
Le dépistage des patients pour trouver des participants appropriés aux essais cliniques est une tâche laborieuse, coûteuse et sujette aux erreurs, mais l'IA pourrait bientôt y remédier.
Une équipe de chercheurs du Brigham and Women's Hospital, de la Harvard Medical School et du Mass General Brigham Personalized Medicine a mené une étude pour déterminer si un modèle d'IA pouvait traiter les dossiers médicaux afin de trouver des candidats appropriés pour les essais cliniques.
Ils ont utilisé GPT-4V, le LLM d'OpenAI avec traitement d'images, activé par Retrieval-Augmented Generation (RAG) pour traiter les dossiers médicaux électroniques (EHR) et les notes cliniques des candidats potentiels.
Les LLM sont pré-entraînés à l'aide d'un ensemble de données fixe et ne peuvent répondre qu'à des questions basées sur ces données. Le RAG est une technique qui permet à un LLM de récupérer des données à partir de sources externes telles que l'Internet ou les documents internes d'une organisation.
Lorsque les participants sont sélectionnés pour un essai clinique, leur aptitude est déterminée par une liste de critères d'inclusion et d'exclusion. Cela implique normalement que du personnel formé passe au peigne fin les DSE de centaines ou de milliers de patients pour trouver ceux qui correspondent aux critères.
Les chercheurs ont recueilli les données d'un essai visant à recruter des patients souffrant d'insuffisance cardiaque symptomatique. Ils ont utilisé ces données pour voir si le GPT-4V avec RAG pouvait faire le travail plus efficacement que le personnel de l'étude tout en maintenant la précision.
Les données structurées contenues dans les dossiers médicaux électroniques des candidats potentiels pourraient être utilisées pour déterminer 5 des 6 critères d'inclusion et 5 des 17 critères d'exclusion de l'essai clinique. C'est la partie la plus facile.
Les 13 critères restants ont dû être déterminés en interrogeant les données non structurées des notes cliniques de chaque patient, ce qui constitue la partie laborieuse pour laquelle les chercheurs espéraient l'aide de l'IA.
🔍Can @Microsoft @Azure @OpenAI's #GPT4 est-il plus performant qu'un humain pour la sélection des essais cliniques ? Nous avons posé cette question dans notre étude la plus récente et je suis très heureux de partager nos résultats dans la prépublication :https://t.co/lhOPKCcudP
L'intégration du GPT4 dans les essais cliniques n'est pas...- Ozan Unlu (@OzanUnluMD) 9 février 2024
Résultats
Les chercheurs ont d'abord obtenu les évaluations structurées réalisées par le personnel de l'étude et les notes cliniques des deux dernières années.
Ils ont mis au point un flux de travail pour un système de réponse aux questions basé sur les notes cliniques et reposant sur l'architecture RAG et GPT-4V, qu'ils ont appelé RECTIFIER (RAG-Enabled Clinical Trial Infrastructure for Inclusion Exclusion Review).
Les notes de 100 patients ont été utilisées comme ensemble de données de développement, celles de 282 patients comme ensemble de données de validation et celles de 1894 patients comme ensemble de test.
Un clinicien expert a examiné en aveugle les dossiers des patients pour répondre aux questions d'éligibilité et déterminer les réponses de référence. Ces réponses ont ensuite été comparées à celles du personnel de l'étude et de RECTIFIER sur la base des critères suivants :
- Sensibilité - Capacité d'un test à identifier correctement les patients éligibles à l'essai (vrais positifs).
- Spécificité - Capacité d'un test à identifier correctement les patients qui ne sont pas éligibles pour l'essai (vrais négatifs).
- Précision - proportion globale de classifications correctes (à la fois vraies positives et vraies négatives).
- Coefficient de corrélation de Matthews (MCC) - Mesure utilisée pour évaluer la capacité du modèle à sélectionner ou à exclure une personne. Une valeur de 0 correspond à un jeu de pile ou face et une valeur de 1 correspond à 100% de réussite.
