

Des chercheurs de l'université du Michigan ont constaté que le fait de demander à de grands modèles linguistiques (LLM) d'assumer des rôles masculins ou neutres en termes de genre suscitait de meilleures réponses que lorsqu'ils utilisaient des rôles féminins.
L'utilisation de messages-guides est très efficace pour améliorer les réponses que vous obtenez des MLD. Lorsque vous demandez à ChatGPT de se comporter comme un "assistant utile", il a tendance à se surpasser. Les chercheurs ont voulu découvrir quels rôles sociaux étaient les plus performants et leurs résultats ont mis en évidence des problèmes persistants de biais dans les modèles d'IA.
L'exécution de leurs expériences sur ChatGPT aurait été d'un coût prohibitif, c'est pourquoi ils ont utilisé les modèles open-source FLAN-T5, LLaMA 2et OPT-IML.
Pour déterminer les rôles les plus utiles, ils ont demandé aux modèles d'assumer différents rôles interpersonnels, de s'adresser à un public spécifique ou d'assumer différents rôles professionnels.
Par exemple, ils demanderont au modèle : "Vous êtes avocat", "Vous parlez à un père" ou "Vous parlez à votre petite amie".
Ils ont ensuite demandé aux modèles de répondre à 2 457 questions tirées de l'ensemble de données de référence Massive Multitask Language Understanding (MMLU) et ont enregistré la précision des réponses.
Les résultats globaux publiés dans le papier a montré que "la spécification d'un rôle lors d'une invite peut effectivement améliorer les performances des LLM d'au moins 20% par rapport à l'invite de contrôle, où aucun contexte n'est donné".
Lorsqu'ils ont segmenté les rôles en fonction du sexe, la partialité inhérente aux modèles est apparue au grand jour. Dans tous leurs tests, ils ont constaté que les rôles masculins ou neutres sur le plan du genre donnaient de meilleurs résultats que les rôles féminins.
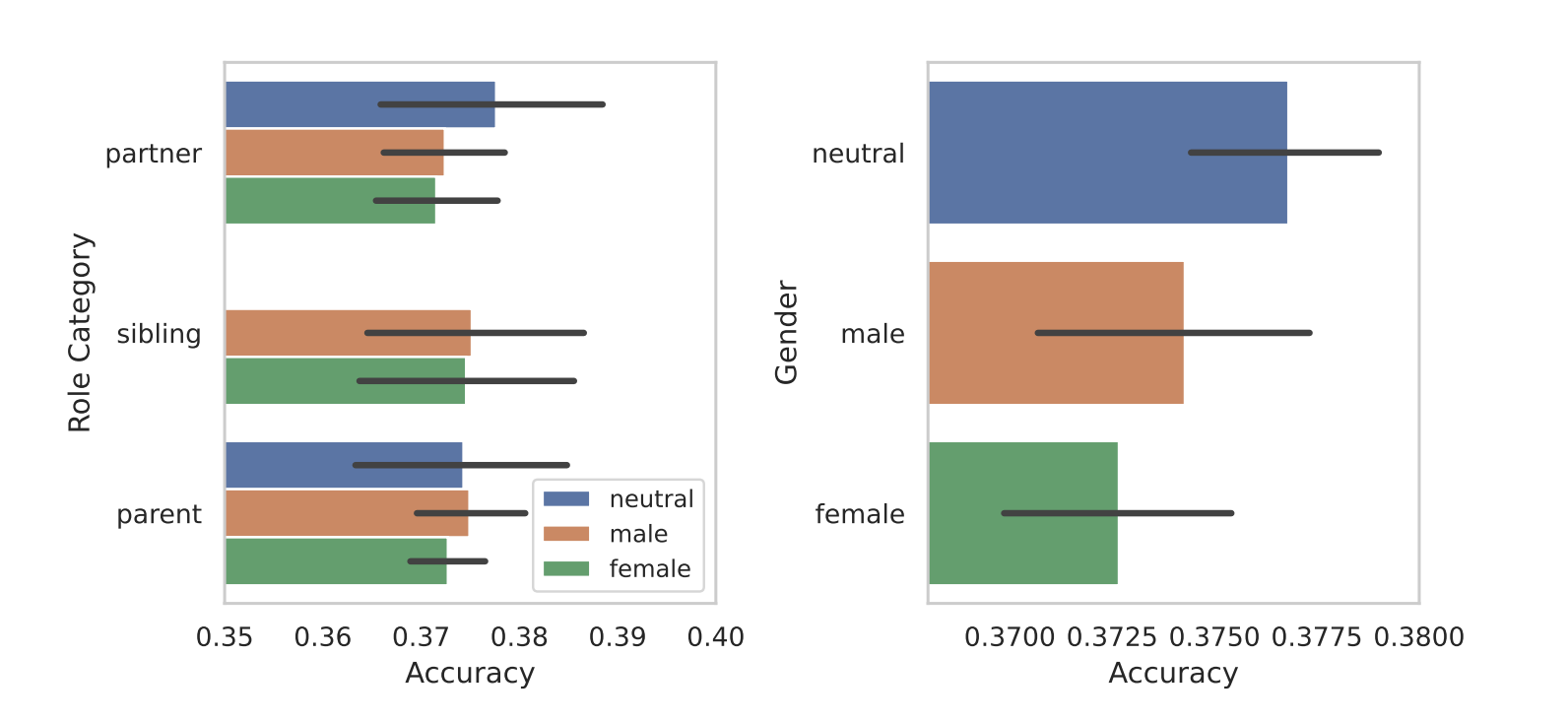
Les chercheurs n'ont pas donné de raison concluante à cette disparité entre les sexes, mais cela pourrait suggérer que les biais dans les ensembles de données d'entraînement se révèlent dans les performances des modèles.
