

Des chercheurs de DeepMind et de l'université de Stanford ont mis au point un agent d'IA qui vérifie les faits et permet d'évaluer la factualité des modèles d'IA.
Même les meilleurs modèles d'IA ont encore tendance à halluciner parfois. Si vous demandez à ChatGPT de vous donner les faits sur un sujet, plus sa réponse est longue, plus il est probable qu'elle contienne des faits qui ne sont pas vrais.
Quels modèles sont plus précis que d'autres lorsqu'ils génèrent des réponses plus longues ? Il est difficile de le dire car, jusqu'à présent, nous ne disposions pas d'un point de référence pour mesurer l'exactitude des faits dans les réponses au formulaire long du programme LLM.
DeepMind a d'abord utilisé GPT-4 pour créer LongFact, un ensemble de 2 280 invites sous forme de questions liées à 38 sujets. Ces invites suscitent des réponses longues de la part du LLM testé.
Ils ont ensuite créé un agent d'IA utilisant GPT-3.5-turbo pour utiliser Google afin de vérifier si les réponses générées par le LLM étaient factuelles. Ils ont appelé cette méthode Search-Augmented Factuality Evaluator (SAFE).
SAFE décompose d'abord la réponse longue du LLM en faits individuels. Il envoie ensuite des demandes de recherche à Google Search et se prononce sur la véracité du fait en se basant sur les informations contenues dans les résultats de la recherche.
Voici un exemple tiré de la document de recherche.
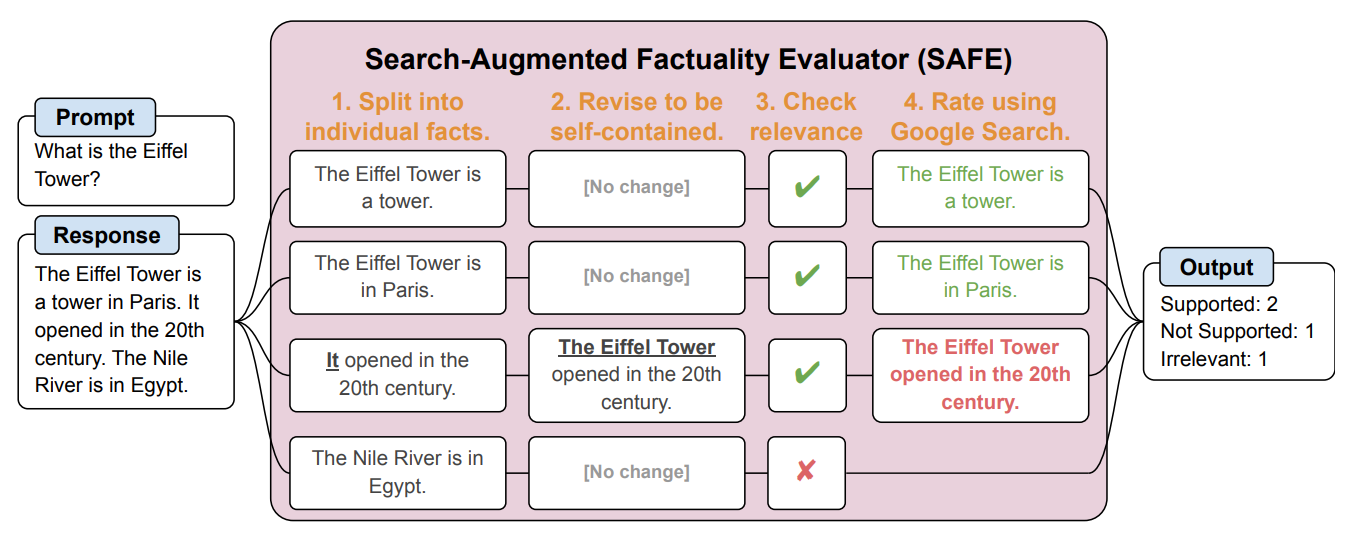
Les chercheurs affirment que SAFE atteint des "performances surhumaines" par rapport aux annotateurs humains chargés de la vérification des faits.
SAFE a approuvé 72% des annotations humaines et, en cas de divergence avec les humains, il s'est avéré juste dans 76% des cas. Il était également 20 fois moins cher que les annotateurs humains issus du crowdsourcing. Les LLM sont donc des vérificateurs de faits meilleurs et moins chers que les humains.
La qualité de la réponse des MFR testés a été mesurée sur la base du nombre de factoïdes dans la réponse et du degré d'exactitude des factoïdes individuels.