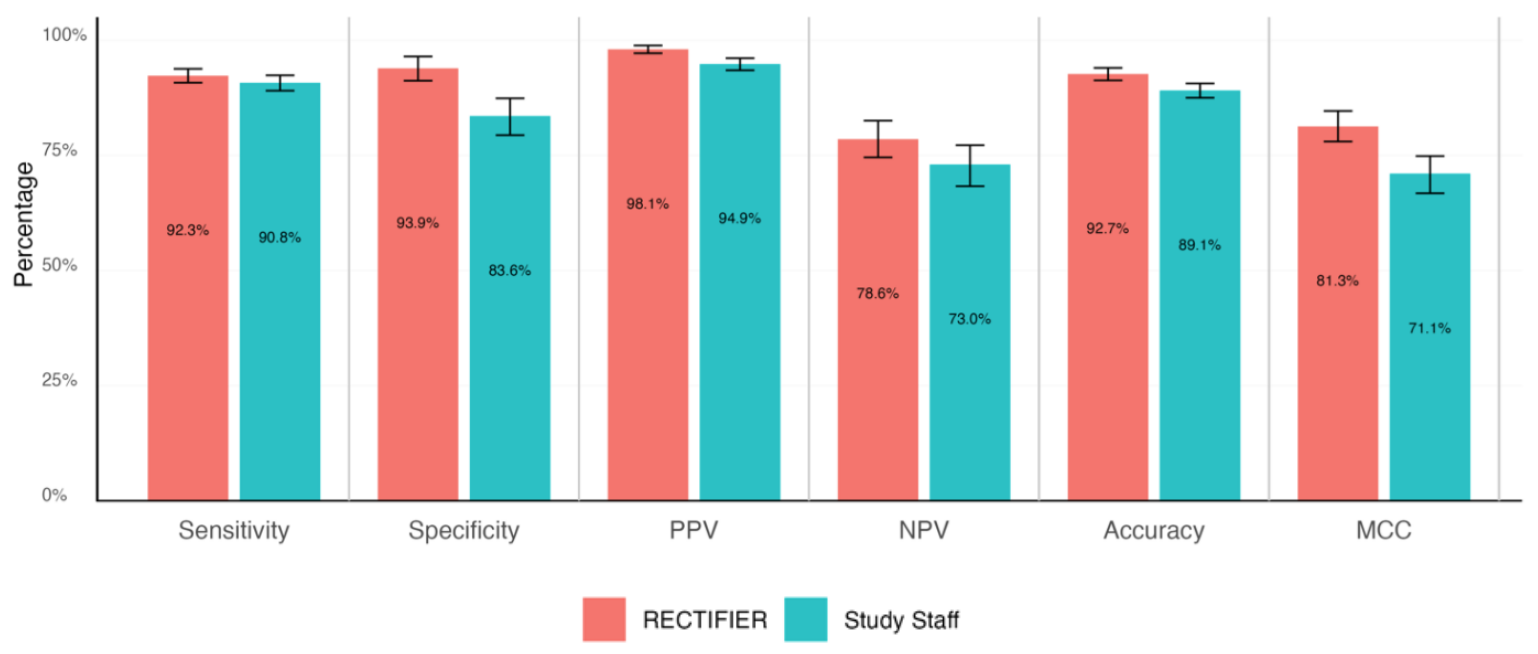
RECTIFIER a fait aussi bien, et dans certains cas mieux, que le personnel de l'étude. Le résultat le plus significatif de l'étude provient probablement de la comparaison des coûts.
Bien qu'aucun chiffre n'ait été donné concernant la rémunération du personnel de l'étude, celle-ci a dû être nettement supérieure au coût de l'utilisation du GPT-4V, qui variait entre $0,02 et $0,10 par patient. L'utilisation de l'IA pour évaluer un groupe de 1 000 candidats potentiels prendrait quelques minutes et coûterait environ $100.
Les chercheurs ont conclu que l'utilisation d'un modèle d'IA tel que GPT-4V avec RAG peut maintenir ou améliorer la précision de l'identification des candidats aux essais cliniques, et ce de manière plus efficace et beaucoup moins coûteuse que l'utilisation de personnel humain.
Ils ont souligné la nécessité de faire preuve de prudence avant de confier les soins médicaux à des systèmes automatisés, mais il semble que l'IA fera un meilleur travail que nous si elle est correctement dirigée.



