

L'université de Stanford a publié son rapport sur l'indice de l'IA pour 2024, qui indique que les progrès rapides de l'IA rendent les comparaisons avec les humains de moins en moins pertinentes.
Les rapport annuel donne un aperçu complet des tendances et de l'état d'avancement des développements en matière d'IA. Le rapport indique que les modèles d'IA s'améliorent si rapidement que les critères de référence que nous utilisons pour les mesurer deviennent de moins en moins pertinents.
De nombreux critères de référence industriels comparent les modèles d'IA à l'efficacité des humains dans l'exécution de tâches. Le benchmark Massive Multitask Language Understanding (MMLU) en est un bon exemple.
Il utilise des questions à choix multiples pour évaluer les LLM dans 57 matières, dont les mathématiques, l'histoire, le droit et l'éthique. Le MMLU est la référence en matière d'IA depuis 2019.
Le score de référence humain sur le MMLU est de 89,8%, et en 2019, le modèle d'IA moyen a obtenu un peu plus de 30%. Cinq ans plus tard, Gemini Ultra est devenu le premier modèle à battre la référence humaine avec un score de 90,04%.
Le rapport note que les "systèmes d'IA actuels dépassent régulièrement les performances humaines sur les critères de référence standard". Les tendances du graphique ci-dessous semblent indiquer que le MMLU et d'autres critères doivent être remplacés.
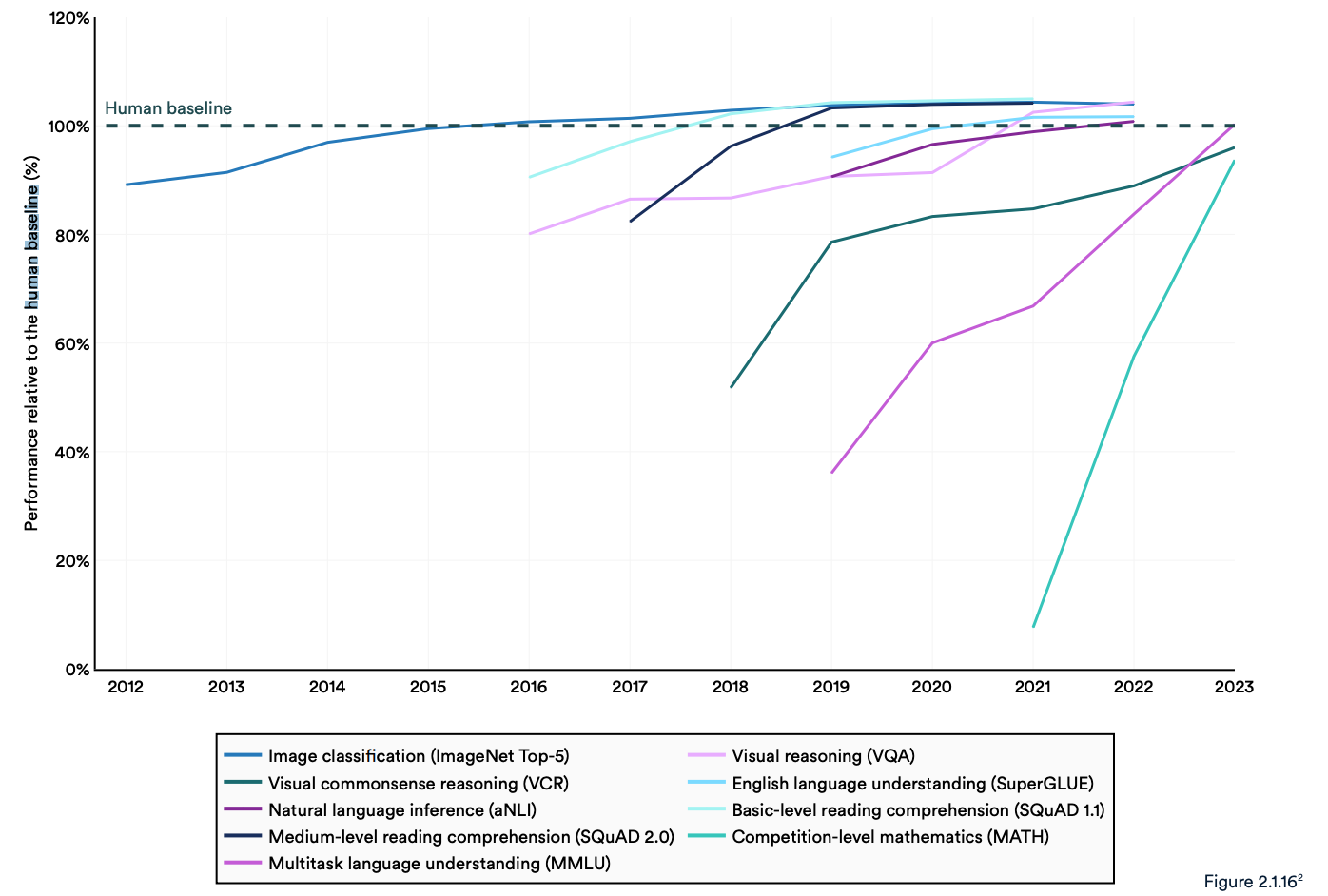
Les modèles d'IA ont atteint la saturation des performances sur des critères de référence établis tels que ImageNet, SQuAD et SuperGLUE, de sorte que les chercheurs développent des tests plus difficiles.
