

Au début du mois, Google a fièrement annoncé que son modèle Gemini le plus puissant avait battu le GPT-4 lors des tests de référence MMLU (Massive Multitask Language Understanding). La nouvelle technique d'incitation de Microsoft permet à GPT-4 de reprendre la première place, mais avec une fraction de pour cent d'écart.
Outre le drame entourant sa vidéo de marketing, le Gemini de Google est une affaire importante pour l'entreprise et les résultats de son benchmark MMLU sont impressionnants. Mais Microsoft, le plus gros investisseur d'OpenAI, n'a pas attendu longtemps pour jeter de l'ombre sur les efforts de Google.
Le titre est que Microsoft a obtenu de GPT-4 qu'il batte les résultats MMLU de Gemini Ultra. En réalité, il n'a battu le score de 90,04% de Gemini que de 0,06%.
L'histoire de ce qui a rendu cela possible est plus passionnante que la surenchère que l'on observe sur ces tableaux de classement. Les nouvelles techniques d'incitation de Microsoft pourraient améliorer les performances des anciens modèles d'IA.
Vous vous souvenez que Gemini Ultra, la nouvelle version de Google, a battu GPT-4 pour devenir l'IA la plus performante ?
Microsoft vient de démontrer qu'avec une incitation appropriée, GPT-4 bat Gemini dans les tests de référence.
Il existe une grande marge de progression, même avec des modèles plus anciens. https://t.co/YQ5zJI6Gad pic.twitter.com/X3HFmXa30X
- Ethan Mollick (@emollick) 12 décembre 2023
Medprompt
Lorsque vous entendez des personnes parler de "pilotage" d'un modèle, cela signifie simplement qu'avec des instructions précises, vous pouvez guider un modèle pour qu'il produise un résultat plus conforme à ce que vous souhaitiez.
Microsoft a mis au point une combinaison de techniques d'incitation qui s'est avérée très efficace. Medprompt a débuté comme un projet visant à permettre au GPT-4 de fournir de meilleures réponses aux tests de référence médicaux tels que la suite de tests MultiMedQA.
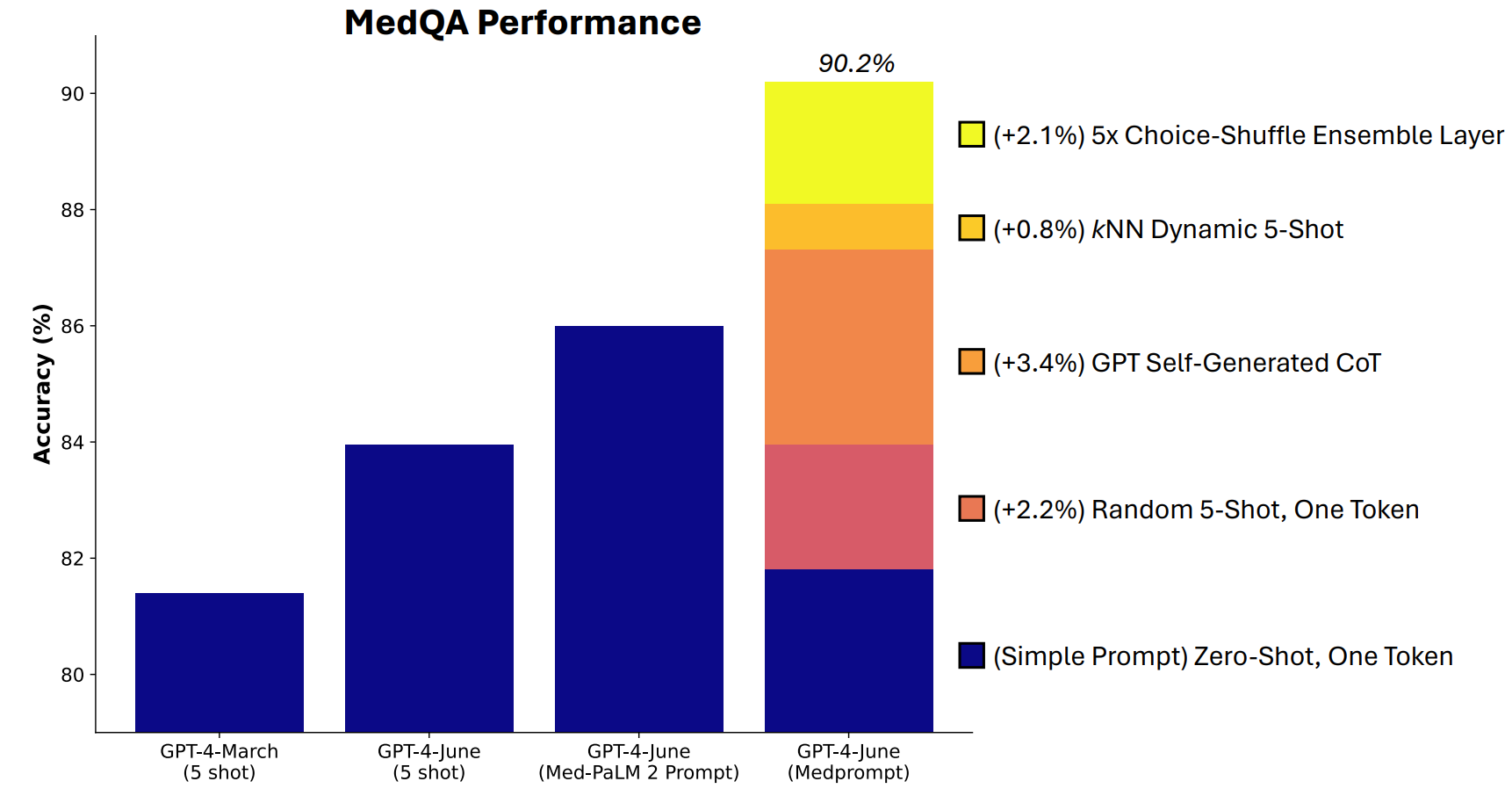
Les chercheurs de Microsoft ont pensé que si Medprompt fonctionnait bien dans les tests médicaux spécialisés, il pourrait également améliorer les performances généralistes de GPT-4. C'est ainsi que Microsoft et OpenAI ont repris le dessus sur Gemini Ultra avec GPT-4.
Comment fonctionne Medprompt ?
Medprompt est une combinaison de techniques d'incitation intelligentes. Il repose sur trois techniques principales.
Apprentissage dynamique à quelques coups (DFSL)
"L'apprentissage à quelques reprises" consiste à donner quelques exemples au GPT-4 avant de lui demander de résoudre un problème similaire. Lorsque vous voyez une référence comme "5-shot", cela signifie que le modèle a reçu 5 exemples. "Zero-shot" signifie qu'il a dû répondre sans aucun exemple.
