

Une équipe de chercheurs de l'université de New York a progressé dans le décodage neuronal de la parole, ce qui nous rapproche d'un avenir où les personnes ayant perdu l'usage de la parole pourront retrouver leur voix.
Les étude, publié dans Nature Machine Intelligenceprésente un nouveau cadre d'apprentissage profond qui traduit avec précision les signaux cérébraux en paroles intelligibles.
Les personnes souffrant de lésions cérébrales dues à des accidents vasculaires cérébraux, à des maladies dégénératives ou à des traumatismes physiques peuvent utiliser ces systèmes pour communiquer en décodant leurs pensées ou leur discours à partir des signaux neuronaux.
Le système de l'équipe de l'Université de New York comprend un modèle d'apprentissage profond qui établit une correspondance entre les signaux d'électrocorticographie (ECoG) du cerveau et les caractéristiques de la parole, telles que la hauteur, le volume et d'autres contenus spectraux.
La deuxième étape fait intervenir un synthétiseur de parole neuronal qui convertit les caractéristiques vocales extraites en un spectrogramme audible, qui peut ensuite être transformé en une forme d'onde vocale.
Cette forme d'onde peut enfin être convertie en une synthèse vocale à la sonorité naturelle.
Un nouvel article est publié aujourd'hui dans @NatMachIntelloù nous montrons un décodage neuronal robuste de la parole chez 48 patients. https://t.co/rNPAMr4l68 pic.twitter.com/FG7QKCBVzp
- Adeen Flinker 🇮🇱🇺🇦🎗️ (@adeenflinker) 9 avril 2024
Comment fonctionne l'étude ?
Cette étude porte sur la formation d'un modèle d'IA capable d'alimenter un dispositif de synthèse vocale, permettant aux personnes souffrant de troubles de la parole de parler en utilisant les impulsions électriques de leur cerveau.
Voici comment cela fonctionne plus en détail :
1. Collecte de données sur le cerveau
La première étape consiste à collecter les données brutes nécessaires à l'entraînement du modèle de décodage de la parole. Les chercheurs ont travaillé avec 48 participants ayant subi une neurochirurgie pour épilepsie.
Au cours de l'étude, ces participants ont été invités à lire des centaines de phrases à haute voix pendant que leur activité cérébrale était enregistrée à l'aide de grilles ECoG.
Ces grilles sont placées directement à la surface du cerveau et captent les signaux électriques des régions cérébrales impliquées dans la production de la parole.
2. Cartographie des signaux cérébraux et de la parole
À partir de données vocales, les chercheurs ont mis au point un modèle d'intelligence artificielle sophistiqué qui associe les signaux cérébraux enregistrés à des caractéristiques spécifiques de la parole, telles que la hauteur, le volume et les fréquences uniques qui composent les différents sons de la parole.
3. Synthèse de la parole à partir de caractéristiques
La troisième étape consiste à convertir les caractéristiques vocales extraites des signaux cérébraux en paroles audibles.
Les chercheurs ont utilisé un synthétiseur vocal spécial qui prend les caractéristiques extraites et génère un spectrogramme - une représentation visuelle des sons de la parole.
4. Évaluer les résultats
Les chercheurs ont comparé le discours généré par leur modèle au discours original prononcé par les participants.
Ils ont utilisé des paramètres objectifs pour mesurer la similitude entre les deux et ont constaté que le discours généré correspondait étroitement au contenu et au rythme de l'original.
5. Test sur des mots nouveaux
Pour s'assurer que le modèle peut traiter de nouveaux mots qu'il n'a pas vus auparavant, certains mots ont été intentionnellement omis pendant la phase d'entraînement du modèle, puis la performance du modèle sur ces mots non vus a été testée.
La capacité du modèle à décoder avec précision même des mots nouveaux démontre son potentiel de généralisation et de traitement de divers modèles de discours.