Un exemple est le Graduate-Level Google-Proof Q&A Benchmark (GPQA), qui permet d'évaluer les modèles d'IA par rapport à des personnes vraiment intelligentes, plutôt que par rapport à l'intelligence humaine moyenne.
Le test GPQA se compose de 400 questions à choix multiples difficiles, de niveau universitaire. Les experts qui ont obtenu ou poursuivent leur doctorat répondent correctement aux questions dans 65% des cas.
Le document du GPQA indique que lorsqu'on leur pose des questions en dehors de leur domaine, "des validateurs non experts hautement qualifiés n'atteignent qu'une précision de 34%, bien qu'ils aient passé en moyenne plus de 30 minutes avec un accès illimité à l'Internet".
Le mois dernier, Anthropic a annoncé que Claude 3 a obtenu un résultat légèrement inférieur à 60% avec une incitation CoT à 5 coups. Nous allons avoir besoin d'une référence plus importante.
Claude 3 obtient une précision de ~60% au GPQA. Il m'est difficile de sous-estimer la difficulté de ces questions : des docteurs littéraires (dans des domaines différents de ceux des questions) ayant accès à l'internet obtiennent 34%.
Les doctorants *dans le même domaine* (également avec accès à l'internet !) obtiennent une précision de 65% - 75%. https://t.co/ARAiCNXgU9 pic.twitter.com/PH8J13zIef
- david rein (@idavidrein) 4 mars 2024
Évaluations humaines et sécurité
Le rapport note que l'IA est encore confrontée à des problèmes importants : "Elle ne peut pas traiter les faits de manière fiable, effectuer des raisonnements complexes ou expliquer ses conclusions.
Ces limites contribuent à une autre caractéristique du système d'IA qui, selon le rapport, est mal mesurée ; Sécurité de l'IA. Nous ne disposons pas de critères de référence efficaces qui nous permettraient de dire : "Ce modèle est plus sûr que celui-là".
Cela s'explique en partie par le fait qu'elle est difficile à mesurer et que "les développeurs d'IA manquent de transparence, notamment en ce qui concerne la divulgation des données et des méthodologies de formation".
Le rapport note qu'une tendance intéressante dans l'industrie est de faire appel à des évaluations humaines des performances de l'IA, plutôt qu'à des tests de référence.
Il est difficile de classer l'esthétique ou la prose d'un modèle à l'aide d'un test. En conséquence, le rapport indique que "l'évaluation comparative a lentement commencé à s'orienter vers l'incorporation d'évaluations humaines comme le Chatbot Arena Leaderboard plutôt que vers des classements informatisés comme ImageNet ou SQuAD".
Alors que les modèles d'IA voient la référence humaine disparaître dans le rétroviseur, le sentiment pourrait finalement déterminer le modèle que nous choisirons d'utiliser.
Les tendances indiquent que les modèles d'IA finiront par être plus intelligents que nous et plus difficiles à mesurer. Nous pourrions bientôt nous retrouver à dire : "Je ne sais pas pourquoi, mais je préfère celui-ci".