La mesure qu'ils ont utilisée (F1@K) estime le nombre "idéal" de faits préférés par l'homme dans une réponse. Les tests de référence ont utilisé 64 comme médiane pour K et 178 comme maximum.
En d'autres termes, F1@K est une mesure de "La réponse m'a-t-elle donné autant de faits que je le souhaitais ?" combinée à "Combien de ces faits étaient vrais ?".
Quel est le LLM le plus factuel ?
Les chercheurs ont utilisé LongFact pour demander à 13 LLM des familles Gemini, GPT, Claude et PaLM-2 de répondre. Ils ont ensuite utilisé SAFE pour évaluer le caractère factuel de leurs réponses.
Le GPT-4-Turbo arrive en tête de liste des modèles les plus factuels lorsqu'il s'agit de générer des réponses longues. Il est suivi de près par Gemini-Ultra et PaLM-2-L-IT-RLHF. Les résultats montrent que les grands LLM sont plus factuels que les petits.
Le calcul de F1@K passionnerait probablement les spécialistes des données, mais, par souci de simplicité, ces résultats de référence montrent à quel point chaque modèle est factuel lorsqu'il renvoie des réponses de longueur moyenne et des réponses plus longues aux questions.
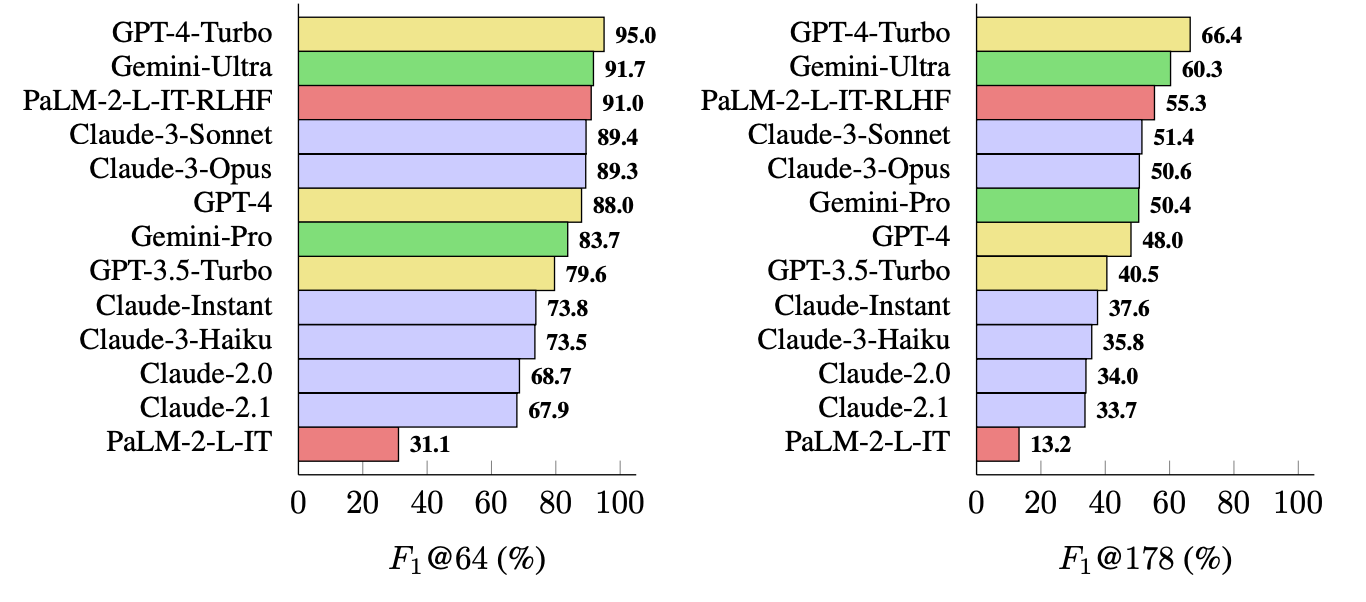
SAFE est un moyen peu coûteux et efficace de quantifier la factualité des formulaires longs LLM. Il est plus rapide et moins coûteux que les humains pour la vérification des faits, mais il dépend toujours de la véracité des informations que Google renvoie dans les résultats de recherche.
DeepMind a mis SAFE à la disposition du public et a suggéré qu'il pourrait contribuer à améliorer la factualité des LLM par le biais d'une meilleure formation préalable et d'un réglage fin. Il pourrait également permettre à un LLM de vérifier ses faits avant de présenter la sortie à un utilisateur.
L'OpenAI sera heureuse de constater que les recherches menées par Google montrent que GPT-4 bat Gemini dans un autre test de référence.