Le document Medprompt explique que "pour des raisons de simplicité et d'efficacité, les exemples de quelques clichés utilisés dans l'incitation à une tâche particulière sont généralement fixes ; ils restent inchangés d'un exemple de test à l'autre".
Il en résulte que les exemples présentés aux modèles ne sont souvent pertinents ou représentatifs que dans les grandes lignes.
Si votre ensemble d'apprentissage est suffisamment grand, vous pouvez faire en sorte que le modèle examine tous les exemples et choisisse ceux qui sont sémantiquement similaires au problème qu'il doit résoudre. Il en résulte que les exemples d'apprentissage à court terme sont plus spécifiquement alignés sur un problème particulier.
Chaîne de pensée auto-générée (CoT)
La chaîne de pensée (CoT) est un excellent moyen d'orienter un LLM. Lorsque vous l'incitez à "réfléchir attentivement" ou à "résoudre le problème étape par étape", les résultats s'améliorent considérablement.
Vous pouvez être beaucoup plus précis dans la manière dont vous guidez la chaîne de pensée que le modèle doit suivre, mais cela implique une ingénierie manuelle prompte.
Les chercheurs ont découvert qu'ils "pouvaient simplement demander à GPT-4 de générer une chaîne de pensée pour les exemples de formation". Leur approche consiste essentiellement à dire à GPT-4 : "Voici une question, les choix de réponses et la bonne réponse. Quelle chaîne de pensée devrions-nous inclure dans un message-guide qui aboutirait à cette réponse ?
Choix de l'assemblage aléatoire
La plupart des tests de référence du MMLU sont des questions à choix multiples. Lorsqu'un modèle d'IA répond à ces questions, il peut être victime d'un biais de position. En d'autres termes, il peut favoriser l'option B au fil du temps, même si ce n'est pas toujours la bonne réponse.
Mélange des choix L'assemblage mélange les positions des options de réponse et demande à GPT-4 de répondre à nouveau à la question. Cette opération est répétée plusieurs fois, puis la réponse la plus cohérente est sélectionnée comme réponse finale.
C'est la combinaison de ces trois techniques qui a permis à Microsoft de jeter un peu d'ombre sur les résultats de Gemini. Il sera intéressant de voir quels résultats Gemini Ultra obtiendrait s'il utilisait une approche similaire.
Medprompt est passionnant parce qu'il montre que les anciens modèles peuvent être encore plus performants que nous le pensions si nous les sollicitons de manière intelligente. Toutefois, la puissance de traitement supplémentaire nécessaire pour ces étapes additionnelles risque de ne pas en faire une approche viable dans la plupart des scénarios.



