

Une étude de l'Université d'Oxford a mis au point un moyen de vérifier si les modèles linguistiques sont "incertains" de leurs résultats et risquent d'halluciner.
Les "hallucinations" de l'IA désignent un phénomène dans lequel de grands modèles de langage (LLM) génèrent des réponses fluides et plausibles qui ne sont ni vraies ni cohérentes.
Les hallucinations sont difficiles - voire impossibles - à séparer des modèles d'IA. Des développeurs d'IA comme OpenAI, Google et Anthropic ont tous admis que les hallucinations resteront probablement un sous-produit de l'interaction avec l'IA.
Comme l'explique le Dr Sebastian Farquhar, l'un des auteurs de l'étude, explique dans un billet de blogLes LLM sont tout à fait capables de dire la même chose de différentes manières, ce qui peut rendre difficile de déterminer s'ils sont certains d'une réponse ou s'ils sont littéralement en train d'inventer quelque chose.
Le dictionnaire de Cambridge a même ajouté un Définition du mot lié à l'IA en 2023 et l'a nommé "mot de l'année".
Cette université d'Oxford étudepublié dans Nature, cherche à répondre à la question de savoir comment nous pouvons détecter le moment où ces hallucinations sont le plus susceptibles de se produire.
Il introduit un concept appelé "entropie sémantique", qui mesure l'incertitude des résultats d'un MLD au niveau de la signification plutôt qu'au niveau des mots ou phrases spécifiques utilisés.
En calculant l'entropie sémantique des réponses d'un LLM, les chercheurs peuvent estimer la confiance du modèle dans ses résultats et identifier les cas où il est susceptible d'halluciner.
L'entropie sémantique dans les LLM expliquée
L'entropie sémantique, telle que définie par l'étude, mesure l'incertitude ou l'incohérence de la signification des réponses d'un MFR. Il permet de détecter si un LLM a des hallucinations ou s'il génère des informations peu fiables.
En termes plus simples, l'entropie sémantique mesure le degré de "confusion" des résultats d'un LLM.
Le LLM fournira probablement des informations fiables si la signification de ses résultats est étroitement liée et cohérente. Mais si les significations sont dispersées et incohérentes, il s'agit d'un signal d'alarme indiquant que le LLM pourrait avoir des hallucinations ou générer des informations inexactes.
Voici comment cela fonctionne :
- Les chercheurs ont activement incité le LLM à générer plusieurs réponses possibles à la même question. Pour ce faire, ils ont soumis la question au LLM plusieurs fois, chaque fois avec une graine aléatoire différente ou une légère variation de l'entrée.
- L'entropie sémantique examine les réponses et regroupe celles qui ont la même signification sous-jacente, même si elles utilisent des mots ou des formulations différents.
- Si le LLM est sûr de la réponse, ses réponses devraient avoir des significations similaires, ce qui se traduit par un faible score d'entropie sémantique. Cela suggère que le LLM comprend clairement et de manière cohérente les informations.
- Cependant, si le LLM est incertain ou confus, ses réponses auront une plus grande variété de significations, dont certaines peuvent être incohérentes ou sans rapport avec la question. Il en résulte un score d'entropie sémantique élevé, indiquant que le LLM peut halluciner ou générer des informations peu fiables.
Pour évaluer son efficacité, les chercheurs ont appliqué l'entropie sémantique à un ensemble varié de tâches de réponse à des questions. Il s'agissait de critères de référence tels que des questions anecdotiques, des exercices de compréhension de lecture, des problèmes de mots et des biographies.
Dans l'ensemble, l'entropie sémantique a surpassé les méthodes existantes pour détecter quand un LLM était susceptible de générer une réponse incorrecte ou incohérente.
