

L'ère de l'IA présente une interaction complexe entre la technologie et les attitudes sociétales.
La sophistication croissante des systèmes d'IA brouille les frontières entre les humains et les machines - la technologie de l'IA est-elle distincte de nous-mêmes ? Dans quelle mesure l'IA hérite-t-elle des défauts et des lacunes de l'homme, ainsi que de ses compétences et de ses connaissances ?
Il est peut-être tentant d'imaginer l'IA comme une technologie empirique, soulignée par l'objectivité des mathématiques, du code et des calculs.
Cependant, nous nous sommes rendu compte que les décisions prises par les systèmes d'IA sont hautement subjectives et basées sur les données auxquelles ils sont exposés - et ce sont les humains qui décident de la manière de sélectionner et d'assembler ces données.
C'est là que réside le défi, car les données d'apprentissage de l'IA incarnent souvent les préjugés et la discrimination que l'humanité doit combattre.
Même des formes apparemment subtiles de préjugés inconscients peuvent être amplifiées par le processus de formation des modèles, se révélant finalement sous la forme de correspondances faciales incorrectes dans le cadre de l'application de la loi, de crédits refusés, de diagnostics erronés de maladies et de mécanismes de sécurité altérés pour les véhicules autopilotés, entre autres.
Les tentatives de l'humanité pour prévenir les discriminations dans l'ensemble de la société sont encore en cours, mais l'IA est aujourd'hui à l'origine de décisions cruciales.
Pouvons-nous travailler suffisamment vite pour synchroniser l'IA avec les valeurs modernes et empêcher les décisions et les comportements biaisés qui changent la vie ?
Démêler les biais de l'IA
Au cours de la dernière décennie, les systèmes d'IA se sont avérés refléter les préjugés de la société.
Ces systèmes ne sont pas intrinsèquement biaisés - ils absorbent plutôt les biais de leurs créateurs et des données sur lesquelles ils sont formés.
Les systèmes d'IA, comme les humains, apprennent par exposition. Le cerveau humain est un index d'informations apparemment sans fin - une bibliothèque aux étagères quasi illimitées où nous stockons nos expériences, nos connaissances et nos souvenirs.
Neurosciences études montrent que le cerveau n'a pas vraiment de "capacité maximale" et qu'il continue à trier et à stocker des informations jusqu'à un âge avancé.
Bien qu'il soit loin d'être parfait, le processus d'apprentissage progressif et itératif du cerveau nous aide à nous adapter à de nouvelles valeurs culturelles et sociétales, qu'il s'agisse du droit de vote des femmes, de l'acceptation d'identités diverses ou de la fin de l'esclavage et d'autres formes de préjugés conscients.
Wous vivons désormais dans une ère où les outils d'IA sont utilisés pour prendre des décisions critiques à la place du jugement humain.
De nombreux modèles d'apprentissage automatique apprennent à partir de données d'entraînement qui constituent la base de leur prise de décision et ne peuvent pas intégrer de nouvelles informations aussi efficacement que le cerveau humain. C'est pourquoi ils ne parviennent souvent pas à produire les décisions actualisées, à la minute près, pour lesquelles nous avons fini par compter sur eux.
Par exemple, les modèles d'IA sont utilisés pour identifier les correspondances faciales à des fins d'application de la loi, analyser les curriculum vitae pour les demandes d'emploiet prendre des décisions critiques en matière de santé dans un contexte clinique.
Alors que la société continue d'intégrer l'IA dans notre vie quotidienne, nous devons veiller à ce qu'elle soit égale et précise pour tout le monde.
Actuellement, ce n'est pas le cas.
Études de cas sur la partialité de l'IA
Il existe de nombreux exemples concrets de partialité, de préjugés et de discrimination liés à l'IA.
Dans certains cas, les conséquences des biais de l'IA changent la vie, tandis que dans d'autres, elles restent en arrière-plan, influençant subtilement les décisions.
1. Le biais de l'ensemble de données du MIT
Un ensemble de données de formation du MIT construit en 2008, appelé Petites images contenait environ 80 000 000 d'images réparties dans quelque 75 000 catégories.
Conçu à l'origine pour apprendre aux systèmes d'intelligence artificielle à reconnaître des personnes et des objets dans des images, il est devenu un ensemble de données de référence populaire pour diverses applications dans le domaine de la vision par ordinateur (VA).
A 2020 analyse par The Register a constaté que de nombreux Tiny Images contenait des étiquettes obscènes, racistes et sexistes.
