

Apple n'a pas encore officiellement lancé de modèle d'IA, mais un nouveau document de recherche donne un aperçu des progrès réalisés par l'entreprise dans le développement de modèles dotés de capacités multimodales de pointe.
Le documentintitulé "MM1 : Methods, Analysis & Insights from Multimodal LLM Pre-training", présente la famille de MLLM d'Apple appelée MM1.
MM1 affiche des capacités impressionnantes en matière de sous-titrage d'images, de réponse à des questions visuelles (VQA) et d'inférence en langage naturel. Les chercheurs expliquent que le choix judicieux des paires d'images et de légendes leur a permis d'obtenir des résultats supérieurs, en particulier dans les scénarios d'apprentissage en quelques images.
Ce qui distingue MM1 des autres MLLM, c'est sa capacité supérieure à suivre des instructions sur plusieurs images et à raisonner sur les scènes complexes qui lui sont présentées.
Les modèles MM1 contiennent jusqu'à 30B paramètres, soit trois fois plus que le GPT-4V, le composant qui donne au GPT-4 de l'OpenAI ses capacités de vision.
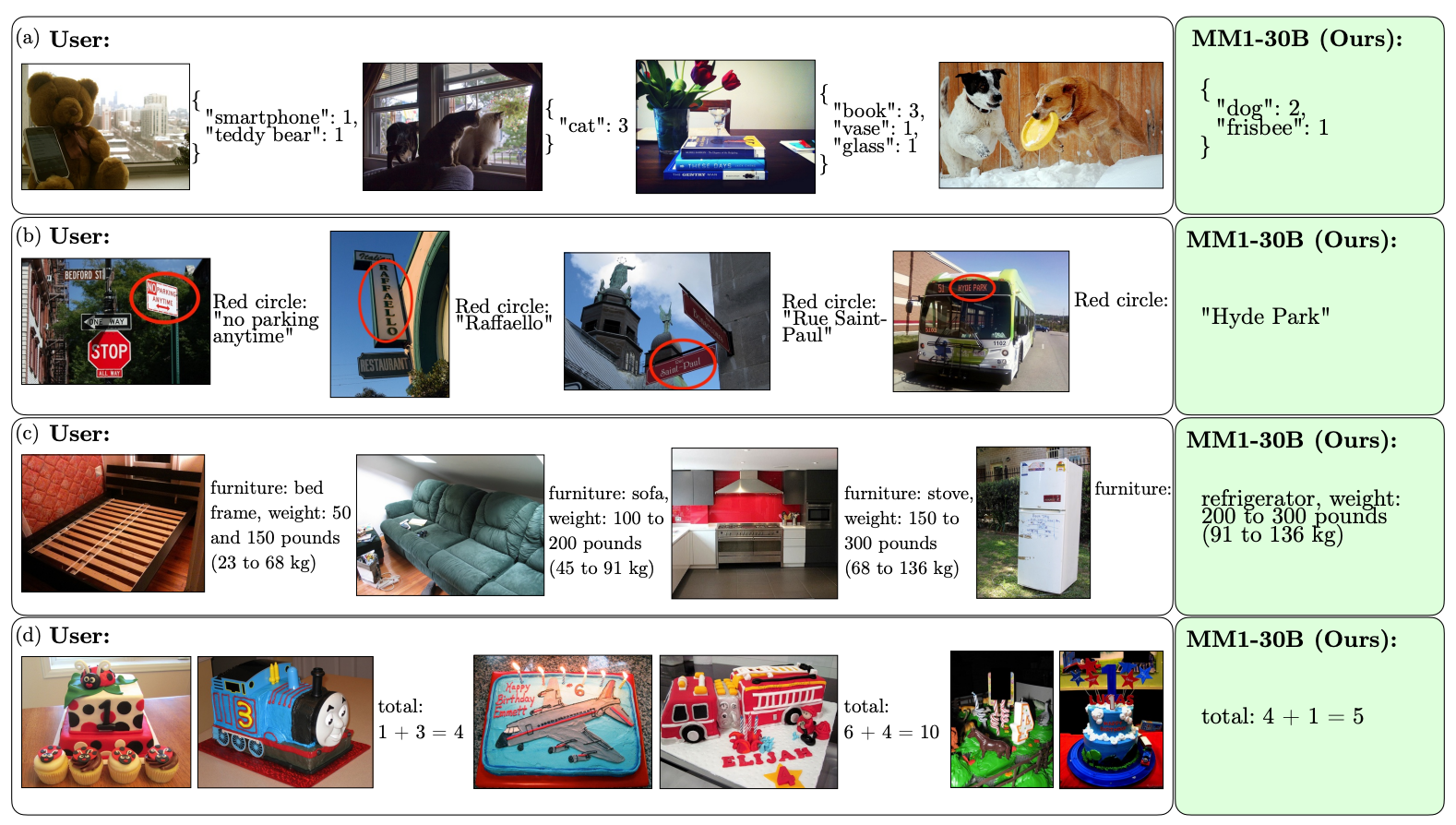
Voici quelques exemples des capacités du MM1 en matière de VQA.

MM1 a fait l'objet d'un préapprentissage multimodal à grande échelle sur "un ensemble de données de 500 millions de documents image-texte entrelacés, contenant 1 milliard d'images et 500 milliards de jetons de texte".
L'ampleur et la diversité de son préapprentissage permettent à MM1 d'effectuer d'impressionnantes prédictions en contexte et de suivre un formatage personnalisé à partir d'un petit nombre d'exemples. Voici des exemples de la façon dont MM1 apprend le résultat et le format souhaités à partir de seulement 3 exemples.
La création de modèles d'IA capables de "voir" et de raisonner nécessite un connecteur vision-langage qui traduit les images et le langage en une représentation unifiée que le modèle peut utiliser pour un traitement ultérieur.
Les chercheurs ont constaté que la conception du connecteur vision-langage n'était pas un facteur déterminant pour les performances de MM1. Il est intéressant de noter que c'est la résolution de l'image et le nombre de jetons d'image qui ont eu le plus d'impact.
Il est intéressant de constater l'ouverture d'Apple à partager ses recherches avec l'ensemble de la communauté de l'IA. Les chercheurs déclarent que "dans cet article, nous documentons le processus de construction du MLLM et tentons de formuler des leçons de conception qui, nous l'espérons, seront utiles à la communauté".
Les résultats publiés permettront probablement d'orienter les autres développeurs de MMLM en ce qui concerne l'architecture et le choix des données de pré-entraînement.
Reste à savoir comment les modèles MM1 seront mis en œuvre dans les produits Apple. Les exemples publiés des capacités de MM1 laissent penser que Siri deviendra beaucoup plus intelligent lorsqu'il apprendra à voir.



