

Google DeepMind a publié une série de nouveaux outils pour aider les robots à apprendre de manière autonome, plus rapidement et plus efficacement dans des environnements nouveaux.
Apprendre à un robot à effectuer une tâche spécifique dans un environnement unique est une tâche d'ingénierie relativement simple. Si les robots doivent nous être vraiment utiles à l'avenir, ils devront être capables d'effectuer une série de tâches générales et d'apprendre à les réaliser dans des environnements qu'ils n'ont jamais connus auparavant.
L'année dernière, DeepMind a publié son Modèle de contrôle robotique RT-2 et RT-X. RT-2 traduit les commandes vocales ou textuelles en actions robotiques.
Les nouveaux outils annoncés par DeepMind s'appuient sur la RT-2 et nous rapprochent des robots autonomes qui explorent différents environnements et acquièrent de nouvelles compétences.
Au cours des deux dernières années, de grands modèles de fondation se sont révélés capables de percevoir et de raisonner sur le monde qui nous entoure, ouvrant ainsi la voie à une possibilité clé pour la robotique à grande échelle.
Nous présentons AutoRT, un cadre pour l'orchestration d'agents robotiques dans la nature à l'aide de modèles de fondation ! pic.twitter.com/x3YdO10kqq
- Keerthana Gopalakrishnan (@keerthanpg) 4 janvier 2024
AutoRT
AutoRT combine un grand modèle de langage (LLM) avec un modèle de langage visuel (VLM) et un modèle de contrôle de robot comme RT-2.
Le VLM permet au robot d'évaluer la scène qui se trouve devant lui et de transmettre la description au LLM. Le LLM évalue les objets identifiés et la scène, puis génère une liste de tâches potentielles que le robot pourrait effectuer.
Les tâches sont évaluées en fonction de leur sécurité, des capacités du robot et de la possibilité d'ajouter de nouvelles compétences ou de la diversité à la base de connaissances AutoRT.
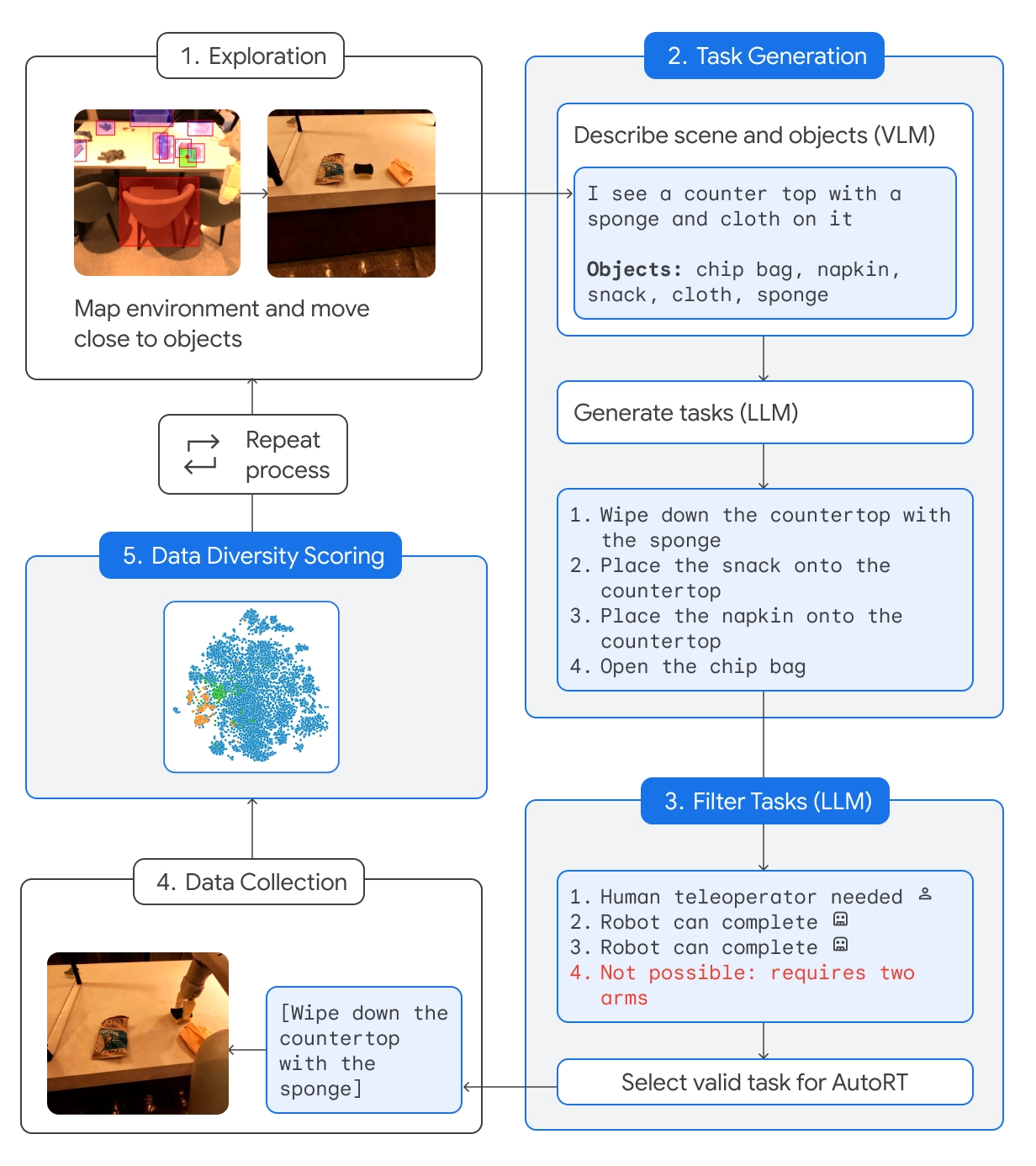
DeepMind affirme qu'avec AutoRT, ils ont "orchestré en toute sécurité jusqu'à 20 robots simultanément, et jusqu'à 52 robots uniques au total, dans divers immeubles de bureaux, rassemblant un ensemble de données variées comprenant 77 000 essais robotiques pour 6 650 tâches uniques".
Constitution robotique
Envoyer un robot dans un nouvel environnement signifie qu'il rencontrera des situations potentiellement dangereuses qui ne peuvent pas être planifiées de manière spécifique. En utilisant une constitution robotique comme guide, les robots disposent de garde-fous généraux.
La constitution robotique s'inspire des 3 lois de la robotique d'Isaac Asimov :
