

Les ingénieurs d'Apple ont mis au point un système d'IA qui résout les références complexes aux entités à l'écran et aux conversations des utilisateurs. Ce modèle léger pourrait constituer une solution idéale pour les assistants virtuels embarqués.
Les êtres humains sont doués pour résoudre les références dans les conversations entre eux. Lorsque nous utilisons des termes tels que "le bas" ou "lui", nous comprenons à quoi la personne fait référence en nous basant sur le contexte de la conversation et sur les éléments que nous pouvons voir.
Il est beaucoup plus difficile pour un modèle d'intelligence artificielle de le faire. Les LLM multimodaux tels que GPT-4 répondent bien aux questions sur les images, mais leur apprentissage est coûteux et le traitement de chaque requête sur une image nécessite beaucoup de ressources informatiques.
Les ingénieurs d'Apple ont adopté une approche différente avec leur système, appelé ReALM (Reference Resolution As Language Modeling). Le document vaut la peine d'être lu pour plus de détails sur leur processus de développement et de test.
ReALM utilise un LLM pour traiter les entités conversationnelles, à l'écran et en arrière-plan (alarmes, musique de fond) qui composent les interactions d'un utilisateur avec un agent virtuel d'IA.
Voici un exemple du type d'interaction qu'un utilisateur pourrait avoir avec un agent d'intelligence artificielle.
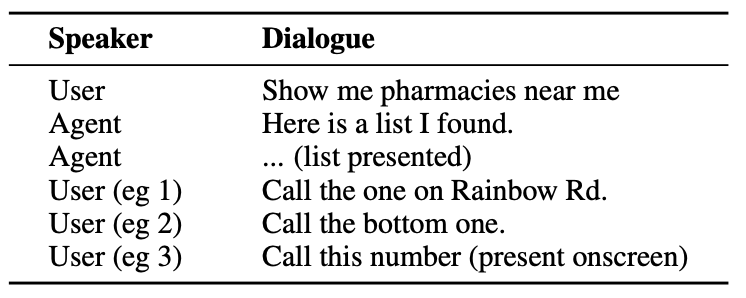
L'agent doit comprendre des entités conversationnelles telles que le fait que lorsque l'utilisateur dit "le", il fait référence au numéro de téléphone de la pharmacie.
Il doit également comprendre le contexte visuel lorsque l'utilisateur dit "celui du bas", et c'est là que l'approche de ReALM diffère de modèles tels que GPT-4.
ReALM s'appuie sur des encodeurs en amont pour analyser les éléments à l'écran et leur position. ReALM reconstruit ensuite l'écran en représentations purement textuelles, de gauche à droite et de haut en bas.
En termes simples, il utilise le langage naturel pour résumer l'écran de l'utilisateur.
Désormais, lorsqu'un utilisateur pose une question sur un élément affiché à l'écran, le modèle linguistique traite la description textuelle de l'écran au lieu d'utiliser un modèle visuel pour traiter l'image affichée à l'écran.
Les chercheurs ont créé des ensembles de données synthétiques d'entités conversationnelles, à l'écran et en arrière-plan, et ont testé ReALM et d'autres modèles pour vérifier leur efficacité à résoudre les références dans les systèmes conversationnels.
La version la plus petite de ReALM (80 millions de paramètres) a obtenu des résultats comparables à ceux de GPT-4 et sa version la plus grande (3 milliards de paramètres) a obtenu des résultats nettement supérieurs à ceux de GPT-4.
ReALM est un modèle minuscule par rapport à GPT-4. Sa résolution de référence supérieure en fait un choix idéal pour un assistant virtuel qui peut exister sur l'appareil sans compromettre les performances.
ReALM n'est pas aussi performant avec des images plus complexes ou des demandes d'utilisateurs plus nuancées, mais il pourrait faire office d'assistant virtuel dans une voiture ou sur un appareil. Imaginez que Siri puisse "voir" l'écran de votre iPhone et répondre à des références à des éléments affichés à l'écran.
Apple a été un peu lent à se lancer, mais des développements récents, tels que leur Modèle MM1 et ReALM montrent que beaucoup de choses se passent derrière des portes closes.