Antonio Torralba, du MIT, a déclaré que le laboratoire n'était pas au courant de ces étiquettes offensantes et a déclaré à The Register : "Il est clair que nous aurions dû les filtrer manuellement." Le MIT a ensuite publié une déclaration indiquant qu'il avait retiré l'ensemble de données du service.

Ce n'est pas la seule fois qu'un ancien ensemble de données de référence s'est révélé truffé de problèmes. Le Labeled Faces in the Wild (LFW), un ensemble de données de visages de célébrités largement utilisé dans les tâches de reconnaissance faciale, se compose de 77,5% d'hommes et de 83,5% d'individus à la peau blanche.
Bon nombre de ces ensembles de données anciens ont trouvé leur place dans les modèles d'IA modernes, mais ils sont issus d'une ère de développement de l'IA où l'accent était mis sur la construction de systèmes qui travailler simplement plutôt que ceux qui sont appropriés pour être déployés dans des scénarios réels.
Une fois qu'un système d'IA est formé sur un tel ensemble de données, il n'a pas nécessairement le même privilège que le cerveau humain pour se recalibrer sur les valeurs contemporaines.
Bien que les modèles puissent être mis à jour de manière itérative, il s'agit d'un processus lent et imparfait qui ne peut suivre le rythme du développement humain.
2 : Reconnaissance d'images : préjugés contre les personnes à la peau plus foncée
En 2019, le Le gouvernement américain a trouvé que les systèmes de reconnaissance faciale les plus performants identifient mal les personnes noires 5 à 10 fois plus que les personnes blanches.
Il ne s'agit pas d'une simple anomalie statistique : elle a de graves conséquences dans le monde réel, allant de Google Photos qui identifie les personnes noires comme des gorilles aux voitures autonomes qui ne reconnaissent pas les personnes à la peau plus foncée et leur foncent dessus.
En outre, il y a eu une vague d'arrestations et d'emprisonnements injustifiés impliquant de fausses correspondances faciales, dont la plus fréquente est sans doute la suivante Nijeer Parks qui a été accusé à tort de vol à l'étalage et de délits routiers, alors qu'il se trouvait à 30 miles de l'incident. Parks a ensuite passé 10 jours en prison et a dû débourser des milliers de dollars en frais d'avocat.

L'étude influente de 2018, Nuances de genreL'étude de l'Institut de recherche en sciences sociales et humaines de l'Union européenne (IRIS), a exploré plus avant les biais algorithmiques. L'étude a analysé des algorithmes construits par IBM et Microsoft et a constaté une faible précision lorsqu'ils étaient exposés à des femmes à la peau plus foncée, avec des taux d'erreur jusqu'à 34% plus élevés que pour les hommes à la peau plus claire.
Cette tendance s'est avérée cohérente pour 189 algorithmes différents.
La vidéo ci-dessous, réalisée par Joy Buolamwini, chercheuse principale de l'étude, fournit un excellent guide sur la manière dont les performances de reconnaissance faciale varient en fonction de la couleur de la peau.
3 : Le projet CLIP de l'OpenAI
L'équipe d'OpenAI Projet CLIPL'enquête sur les images, publiée en 2021 et conçue pour associer des images à un texte descriptif, a également illustré les problèmes persistants de partialité.
Dans un document d'audit, les créateurs de CLIP ont fait part de leurs préoccupations en déclarant : "CLIP a attaché certaines étiquettes qui décrivent des professions de haut niveau de manière disproportionnée pour les hommes, telles que "cadre" et "médecin". Cela est similaire aux biais trouvés dans Google Cloud Vision (GCV) et indique des différences historiques liées au genre."
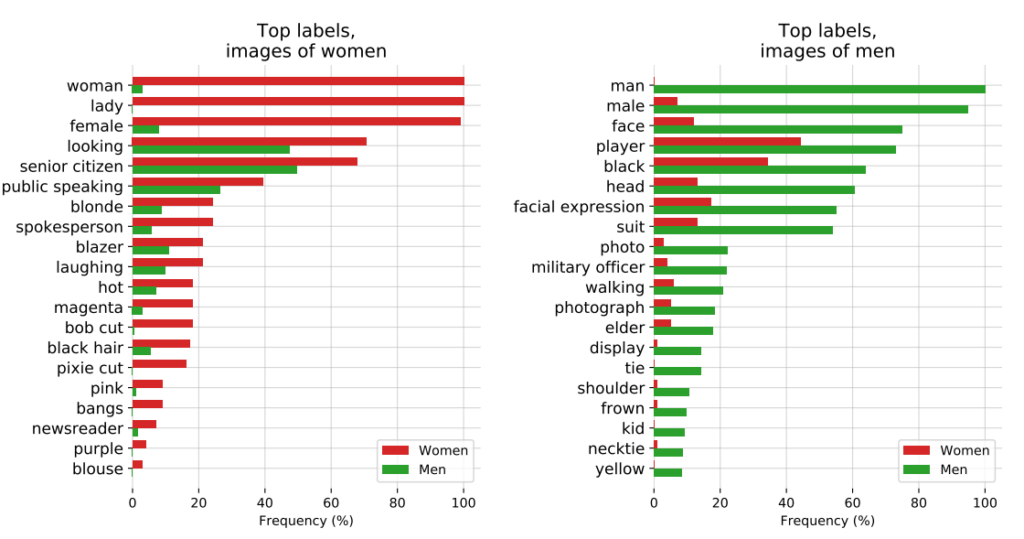
4 : Application de la loi : la controverse PredPol
Un autre exemple de partialité algorithmique aux enjeux importants est celui de la PredPolun algorithme de police prédictive utilisé par divers services de police aux États-Unis.
