

Les grands modèles de langage (LLM) sont souvent induits en erreur par des biais ou un contexte non pertinent dans une invite. Les chercheurs de Meta ont trouvé un moyen apparemment simple d'y remédier.
Au fur et à mesure que les fenêtres contextuelles augmentent, les messages que nous envoyons au LLM peuvent devenir plus longs et plus détaillés. Les LLM sont devenus plus aptes à saisir les nuances ou les petits détails de nos messages, mais cela peut parfois les déconcerter.
Les premières méthodes d'apprentissage automatique utilisaient une approche "d'attention stricte" qui sélectionnait la partie la plus pertinente d'une entrée et ne répondait qu'à cette partie. Cela fonctionne bien lorsque vous essayez de légender une image, mais mal lorsque vous traduisez une phrase ou répondez à une question à plusieurs niveaux.
La plupart des LLM utilisent aujourd'hui une approche "d'attention douce", qui consiste à donner un sens à l'ensemble de l'invite et à attribuer un poids à chacun d'entre eux.
Meta propose une approche appelée Système 2 Attention (S2A) pour obtenir le meilleur des deux mondes. S2A utilise la capacité de traitement du langage naturel d'un LLM pour prendre votre message et éliminer les préjugés et les informations non pertinentes avant de commencer à travailler sur une réponse.
Voici un exemple.

S2A supprime les informations relatives à Max car elles ne sont pas pertinentes pour la question. S2A régénère une invite optimisée avant de commencer à travailler dessus. Les LLM sont notoirement mauvais en mathématiques Il est donc très utile de rendre l'invite moins confuse.
Les LLM font plaisir aux gens et sont heureux d'être d'accord avec vous, même si vous avez tort. S2A élimine tout biais dans une invite et ne traite ensuite que les parties pertinentes de l'invite. Cela permet de réduire ce que les chercheurs en IA appellent la "flagornerie", c'est-à-dire la propension d'un modèle d'IA à lécher les bottes.

S2A n'est en fait qu'une invite du système qui demande au LLM d'affiner un peu l'invite originale avant de se mettre au travail. Les résultats obtenus par les chercheurs pour les questions mathématiques, les questions factuelles et les questions longues sont impressionnants.
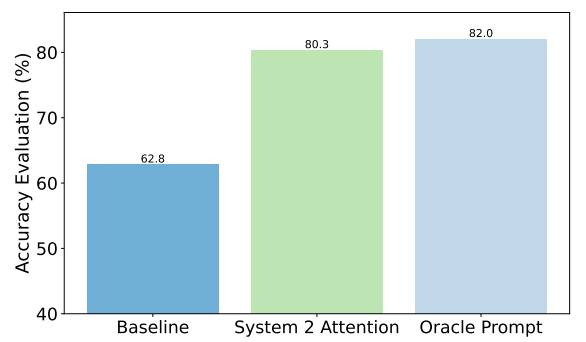
À titre d'exemple, voici les améliorations obtenues par S2A sur les questions factuelles. La base de référence était constituée par les réponses aux questions contenant des biais, tandis que l'invite Oracle était une invite idéale affinée par l'homme.
S2A se rapproche vraiment des résultats de l'invite Oracle et offre une amélioration de la précision de près de 50% par rapport à l'invite de base.
Quel est le problème ? Le prétraitement de l'invite originale avant d'y répondre ajoute des exigences de calcul supplémentaires au processus. Si l'invite est longue et contient beaucoup d'informations pertinentes, la régénération de l'invite peut entraîner des coûts importants.
Il est peu probable que les utilisateurs s'améliorent dans la rédaction d'invites bien conçues ; S2A peut donc être un bon moyen de contourner ce problème.
Meta intégrera-t-il S2A dans son Lamas modèle ? Nous ne le savons pas, mais vous pouvez vous-même tirer parti de l'approche S2A.
Si vous prenez soin d'omettre les opinions ou les suggestions suggestives dans vos messages-guides, vous aurez plus de chances d'obtenir des réponses précises de la part de ces modèles.