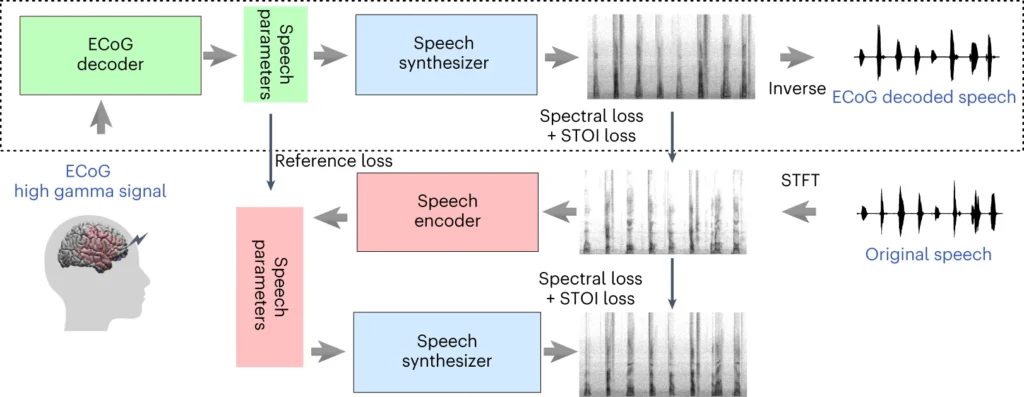
La partie supérieure du diagramme ci-dessus décrit le processus de conversion des signaux cérébraux en parole. Tout d'abord, un décodeur transforme ces signaux en paramètres vocaux au fil du temps. Ensuite, un synthétiseur crée des images sonores (spectrogrammes) à partir de ces paramètres. Un autre outil transforme à nouveau ces images en ondes sonores.
La dernière section traite d'un système qui aide à former le décodeur de signaux cérébraux en imitant la parole. Il prend une image sonore, la transforme en paramètres vocaux, puis les utilise pour créer une nouvelle image sonore. Cette partie du système apprend à partir de sons vocaux réels pour s'améliorer.
Après la formation, seul le processus supérieur est nécessaire pour transformer les signaux cérébraux en parole.
L'un des principaux avantages du système de l'Université de New York est qu'il permet d'obtenir un décodage vocal de haute qualité sans avoir recours à des réseaux d'électrodes à très haute densité, qui ne sont pas pratiques pour une utilisation à long terme.
Il s'agit essentiellement d'une solution plus légère et plus portable.
Une autre réalisation est le décodage réussi de la parole à partir des hémisphères gauche et droit du cerveau, ce qui est important pour les patients souffrant de lésions cérébrales d'un seul côté du cerveau.
Convertir les pensées en paroles grâce à l'IA
L'étude de l'Université de New York s'appuie sur des recherches antérieures concernant le décodage neuronal de la parole et les interfaces cerveau-ordinateur (BCI).
En 2023, une équipe de l'Université de Californie à San Francisco a permis à un survivant d'un accident vasculaire cérébral paralysé d'être en mesure de se déplacer dans le monde entier. générer des phrases à une vitesse de 78 mots par minute en utilisant un BCI qui synthétise à la fois les vocalisations et les expressions faciales à partir des signaux cérébraux.
D'autres études récentes ont exploré l'utilisation de l'IA pour interpréter divers aspects de la pensée humaine à partir de l'activité cérébrale. Des chercheurs ont démontré leur capacité à générer des images, du texte et même de la musique à partir de données d'IRM et d'électroencéphalogrammes (EEG) prélevées sur le cerveau.
Par exemple, un étude de l'Université d'Helsinki a utilisé des signaux EEG pour guider un réseau génératif contradictoire (GAN) dans la production d'images faciales correspondant aux pensées des participants.
L'IA méta a mis au point une technique pour décoder partiellement ce qu'une personne écoute en utilisant les ondes cérébrales recueillies de manière non invasive.
Opportunités et défis
La méthode de l'Université de New York utilise des électrodes plus largement disponibles et cliniquement viables que les méthodes précédentes, ce qui la rend plus accessible.
Bien que cela soit passionnant, il y a des obstacles majeurs à surmonter si nous voulons assister à une utilisation généralisée.
D'une part, la collecte de données cérébrales de haute qualité est une entreprise complexe qui prend du temps. Les différences individuelles dans l'activité cérébrale rendent la généralisation difficile, ce qui signifie qu'un modèle formé pour un groupe de participants peut ne pas fonctionner correctement pour un autre.
Néanmoins, l'étude de l'Université de New York représente un pas en avant dans cette direction en démontrant un décodage de la parole de haute précision à l'aide de réseaux d'électrodes plus légers.
À l'avenir, l'équipe de l'université de New York entend affiner ses modèles de décodage de la parole en temps réel, ce qui nous rapprochera de l'objectif ultime : permettre aux personnes souffrant de troubles de la parole d'avoir des conversations naturelles et fluides.
Ils ont également l'intention d'adapter le système à des dispositifs sans fil implantables pouvant être utilisés dans la vie de tous les jours.



