

Les chercheurs de Google DeepMind ont développé NATURAL PLAN, une référence pour évaluer la capacité des LLM à planifier des tâches du monde réel sur la base d'invites en langage naturel.
La prochaine évolution de l'IA consistera à la faire sortir des limites d'une plateforme de chat et à lui faire jouer un rôle d'agent pour qu'elle accomplisse en notre nom des tâches sur différentes plateformes. Mais c'est plus difficile qu'il n'y paraît.
Les tâches de planification, telles que l'organisation d'une réunion ou l'élaboration d'un itinéraire de vacances, peuvent nous sembler simples. L'être humain est doué pour raisonner à travers de multiples étapes et pour prédire si un plan d'action permettra ou non d'atteindre l'objectif souhaité.
Vous trouvez peut-être cela facile, mais même les meilleurs modèles d'intelligence artificielle ont du mal à planifier. Pourrions-nous les comparer pour voir quel LLM est le plus performant en matière de planification ?
Le benchmark NATURAL PLAN teste les LLM sur 3 tâches de planification :
- Planification du voyage - Planification d'un itinéraire de voyage sous contraintes de vol et de destination
- Planification des réunions - Planifier des réunions avec plusieurs amis dans des lieux différents
- Programmation du calendrier - Planifier des réunions de travail entre plusieurs personnes en fonction des calendriers existants et de diverses contraintes.
L'expérience a commencé par des messages-guides à quelques reprises : les modèles ont reçu cinq exemples de messages-guides et les réponses correctes correspondantes. Ils ont ensuite été invités à répondre à des questions de planification de difficulté variable.
Voici un exemple d'une demande et d'une solution fournie à titre d'exemple aux modèles :

Résultats
Les chercheurs ont testé le GPT-3.5, le GPT-4, GPT-4oGemini 1.5 Flash, et Gemini 1.5 ProAucun d'entre eux n'a obtenu de très bons résultats lors de ces tests.
Les résultats ont dû être bien accueillis dans les bureaux de DeepMind, puisque Gemini 1.5 Pro est arrivé en tête.

Comme prévu, les résultats ont empiré de manière exponentielle avec les questions plus complexes, où le nombre de personnes ou de villes a été augmenté. Par exemple, regardez la rapidité avec laquelle la précision s'est dégradée au fur et à mesure que l'on ajoutait des personnes au test de planification d'une réunion.
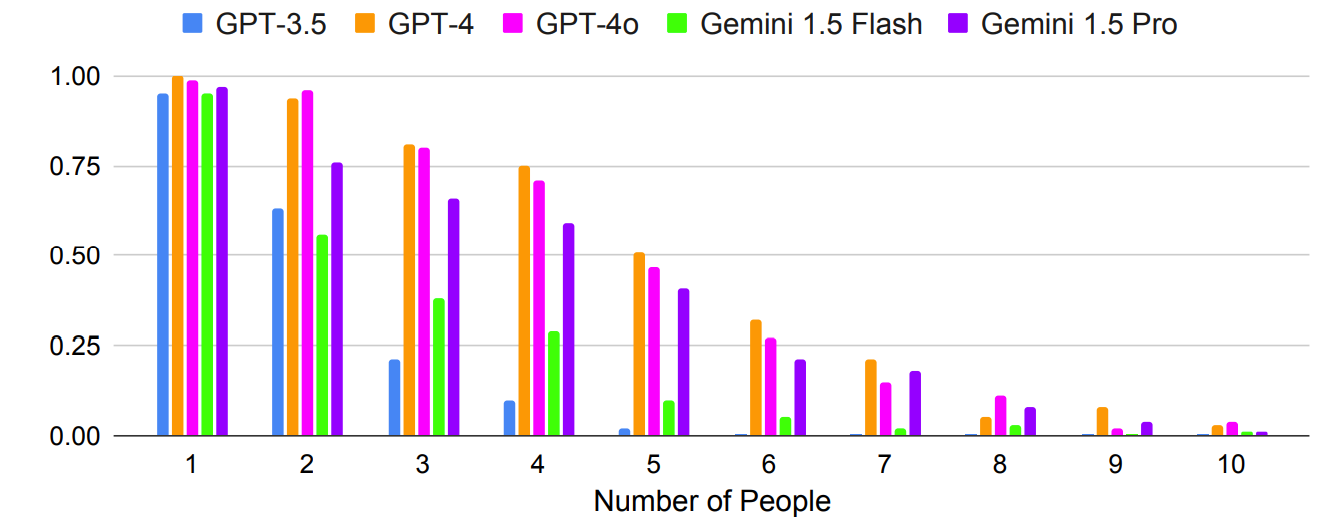
Les messages-guides à tirs multiples peuvent-ils améliorer la précision ? Les résultats de la recherche indiquent que c'est possible, mais seulement si le modèle dispose d'une fenêtre contextuelle suffisamment large.
La fenêtre contextuelle plus large de Gemini 1.5 Pro lui permet d'exploiter davantage d'exemples en contexte que les modèles GPT.
Les chercheurs ont constaté que dans la planification des voyages, l'augmentation du nombre de prises de vue de 1 à 800 améliore la précision de Gemini Pro 1.5 de 2,7% à 39,9%.
Le document a noté que "ces résultats montrent la promesse d'une planification en contexte où les capacités du contexte long permettent aux LLM de tirer parti d'un contexte supplémentaire pour améliorer la planification".
Un résultat étrange a été que GPT-4o était vraiment mauvais en matière de planification de voyage. Les chercheurs ont constaté qu'il avait du mal à "comprendre et à respecter les contraintes liées à la connectivité des vols et à la date du voyage".
Autre résultat étrange, l'autocorrection a entraîné une baisse significative des performances de tous les modèles. Lorsque les modèles ont été invités à vérifier leur travail et à le corriger, ils ont commis davantage d'erreurs.
Il est intéressant de noter que les modèles les plus robustes, tels que GPT-4 et Gemini 1.5 Pro, ont subi des pertes plus importantes que GPT-3.5 lors de l'autocorrection.
L'IA agentique est une perspective passionnante et nous voyons déjà des cas d'utilisation pratique dans les domaines suivants Microsoft Copilot agents.
Mais les résultats des tests de référence NATURAL PLAN montrent qu'il reste encore du chemin à parcourir avant que l'IA ne puisse gérer une planification plus complexe.
Les chercheurs de DeepMind ont conclu que "NATURAL PLAN est très difficile à résoudre pour les modèles de pointe".
Il semble que l'IA ne remplacera pas tout de suite les agents de voyage et les assistants personnels.