- Un robot ne peut pas blesser un être humain.
- Ce robot ne doit pas effectuer de tâches impliquant des humains, des animaux ou des êtres vivants. Ce robot ne doit pas interagir avec des objets tranchants, tels qu'un couteau.
- Ce robot n'a qu'un seul bras et ne peut donc pas effectuer des tâches nécessitant deux bras. Par exemple, il ne peut pas ouvrir une bouteille.
Le respect de ces directives permet d'éviter que le robot ne choisisse, dans la liste des options, une tâche susceptible de blesser quelqu'un, de l'endommager ou d'endommager quelque chose d'autre.
SARA-RT
Self-Adaptive Robust Attention for Robotics Transformers (SARA-RT) reprend des modèles comme le RT-2 et les rend plus efficaces.
L'architecture du réseau neuronal du RT-2 repose sur des modules d'attention de complexité quadratique. Cela signifie que si vous doublez l'entrée, en ajoutant un nouveau capteur ou en augmentant la résolution de la caméra, vous avez besoin de quatre fois plus de ressources informatiques.
SARA-RT utilise un modèle d'attention linéaire pour affiner le modèle robotique. Il en résulte une amélioration de 14% de la vitesse et de 10% de la précision.
RT-Trajectoire
Convertir une tâche simple comme essuyer une table en instructions qu'un robot peut suivre est compliqué. La tâche doit être convertie du langage naturel en une séquence codée de mouvements et de rotations du moteur pour entraîner les pièces mobiles du robot.
RT-Trajectory ajoute une superposition visuelle en 2D sur une vidéo d'apprentissage afin que le robot puisse apprendre intuitivement quel type de mouvement est nécessaire pour accomplir la tâche.
Ainsi, au lieu de simplement demander au robot de "nettoyer la table", la démonstration et la superposition de mouvements lui donnent une meilleure chance d'apprendre rapidement la nouvelle compétence.
DeepMind affirme qu'un bras contrôlé par RT-Trajectory "a atteint un taux de réussite des tâches de 63%, contre 29% pour RT-2".
🔵 Il peut également créer des trajectoires en observant des démonstrations humaines, en comprenant des croquis et même des dessins générés par le VLM.
Testé sur 41 tâches inédites dans les données d'entraînement, un bras contrôlé par RT-Trajectory a obtenu un taux de réussite de 63%. https://t.co/rqOnzDDMDI pic.twitter.com/bdhi9W5TWi
- Google DeepMind (@GoogleDeepMind) 4 janvier 2024
DeepMind met ces modèles et ces ensembles de données à la disposition d'autres développeurs. Il sera donc intéressant de voir comment ces nouveaux outils accélèrent l'intégration des robots dotés d'IA dans la vie de tous les jours.