PredPol a été formé à partir de données historiques sur la criminalité afin de prédire les futurs points chauds de la criminalité.
Cependant, comme ces données reflètent intrinsèquement des pratiques policières biaisées, l'algorithme a été critiqué pour perpétuer le profilage racial et cibler de manière disproportionnée les quartiers minoritaires.
5 : Biais dans l'IA en dermatologie
Dans le domaine de la santé, les risques potentiels de biais liés à l'IA sont encore plus marqués.
Prenons l'exemple des systèmes d'IA conçus pour détecter les cancers de la peau. Nombre de ces systèmes sont formés sur des ensembles de données composés en grande majorité de personnes à la peau claire.
A 2021 étude de l'Université d'Oxford ont étudié 21 ensembles de données en libre accès pour y trouver des images de cancer de la peau. Ils ont découvert que sur les 14 ensembles de données dont l'origine géographique était divulguée, 11 étaient uniquement constitués d'images provenant d'Europe, d'Amérique du Nord et d'Océanie.
Seules 2 436 images sur les 106 950 images des 21 bases de données comportaient des informations sur le type de peau. Les chercheurs ont noté que "seules 10 images provenaient de personnes enregistrées comme ayant la peau brune et une était celle d'un individu enregistré comme ayant la peau brun foncé ou noire".
En ce qui concerne les données relatives à l'origine ethnique, seules 1 585 images fournissaient cette information. Les chercheurs ont constaté qu'"aucune image ne représentait des personnes d'origine africaine, afro-caribéenne ou sud-asiatique".
Ils concluent : "En raison de l'origine géographique des ensembles de données, les images de lésions cutanées provenant de populations à la peau plus foncée sont massivement sous-représentées".
Si ces IA sont déployées dans des environnements cliniques, les ensembles de données biaisées créent un risque très réel d'erreur de diagnostic.
Disséquer les biais dans les ensembles de données d'entraînement à l'IA : un produit de leurs créateurs ?
Les données d'apprentissage - le plus souvent du texte, de la parole, des images et des vidéos - fournissent à un modèle d'apprentissage automatique supervisé (ML) une base pour l'apprentissage de concepts.
Les systèmes d'IA ne sont rien d'autre que des toiles vierges au départ. Ils apprennent et forment des associations sur la base de nos données, peignant essentiellement une image du monde telle qu'elle est dépeinte par leurs ensembles de données d'apprentissage.
En apprenant à partir de données d'entraînement, on espère que le modèle appliquera les concepts appris à de nouvelles données inédites.
Une fois déployés, certains modèles avancés peuvent apprendre à partir de nouvelles données, mais leurs données de formation déterminent toujours leurs performances fondamentales.
La première question à laquelle il faut répondre est la suivante : d'où viennent les données ? Les données collectées à partir de sources non représentatives, souvent homogènes et historiquement inéquitables posent problème.
Cela s'applique probablement à une quantité importante de données en ligne, y compris des données textuelles et des images extraites de sources "ouvertes" ou "publiques".
Conçu il y a seulement quelques décennies, l'internet n'est pas une panacée pour le savoir humain et est loin d'être équitable. La moitié de la population mondiale n'utilise pas l'internet, et y contribue encore moins, ce qui signifie qu'il est fondamentalement non représentatif de la société et de la culture mondiales.
En outre, alors que les développeurs d'IA travaillent constamment à garantir que les avantages de la technologie ne se limitent pas au monde anglophone, la majorité des données de formation (texte et parole) sont produites en anglais - ce qui signifie que les contributeurs anglophones déterminent les résultats du modèle.
