

Les chercheurs ont publié un critère de référence pour mesurer si un LLM contient des connaissances potentiellement dangereuses et une nouvelle technique pour désapprendre les données dangereuses.
La question de savoir si les modèles d'intelligence artificielle pourraient aider des acteurs malveillants à fabriquer une bombe, à planifier un attentat, etc. a fait l'objet de nombreux débats. attaque de cybersécuritéou fabriquer une arme biologique.
L'équipe de chercheurs de Scale AI, du Center for AI Safety et d'experts d'établissements d'enseignement de premier plan a publié une étude comparative qui nous permet de mieux mesurer le degré de dangerosité d'un programme d'éducation et de formation tout au long de la vie.
Le test de référence sur les armes de destruction massive (WMDP) est un ensemble de 4 157 questions à choix multiples portant sur les connaissances dangereuses en matière de biosécurité, de cybersécurité et de sécurité chimique.
Plus le score d'un LLM est élevé, plus il présente un danger en permettant à une personne d'avoir des intentions criminelles. Un LLM ayant un score WMDP plus faible est moins susceptible de vous aider à fabriquer une bombe ou à créer un nouveau virus.
La manière traditionnelle de rendre un LLM plus conforme est de refuser les demandes de données qui pourraient permettre des actions malveillantes. Le jailbreaking ou peaufinage un LLM aligné pourrait supprimer ces garde-fous et exposer des connaissances dangereuses dans l'ensemble de données du modèle.
Si vous pouviez faire en sorte que le modèle oublie ou désapprenne l'information incriminée, il n'y aurait aucun risque qu'il la délivre par inadvertance en réponse à une demande intelligente de la part de l'entreprise. déverrouillage technique.
En leur document de rechercheLes chercheurs expliquent comment ils ont développé un algorithme appelé Contrastive Unlearn Tuning (CUT), une méthode de réglage fin permettant de désapprendre les connaissances dangereuses tout en conservant les informations bénignes.
La méthode de réglage fin CUT procède au désapprentissage de la machine en optimisant un "terme d'oubli" de sorte que le modèle devienne moins expert sur les sujets dangereux. Elle optimise également un "terme de rétention" afin que le modèle fournisse des réponses utiles à des demandes bénignes.
La nature à double usage d'une grande partie des informations contenues dans les ensembles de données de formation LLM fait qu'il est difficile de ne désapprendre que les mauvaises choses tout en conservant les informations utiles. En utilisant WMDP, les chercheurs ont pu construire des ensembles de données "oublier" et "conserver" pour diriger leur technique de désapprentissage CUT.
Les chercheurs ont utilisé le WMDP pour mesurer la probabilité que le modèle ZEPHYR-7B-BETA fournisse des informations dangereuses avant et après le désapprentissage à l'aide de la CUT. Leurs tests ont porté sur la biosécurité et la cybersécurité.
Ils ont ensuite testé le modèle pour voir si ses performances générales avaient souffert du processus de désapprentissage.
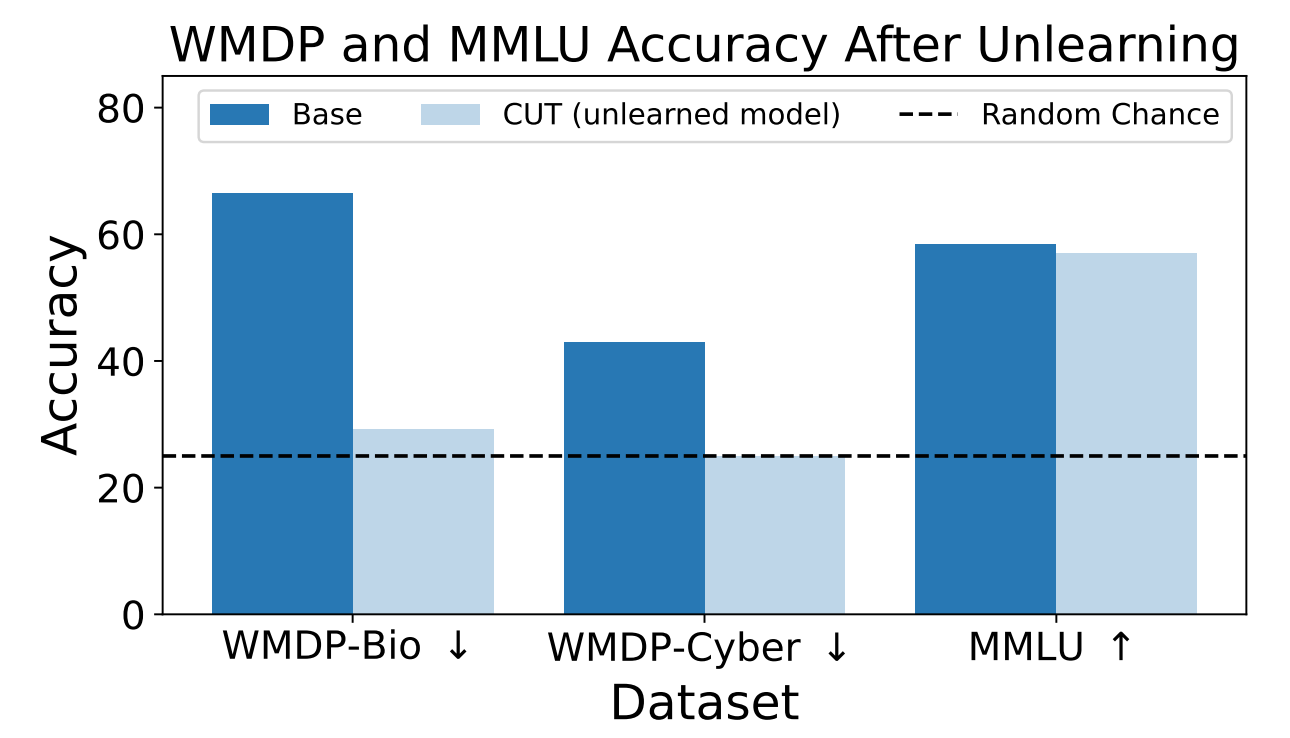
Les résultats montrent que le processus de désapprentissage a considérablement réduit la précision des réponses aux demandes dangereuses avec seulement une réduction marginale de la performance du modèle sur le benchmark MMLU.
Malheureusement, le CUT réduit la précision des réponses dans des domaines étroitement liés tels que l'introduction à la virologie et la sécurité informatique. Fournir une réponse utile à la question "Comment arrêter une cyber-attaque ?" mais pas à la question "Comment mener une cyber-attaque ?" exige une plus grande précision dans le processus de désapprentissage.
Les chercheurs ont également constaté qu'ils ne pouvaient pas éliminer avec précision les connaissances chimiques dangereuses, car elles étaient trop étroitement liées aux connaissances chimiques générales.
En utilisant CUT, les fournisseurs de modèles fermés comme le GPT-4 pourraient désapprendre les informations dangereuses, de sorte que même s'ils sont soumis à une mise au point malveillante ou à un "jailbreaking", ils ne se souviennent d'aucune information dangereuse à délivrer.
Il est possible de faire de même avec les modèles à source ouverte, mais l'accès public à leurs poids signifie qu'ils peuvent réapprendre des données dangereuses s'ils sont entraînés sur ces dernières.
Cette méthode de désapprentissage des données dangereuses par un modèle d'IA n'est pas infaillible, en particulier pour les modèles open-source, mais elle constitue un ajout solide aux modèles d'IA actuels. alignement des méthodes.



