

Les critères d'évaluation ont du mal à suivre l'évolution des capacités des modèles d'IA et le projet "Humanity's Last Exam" souhaite que vous l'aidiez à y remédier.
Ce projet est le fruit d'une collaboration entre le Centre pour la sécurité de l'IA (CAIS) et l'entreprise de données sur l'IA Scale AI. Le projet vise à mesurer à quel point nous sommes proches d'obtenir des systèmes d'IA de niveau expert, ce que l'on appelle "l'intelligence artificielle". critères de référence existants ne sont pas capables de le faire.
OpenAI et CAIS ont mis au point le célèbre test MMLU (Massive Multitask Language Understanding) en 2021. À l'époque, selon le CAIS, "les systèmes d'IA n'étaient pas plus performants que les systèmes aléatoires".
Les performances impressionnantes du modèle o1 d'OpenAI ont "détruit les repères de raisonnement les plus populaires", selon Dan Hendrycks, directeur exécutif de CAIS.
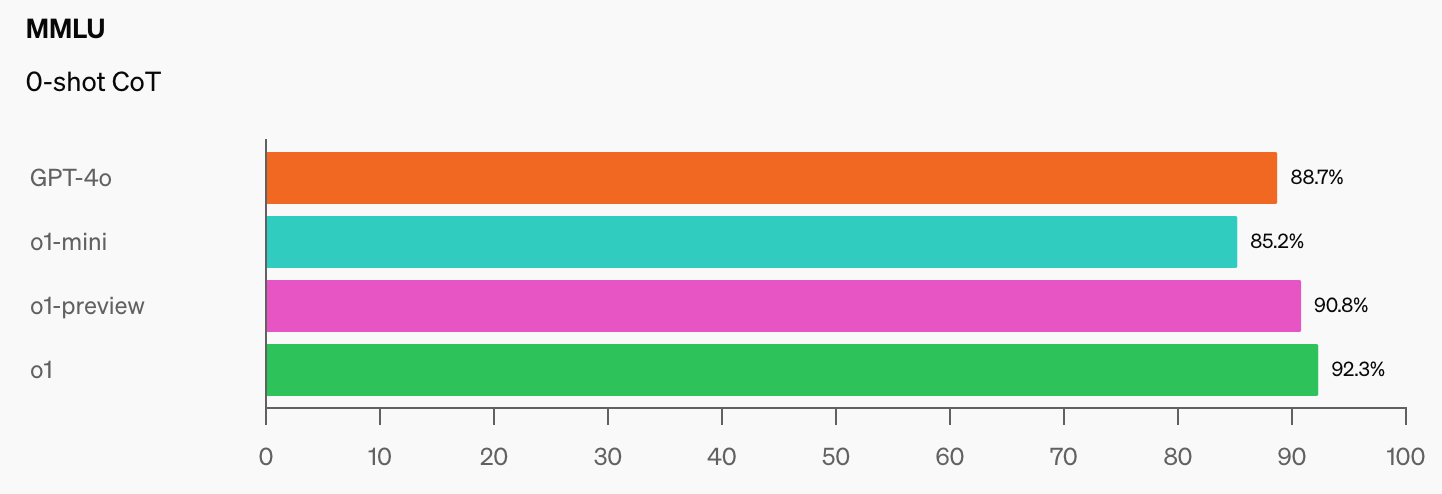
Une fois que les modèles d'IA auront atteint 100% sur le MMLU, comment les mesurerons-nous ? Selon le CAIS, "les tests existants sont devenus trop faciles et nous ne pouvons plus suivre correctement les développements de l'IA, ni savoir à quel point ils sont loin d'atteindre le niveau d'expert".
Quand on voit le bond en avant des scores de référence qu'o1 a ajouté aux chiffres déjà impressionnants de GPT-4o, on se dit qu'il ne faudra pas attendre longtemps avant qu'un modèle d'intelligence artificielle ne s'impose à la MMLU.
C'est objectivement vrai. pic.twitter.com/gorahh86ee
- Ethan Mollick (@emollick) 17 septembre 2024
Le dernier examen de l'humanité demande aux gens de soumettre des questions qui les surprendraient vraiment si un modèle d'IA leur donnait la bonne réponse. Il s'agit de questions de niveau doctoral, et non de questions du type "combien de R dans fraise" qui font trébucher certains modèles.
M. Scale a expliqué que "les tests existants devenant trop faciles, nous perdons la capacité de faire la distinction entre les systèmes d'IA qui peuvent réussir des examens de premier cycle et ceux qui peuvent réellement contribuer à la recherche de pointe et à la résolution de problèmes".
Si vous avez une question originale qui pourrait dérouter un modèle d'IA avancé, vous pourriez voir votre nom ajouté en tant que co-auteur de l'article du projet et partager une cagnotte de $500 000 qui sera attribuée aux meilleures questions.
Pour vous donner une idée du niveau visé par le projet, Scale a expliqué que "si un étudiant de premier cycle sélectionné au hasard peut comprendre ce qui est demandé, c'est probablement trop facile pour les LLM d'aujourd'hui et de demain".
Il y a quelques restrictions intéressantes sur les types de questions qui peuvent être soumises. Ils ne veulent rien qui soit lié aux armes chimiques, biologiques, radiologiques ou nucléaires, ni aux cyberarmes utilisées pour attaquer les infrastructures critiques.
Si vous pensez avoir une question qui répond aux critères, vous pouvez la soumettre. ici.



