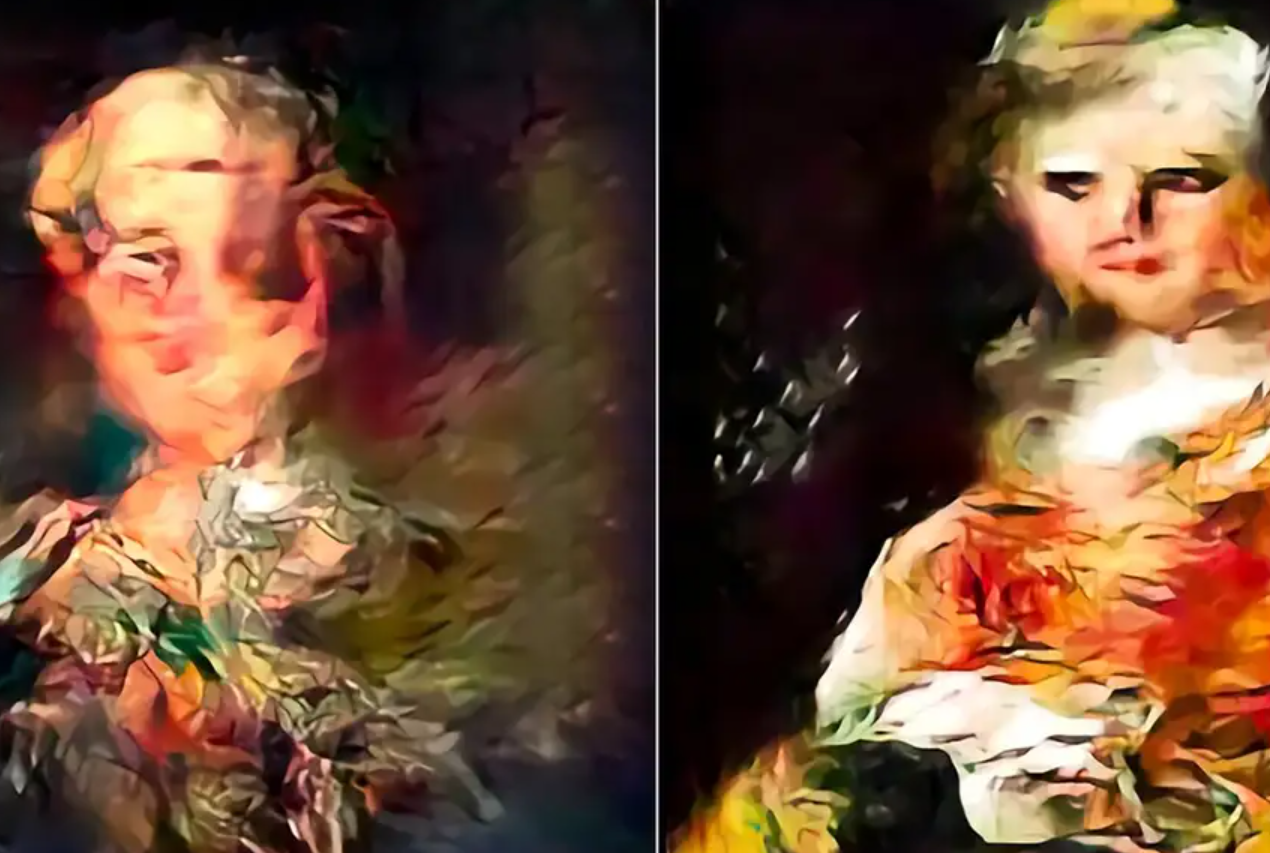
Sebbene il calo della qualità delle immagini sia stato ridotto selezionando per l'addestramento immagini generate dall'intelligenza artificiale di qualità superiore, ciò ha comportato una perdita di diversità delle immagini.
I ricercatori hanno anche provato a incorporare un set fisso di immagini reali in set di allenamento che includevano principalmente immagini generate dall'intelligenza artificiale, un metodo talvolta utilizzato per integrare piccoli set di allenamento.
Tuttavia, questo ha solo ritardato il declino della qualità delle immagini: sembra inevitabile che più dati generati dall'intelligenza artificiale entrano nelle serie di dati di addestramento, peggiore sarà il risultato. È solo una questione di tempo.
Sono stati ottenuti risultati ragionevoli quando ogni IA è stata addestrata su un mix di immagini generate dall'IA e su un insieme di immagini autentiche in continua evoluzione. Ciò ha contribuito a mantenere la qualità e la diversità delle immagini.
È difficile trovare un equilibrio tra quantità e qualità: le immagini sintetiche sono potenzialmente illimitate rispetto a quelle reali, ma il loro utilizzo ha un costo.
Le IA stanno esaurendo i dati
Le IA sono affamate di dati, ma i dati autentici e di alta qualità sono una risorsa limitata.
I risultati di questa ricerca fanno eco studi simili per la generazione di testidove i risultati dell'IA tendono a soffrire quando i modelli vengono addestrati su testi generati dall'IA.
I ricercatori sottolineano che le organizzazioni più piccole, con capacità limitate di raccogliere dati autentici, devono affrontare le maggiori difficoltà nel filtrare le immagini generate dall'IA dai loro set di dati.
Inoltre, il problema è aggravato dal fatto che Internet è inondato di contenuti generati dall'IA, il che rende incredibilmente difficile determinare il tipo di dati su cui i modelli sono stati addestrati.
Sina Alemohammad, della Rice University, suggerisce che lo sviluppo di filigrane per identificare le immagini generate dall'IA potrebbe essere d'aiuto, ma avverte che le filigrane nascoste e trascurate possono degradare la qualità delle immagini generate dall'IA.
Alemohammad conclude: "Siete dannati se lo fate e dannati se non lo fate. Ma è sicuramente meglio filigranare l'immagine che non farlo".
Le conseguenze a lungo termine del consumo dell'IA sono molto dibattute, ma al momento gli sviluppatori di IA devono trovare soluzioni per garantire la qualità dei loro modelli.



