

Google's DeepMind a publié Gecko, une nouvelle référence pour l'évaluation complète des modèles de conversion texte-image (T2I) de l'IA.
Au cours des deux dernières années, nous avons vu des générateurs d'images d'IA tels que DALL-E et Voyage à mi-parcours s'améliorent progressivement au fil des versions.
Toutefois, le choix du meilleur modèle sous-jacent utilisé par ces plateformes est largement subjectif et difficile à évaluer.
Il n'est pas si simple d'affirmer qu'un modèle est "meilleur" qu'un autre. Différents modèles excellent dans divers aspects de la génération d'images. L'un d'entre eux peut être bon pour le rendu de texte, tandis qu'un autre peut être meilleur pour l'interaction avec les objets.
L'un des principaux défis auxquels sont confrontés les modèles T2I est de suivre chaque détail de l'invite et de le refléter avec précision dans l'image générée.
Avec Gecko, le DeepMind Les chercheurs ont créé un repère qui évalue les capacités des modèles T2I comme le font les humains.
Compétences
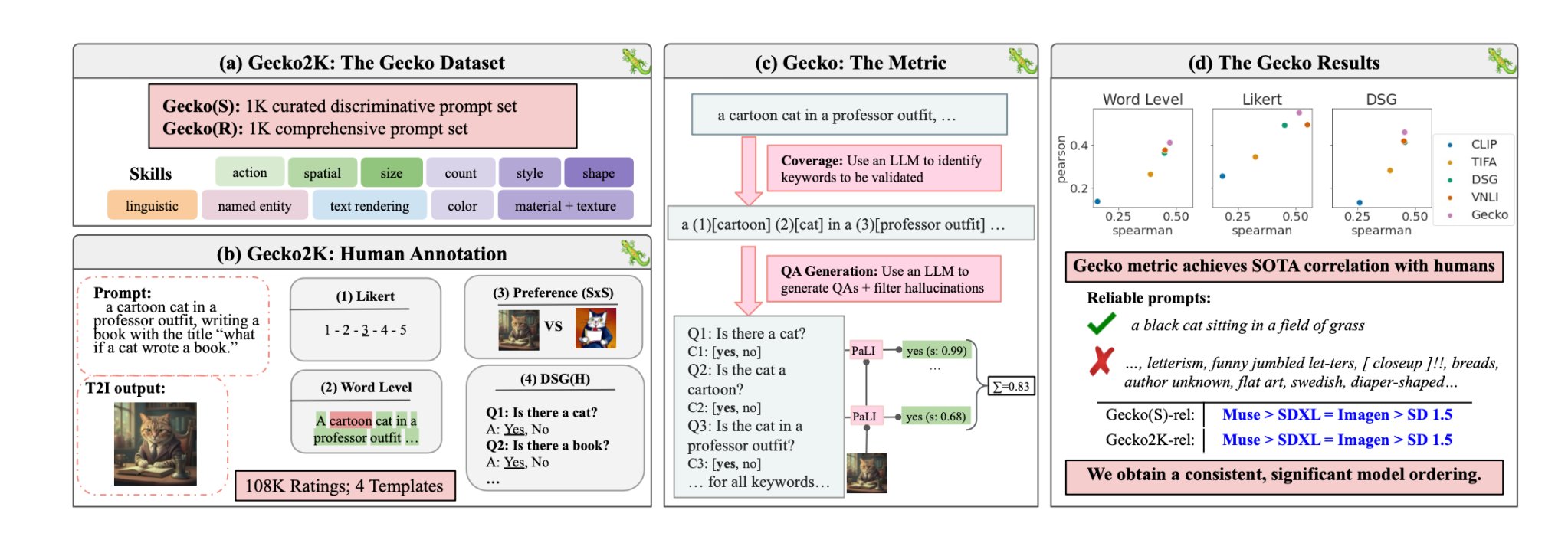
Les chercheurs ont d'abord défini un ensemble complet de compétences pertinentes pour la génération de T2I. Il s'agit notamment de la compréhension spatiale, de la reconnaissance d'actions et de la restitution de textes. Ils ont ensuite décomposé ces compétences en sous-compétences plus spécifiques.
Par exemple, dans le cadre du rendu de texte, les sous-compétences peuvent inclure le rendu de différentes polices, couleurs ou tailles de texte.
Un LLM a ensuite été utilisé pour générer des invites afin de tester la capacité du modèle T2I sur une compétence ou une sous-compétence spécifique.
Cela permet aux créateurs d'un modèle T2I d'identifier non seulement les compétences qui posent problème, mais aussi le niveau de complexité auquel une compétence devient problématique pour leur modèle.
Évaluer l'humain par rapport à l'auto
Gecko mesure également la précision avec laquelle un modèle T2I suit tous les détails d'une invite. Là encore, un LLM a été utilisé pour isoler les détails clés de chaque message d'entrée, puis pour générer un ensemble de questions liées à ces détails.
Il peut s'agir de questions simples et directes sur les éléments visibles de l'image (par exemple, "Y a-t-il un chat sur l'image ?") ou de questions plus complexes qui testent la compréhension de la scène ou les relations entre les objets (par exemple, "Le chat est-il assis au-dessus du livre ?").
Un modèle de réponse aux questions visuelles (VQA) analyse ensuite l'image générée et répond aux questions pour voir avec quelle précision le modèle T2I aligne son image de sortie sur une invite d'entrée.
Les chercheurs ont recueilli plus de 100 000 annotations humaines dans lesquelles les participants notaient une image générée en fonction du degré d'alignement de l'image sur des critères spécifiques.
Les humains ont été invités à prendre en compte un aspect spécifique de l'invite et à noter l'image sur une échelle de 1 à 5 en fonction de son adéquation avec l'invite.
En utilisant les évaluations annotées par des humains comme étalon-or, les chercheurs ont pu confirmer que leur métrique d'évaluation automatique "est mieux corrélée avec les évaluations humaines que les métriques existantes pour notre nouvel ensemble de données".
Le résultat est un système d'étalonnage capable de chiffrer les facteurs spécifiques qui font qu'une image générée est bonne ou non.
Gecko évalue essentiellement l'image de sortie d'une manière qui correspond étroitement à la façon dont nous décidons intuitivement si nous sommes satisfaits ou non de l'image générée.
Quel est donc le meilleur modèle de conversion du texte en image ?
En leur documentLes chercheurs ont conclu que le modèle Muse de Google surpasse Stable Diffusion 1.5 et SDXL sur le benchmark Gecko. Ils sont peut-être partiaux, mais les chiffres ne mentent pas.