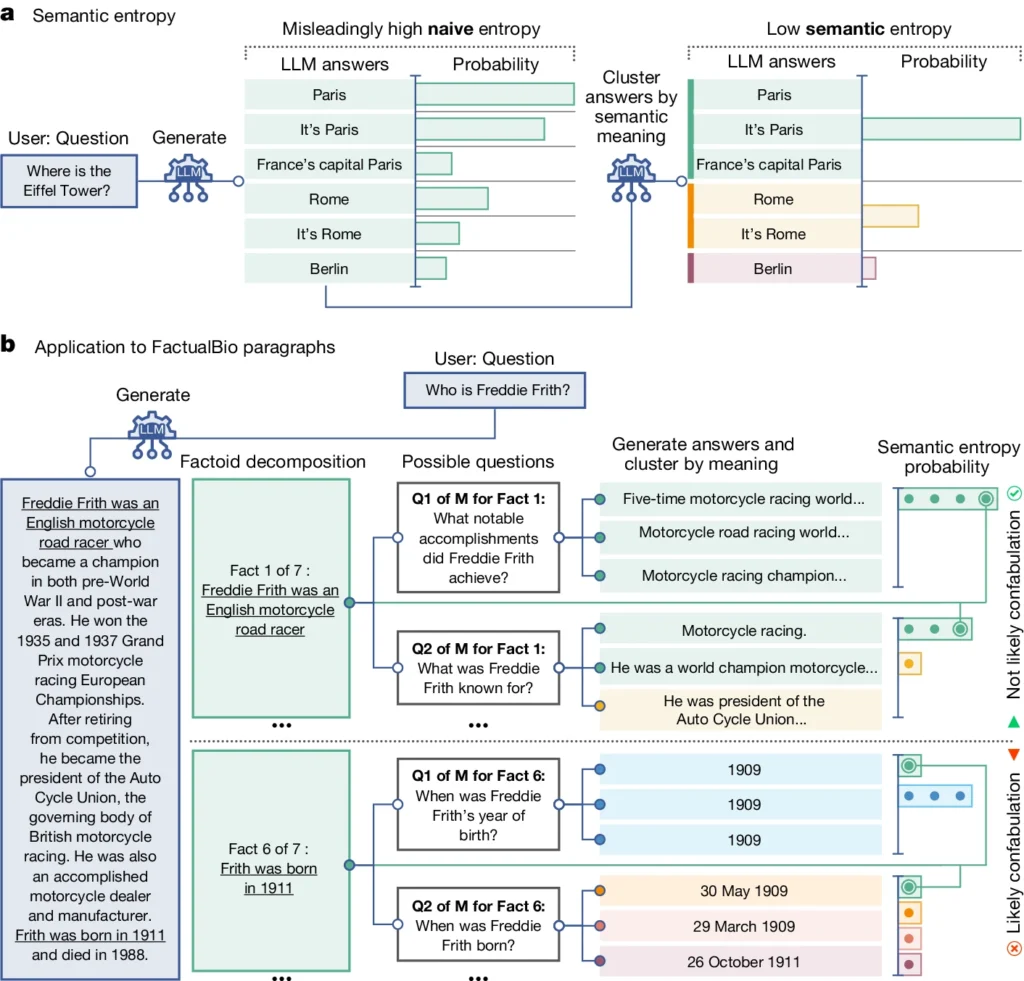
Dans le diagramme ci-dessus, vous pouvez voir comment certaines questions poussent le LLM à produire une réponse confabulée (inexacte, hallucinatoire). Par exemple, il produit un jour et un mois de naissance pour les questions en bas du diagramme alors que les informations requises pour y répondre n'ont pas été fournies dans les informations initiales.
Implications de la détection des hallucinations
Ces travaux peuvent contribuer à expliquer les hallucinations et à rendre les LLM plus fiables et dignes de confiance.
En permettant de détecter si un LLM est incertain ou sujet à des hallucinations, l'entropie sémantique ouvre la voie au déploiement de ces outils d'IA dans des domaines à fort enjeu où l'exactitude des faits est essentielle, comme les soins de santé, le droit et la finance.
Des résultats erronés peuvent avoir des conséquences potentiellement catastrophiques lorsqu'ils influencent des situations à fort enjeu, comme l'ont montré certains cas d'erreurs de calcul. l'échec de la police prédictive et systèmes de santé.
Cependant, il est également important de se rappeler que les hallucinations ne sont qu'un type d'erreur que les MFR peuvent commettre.
Comme l'explique M. Farquhar, "si un LLM commet des erreurs systématiques, cette nouvelle méthode ne les détectera pas". Les échecs les plus dangereux de l'IA surviennent lorsqu'un système fait quelque chose de mal mais qu'il est confiant et systématique. Il y a encore beaucoup de travail à faire".
Néanmoins, la méthode d'entropie sémantique de l'équipe d'Oxford représente une avancée majeure dans notre capacité à comprendre et à atténuer les limites des modèles linguistiques de l'IA.
La mise en place d'un moyen objectif de les détecter nous rapproche d'un avenir où nous pourrons exploiter le potentiel de l'IA tout en veillant à ce qu'elle reste un outil fiable et digne de confiance au service de l'humanité.



