

Des chercheurs de l'université de San Diego et de l'université de New York ont mis au point V*, un algorithme de recherche guidée par LLM qui est bien meilleur que GPT-4V pour la compréhension du contexte et le ciblage précis d'éléments visuels spécifiques dans les images.
Les modèles multimodaux à langage étendu (MLLM) tels que le GPT-4V d'OpenAI nous ont impressionnés l'année dernière par leur capacité à répondre à des questions portant sur des images. Aussi impressionnant que soit le GPT-4V, il éprouve parfois des difficultés lorsque les images sont très complexes et passe souvent à côté de petits détails.
L'algorithme V* utilise un LLM de réponse aux questions visuelles (VQA) pour le guider dans l'identification de la zone de l'image sur laquelle se concentrer pour répondre à une requête visuelle. Les chercheurs appellent cette combinaison Show, sEArch, and telL (SEAL).
Si quelqu'un vous donne une image haute résolution et vous pose une question à son sujet, votre logique vous guidera pour zoomer sur une zone où vous avez le plus de chances de trouver l'élément en question. SEAL utilise V* pour analyser les images de la même manière.
Un modèle de recherche visuelle pourrait simplement diviser une image en blocs, zoomer sur chaque bloc et le traiter pour trouver l'objet en question, mais cette méthode est très inefficace sur le plan informatique.
Lorsqu'il reçoit une requête textuelle concernant une image, V* tente d'abord de localiser directement la cible de l'image. S'il n'y parvient pas, il demande au MLLM de faire preuve de bon sens pour identifier la zone de l'image dans laquelle la cible est la plus susceptible de se trouver.
Il concentre ensuite sa recherche sur cette zone, plutôt que de tenter une recherche "zoomée" sur l'ensemble de l'image.

Lorsque GPT-4V est invité à répondre à des questions sur une image qui nécessite un traitement visuel approfondi d'images à haute résolution, il éprouve des difficultés. SEAL utilisant V* obtient de bien meilleurs résultats.

À la question "Quel type de boisson pouvons-nous acheter dans ce distributeur ?", SEAL a répondu "Coca-Cola", tandis que GPT-4V a incorrectement deviné "Pepsi". le SEAL a répondu "Coca-Cola" tandis que le GPT-4V a deviné à tort "Pepsi".
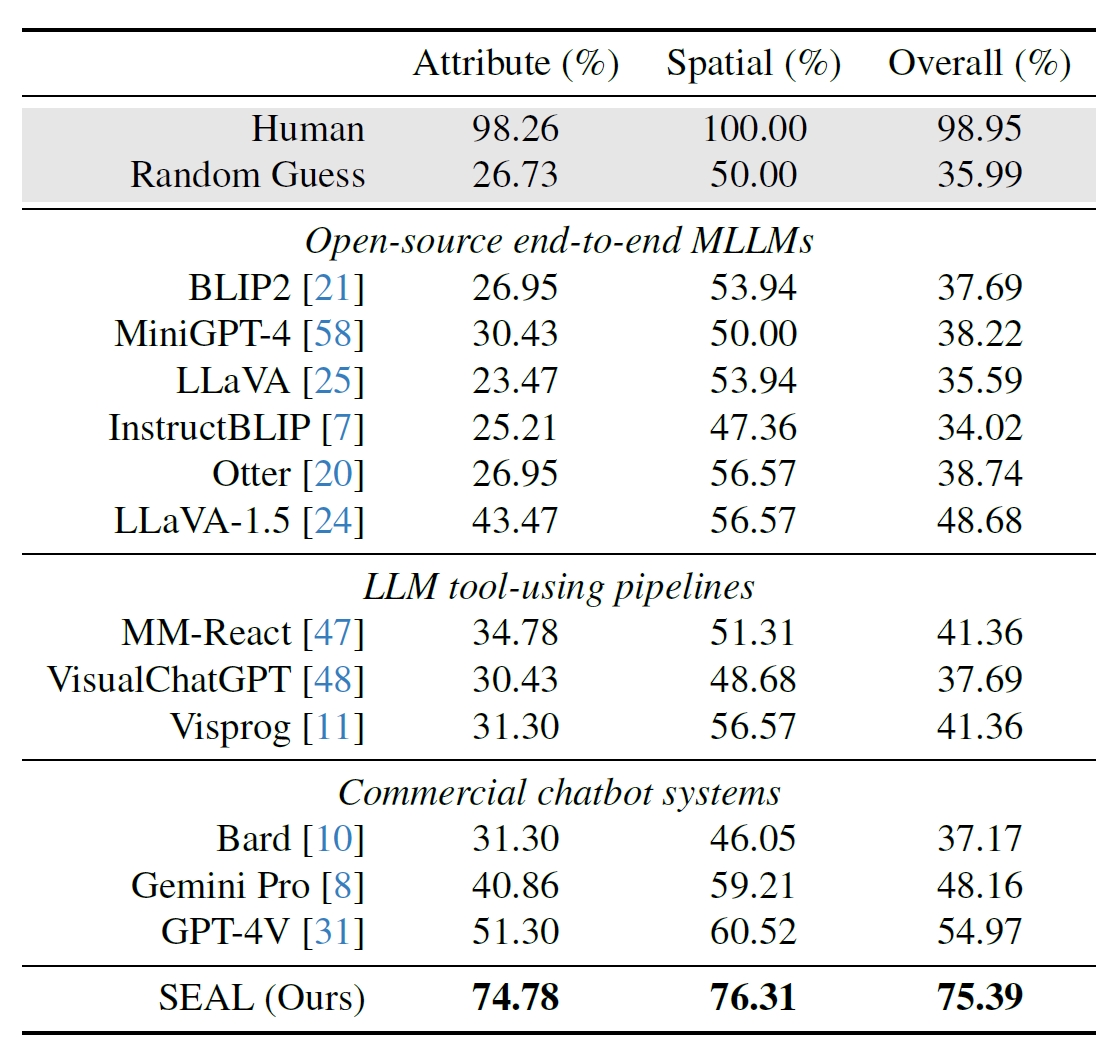
Les chercheurs ont utilisé 191 images haute résolution provenant de l'ensemble de données Segment Anything (SAM) de Meta et ont créé un test de référence pour comparer les performances de SEAL à celles d'autres modèles. Le benchmark V*Bench teste deux tâches : la reconnaissance d'attributs et le raisonnement sur les relations spatiales.
Les figures ci-dessous montrent la performance humaine comparée à des modèles open-source, des modèles commerciaux comme GPT-4V et SEAL. L'augmentation des performances de SEAL grâce à V* est particulièrement impressionnante car le MLLM sous-jacent qu'il utilise est LLaVa-7b, qui est beaucoup plus petit que GPT-4V.
Cette approche intuitive de l'analyse d'images semble très bien fonctionner, avec un certain nombre d'exemples impressionnants sur le site Web de la Commission européenne. Résumé du document sur GitHub.
Il sera intéressant de voir si d'autres MLLM, comme ceux d'OpenAI ou de Google, adoptent une approche similaire.
Lorsqu'on lui a demandé quelle boisson était vendue dans le distributeur de l'image ci-dessus, Bard de Google a répondu : "Il n'y a pas de distributeur au premier plan". Peut-être que Gemini Ultra fera mieux.
Pour l'instant, il semble que SEAL et son nouvel algorithme V* devancent de loin certains des plus grands modèles multimodaux lorsqu'il s'agit de questions visuelles.



