

Des chercheurs ont présenté FANToM, un nouveau benchmark conçu pour tester et évaluer rigoureusement la compréhension et l'application de la théorie de l'esprit (ToM) par les grands modèles de langage (LLM).
La théorie de l'esprit fait référence à la capacité d'attribuer des croyances, des désirs et des connaissances à soi-même et aux autres, et de comprendre que les autres ont des croyances et des perspectives différentes des siennes.
La ToM est considérée comme un élément fondamental de la conscience que possèdent les animaux intelligents. Outre les humains, les primates tels que les orangs-outans, les gorilles et les chimpanzés sont considérés comme dotés de la ToM, de même que certains non-primates tels que les perroquets et les membres de la famille des corvidés (corbeaux).
Les modèles d'IA devenant de plus en plus complexes, les chercheurs en IA recherchent de nouvelles méthodes d'évaluation des capacités telles que la ToM.
Une nouvelle référence appelée FANToMcréé par des chercheurs de l'Allen Institute for AI, de l'université de Washington, de l'université Carnegie Mellon et de l'université nationale de Séoul, soumet des modèles d'apprentissage automatique à des scénarios dynamiques reflétant les interactions de la vie réelle.
Avec FANToM, les personnages entrent et sortent des conversations, ce qui met les modèles d'IA au défi de maintenir une compréhension précise de qui sait quoi à tout moment.
L'utilisation de grands modèles linguistiques (LLM) dans le cadre de FANToM a révélé que même les modèles les plus avancés ont du mal à maintenir un ToM cohérent.
Les performances des modèles étaient nettement inférieures à celles des participants humains, ce qui met en évidence les limites de l'IA dans la compréhension et la gestion d'interactions sociales complexes.
En fait, les humains ont dominé toutes les catégories, comme le montre le tableau ci-dessous.
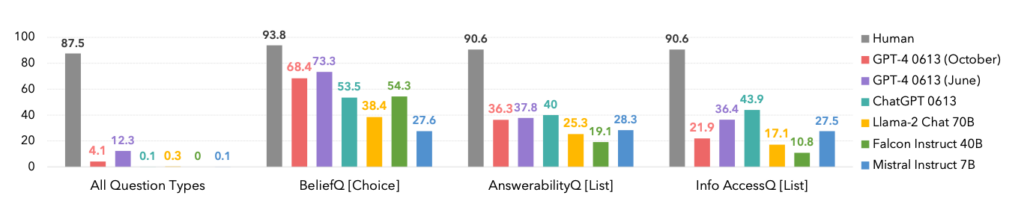
Il est intéressant de noter que la version d'octobre du modèle GPT-4 a été surclassée par une version antérieure de juin, ce qui pourrait confirmer les récentes anecdotes des utilisateurs selon lesquelles le modèle GPT-4 est plus performant que le modèle GPT-4. ChatGPT s'aggrave.
FANToM a également révélé des techniques permettant d'améliorer le ToM LLM, telles que le raisonnement par chaîne de pensée et d'autres méthodes de mise au point.
Toutefois, l'écart entre les compétences de l'IA et celles des humains en matière de gestion des connaissances reste important.
L'IA progresse vers des compétences linguistiques comparables à celles de l'homme
Dans un domaine quelque peu connexe mais distinct publiée dans NatureDes scientifiques ont mis au point un réseau neuronal capable de généraliser le langage à l'instar de l'homme.
Ce nouveau réseau neuronal a fait preuve d'une capacité impressionnante à intégrer des mots nouvellement appris dans son vocabulaire existant. Il pouvait ensuite utiliser ces mots dans différents contextes, une compétence cognitive connue sous le nom de généralisation systématique.
Les êtres humains font naturellement preuve d'une généralisation systématique, incorporant sans difficulté un nouveau vocabulaire à leur répertoire.
Par exemple, lorsque quelqu'un apprend le terme "photobomb", il peut l'appliquer à diverses situations presque immédiatement. De nouveaux termes d'argot apparaissent en permanence et les êtres humains les intègrent naturellement à leur vocabulaire.
Les chercheurs ont soumis leur propre réseau neuronal et ChatGPT à une série de tests et ont constaté que ChatGPT était moins performant que le modèle personnalisé.
Si les LLM tels que ChatGPT excellent dans de nombreux scénarios de conversation, ils présentent des incohérences et des lacunes notables dans d'autres, un problème auquel ce nouveau réseau neuronal s'attaque.
Pour étudier cet aspect de la communication linguistique, des chercheurs ont mené une expérience avec 25 participants humains, évaluant leur capacité à appliquer des mots nouvellement appris dans différents contextes. Les sujets ont été initiés à un pseudo-langage composé de mots absurdes représentant diverses actions et règles.
Après une phase d'entraînement, les participants ont excellé dans l'application de ces règles abstraites à de nouvelles situations, faisant preuve d'une généralisation systématique.
Lorsque le réseau neuronal nouvellement développé a été exposé à cette tâche, il a reproduit les performances humaines. Cependant, lorsque ChatGPT a été soumis au même défi, il a éprouvé des difficultés considérables, échouant entre 42 et 86% du temps, en fonction de la tâche spécifique.
Ce résultat est significatif pour deux raisons. Tout d'abord, on peut affirmer que ce nouveau réseau neuronal a effectivement surpassé le GPT-4 dans cette tâche spécifique, ce qui est déjà impressionnant. Deuxièmement, cette étude présente de nouvelles méthodes pour enseigner aux modèles d'IA comment généraliser un nouveau langage comme les humains.
Comme l'explique Elia Bruni, spécialiste du traitement du langage naturel à l'université d'Osnabrück, en Allemagne, "l'introduction de la systématicité dans les réseaux neuronaux est un enjeu de taille".
Ensemble, ces deux études proposent de nouvelles approches pour former des modèles d'IA plus intelligents, capables de rivaliser avec les humains dans des domaines essentiels tels que la linguistique et la théorie de l'esprit.