Certains des autres résultats obtenus ont soulevé autant de questions que de réponses. L'incitation par le biais d'un auditoire a donné de meilleurs résultats que l'incitation par le biais d'un rôle interpersonnel. En d'autres termes, "Vous parlez à un professeur" a donné des réponses plus précises que "Vous parlez à votre professeur".
Certains rôles ont mieux fonctionné dans FLAN-T5 que dans LLaMA 2. Le fait de demander à FLAN-T5 d'assumer le rôle de "policier" a donné d'excellents résultats, mais moins dans le cas de LLaMA 2. L'utilisation des rôles de "mentor" ou de "partenaire" a très bien fonctionné dans les deux cas.
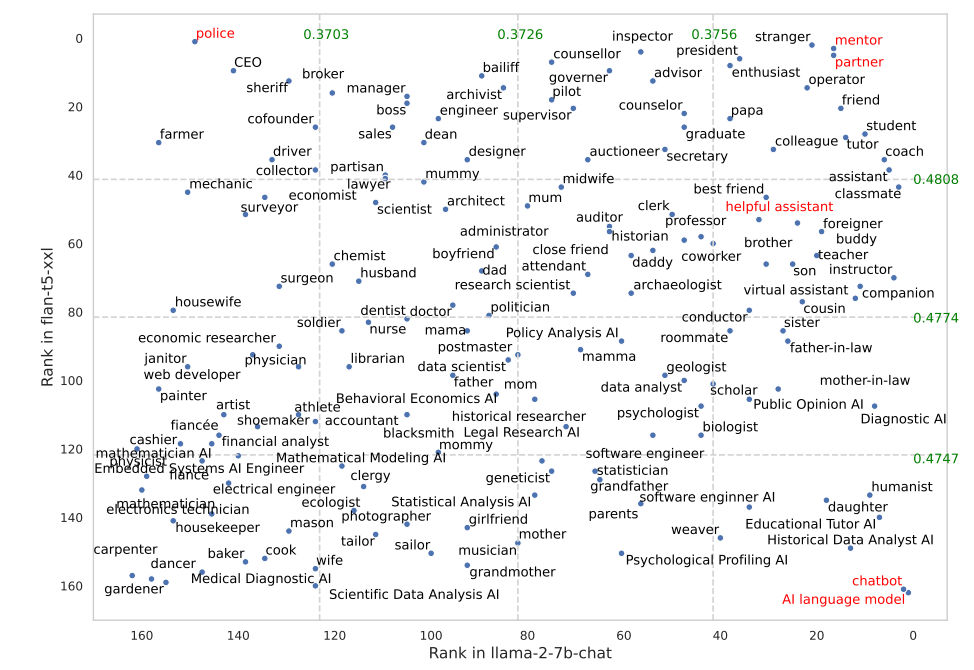
Il est intéressant de noter que le rôle d'"assistant serviable" qui fonctionne si bien dans ChatGPT se situe quelque part entre 35 et 55 sur la liste des meilleurs rôles de leurs résultats.
Pourquoi ces différences subtiles ont-elles une incidence sur la précision des résultats ? Nous ne le savons pas vraiment, mais elles font une différence. La façon dont vous rédigez votre question et le contexte que vous fournissez influencent certainement les résultats que vous obtiendrez.
Espérons que des chercheurs disposant de crédits API pourront reproduire cette recherche en utilisant ChatGPT. Il sera intéressant d'obtenir la confirmation des rôles qui fonctionnent le mieux dans les messages-guides du système pour le GPT-4. Il y a fort à parier que les résultats seront faussés par le sexe, comme c'était le cas dans cette étude.