Des chercheurs de l'Anthropic récemment a publié un document sur ce même sujet, concluant : "Si un modèle linguistique représente de manière disproportionnée certaines opinions, il risque d'avoir des effets potentiellement indésirables, tels que la promotion de visions du monde hégémoniques et l'homogénéisation des perspectives et des croyances des gens".
En définitive, si les systèmes d'IA fonctionnent sur la base des principes "objectifs" des mathématiques et de la programmation, ils n'en existent pas moins dans un contexte social humain profondément subjectif et sont façonnés par lui.
Solutions possibles au biais algorithmique
Si les données sont le problème fondamental, la solution pour construire des modèles équitables peut sembler simple : il suffit de rendre les ensembles de données plus équilibrés, n'est-ce pas ?
Pas tout à fait. A Étude 2019 a montré qu'il ne suffit pas d'équilibrer les ensembles de données, car les algorithmes agissent encore de manière disproportionnée sur des caractéristiques protégées telles que le sexe et la race.
Les auteurs écrivent : "De manière surprenante, nous montrons que même lorsque les ensembles de données sont équilibrés de manière à ce que chaque étiquette coïncide de manière égale avec chaque sexe, les modèles appris amplifient l'association entre les étiquettes et le sexe, autant que si les données n'avaient pas été équilibrées".
Ils proposent une technique de débiaisage qui consiste à supprimer ces étiquettes de l'ensemble des données. D'autres techniques consistent à ajouter des perturbations et des distorsions aléatoires, qui réduisent l'attention d'un algorithme à des caractéristiques protégées spécifiques.
En outre, bien que la modification des méthodes d'apprentissage automatique et l'optimisation soient intrinsèques à la production de résultats non biaisés, les modèles avancés sont susceptibles de changer ou de "dériver", ce qui signifie que leurs performances ne restent pas nécessairement constantes à long terme.
Un modèle peut être totalement impartial au moment du déploiement, mais devenir biaisé par la suite en raison de l'exposition accrue à de nouvelles données.
Le mouvement de la transparence algorithmique
Dans son livre provocateur L'inintelligence artificielle : Comment les ordinateurs comprennent mal le mondeMeredith Broussard plaide en faveur d'une "transparence algorithmique" accrue afin d'exposer les systèmes d'IA à de multiples niveaux d'examen permanent.
Cela signifie qu'il faut fournir des informations claires sur le fonctionnement du système, sur la manière dont il a été formé et sur les données sur lesquelles il a été formé.
Alors que les initiatives de transparence sont facilement intégrées dans le paysage de l'IA à code source ouvert, les modèles propriétaires tels que GPT, Bard et Anthropic's Claude sont des "boîtes noires" dont seuls les développeurs connaissent précisément le fonctionnement - et même cela fait l'objet d'un débat.
Le problème de la "boîte noire" dans l'IA signifie que les observateurs externes ne voient que ce qui entre dans le modèle (les entrées) et ce qui en sort (les sorties). Les mécanismes internes sont totalement inconnus, sauf de leurs créateurs - un peu comme le cercle magique protège les secrets des magiciens. L'IA ne fait que sortir le lapin du chapeau.
La question de la boîte noire s'est récemment cristallisée autour des rapports de Baisse potentielle des performances du GPT-4. Les utilisateurs de GPT-4 affirment que les capacités du modèle ont diminué rapidement, et bien qu'OpenAI reconnaisse que c'est vrai, ils n'ont pas été très clairs sur les raisons de ce phénomène. La question se pose donc de savoir s'ils le savent au moins.
Sasha Luccioni, chercheur en IA, explique que le manque de transparence d'OpenAI est un problème qui s'applique également à d'autres développeurs de modèles d'IA propriétaires ou fermés. "Tous les résultats des modèles à source fermée ne sont ni reproductibles ni vérifiables et, d'un point de vue scientifique, nous comparons donc des ratons laveurs et des écureuils."
“Ce n'est pas aux scientifiques de surveiller en permanence les LLM déployés. Il incombe aux créateurs de modèles de donner accès aux modèles sous-jacents, au moins à des fins d'audit", a-t-elle déclaré.
M. Luccioni a insisté sur le fait que les développeurs de modèles d'IA devraient fournir les résultats bruts de tests standard tels que SuperGLUE et WikiText et de tests de biais tels que BOLD et HONEST.
La lutte contre les biais et les préjugés induits par l'IA sera probablement constante et nécessitera une attention et une recherche permanentes afin de contrôler les résultats des modèles à mesure que l'IA et la société évoluent ensemble.
Si la réglementation imposera des formes de contrôle et de reporting, il existe peu de solutions définitives au problème des biais algorithmiques, et ce n'est pas la dernière fois que nous en entendons parler.



