

Un equipo de investigadores de la Universidad de Nueva York ha logrado avances en la descodificación neural del habla, lo que nos acerca a un futuro en el que las personas que han perdido la capacidad de hablar puedan recuperar su voz.
En estudiarpublicado en Naturaleza Inteligencia Artificialpresenta un novedoso marco de aprendizaje profundo que traduce con precisión las señales cerebrales en habla inteligible.
Las personas con lesiones cerebrales debidas a accidentes cerebrovasculares, enfermedades degenerativas o traumatismos físicos pueden utilizar estos sistemas para comunicarse descodificando sus pensamientos o su discurso a partir de señales neuronales.
El sistema del equipo de la NYU implica un modelo de aprendizaje profundo que mapea las señales de electrocorticografía (ECoG) del cerebro a las características del habla, como el tono, el volumen y otros contenidos espectrales.
La segunda etapa consiste en un sintetizador neural del habla que convierte las características del habla extraídas en un espectrograma audible, que luego puede transformarse en una forma de onda del habla.
Finalmente, esa forma de onda puede convertirse en voz sintetizada de sonido natural.
Nuevo artículo publicado hoy en @NatMachIntelldonde mostramos una robusta decodificación neural del habla en 48 pacientes. https://t.co/rNPAMr4l68 pic.twitter.com/FG7QKCBVzp
- Adeen Flinker 🇮🇱🇺🇦🎗️ (@adeenflinker) 9 de abril de 2024
Cómo funciona el estudio
Este estudio consiste en entrenar un modelo de inteligencia artificial capaz de alimentar un dispositivo de síntesis del habla que permita hablar a las personas con pérdida del habla mediante impulsos eléctricos cerebrales.
He aquí cómo funciona con más detalle:
1. Recopilación de datos cerebrales
El primer paso consiste en recopilar los datos brutos necesarios para entrenar el modelo de descodificación del habla. Los investigadores trabajaron con 48 participantes sometidos a neurocirugía por epilepsia.
Durante el estudio, se pidió a estos participantes que leyeran cientos de frases en voz alta mientras se registraba su actividad cerebral mediante rejillas de ECoG.
Estas rejillas se colocan directamente sobre la superficie del cerebro y captan las señales eléctricas de las regiones cerebrales implicadas en la producción del habla.
2. Mapeo de señales cerebrales para el habla
A partir de los datos del habla, los investigadores desarrollaron un sofisticado modelo de inteligencia artificial que asigna las señales cerebrales registradas a características específicas del habla, como el tono, el volumen y las frecuencias únicas que componen los distintos sonidos del habla.
3. Sintetizar el habla a partir de características
El tercer paso se centra en convertir las características del habla extraídas de las señales cerebrales en habla audible.
Los investigadores utilizaron un sintetizador de voz especial que toma las características extraídas y genera un espectrograma, una representación visual de los sonidos del habla.
4. Evaluación de los resultados
Los investigadores compararon el habla generada por su modelo con el habla original de los participantes.
Utilizaron métricas objetivas para medir la similitud entre ambos y descubrieron que el discurso generado se ajustaba al contenido y el ritmo del original.
5. Pruebas con palabras nuevas
Para asegurarse de que el modelo puede manejar palabras nuevas que no ha visto antes, se omitieron intencionadamente ciertas palabras durante la fase de entrenamiento del modelo, y luego se probó el rendimiento del modelo con estas palabras no vistas.
La capacidad del modelo para descodificar con precisión incluso palabras nuevas demuestra su potencial para generalizar y manejar diversos patrones del habla.
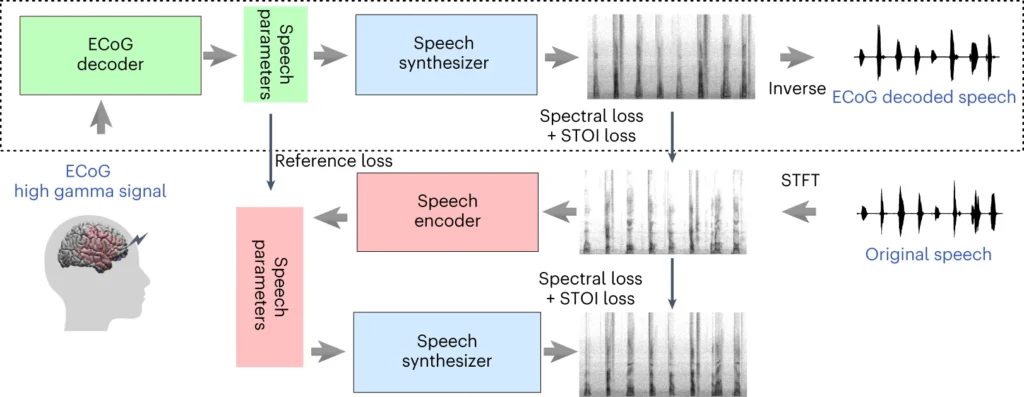
La parte superior del diagrama describe el proceso de conversión de las señales cerebrales en habla. En primer lugar, un descodificador convierte estas señales en parámetros del habla a lo largo del tiempo. A continuación, un sintetizador crea imágenes sonoras (espectrogramas) a partir de esos parámetros. Otra herramienta vuelve a transformar estas imágenes en ondas sonoras.
La última sección trata de un sistema que ayuda a entrenar el decodificador de señales del cerebro imitando el habla. Toma una imagen sonora, la convierte en parámetros del habla y los utiliza para crear una nueva imagen sonora. Esta parte del sistema aprende de los sonidos reales del habla para mejorar.
Tras el entrenamiento, sólo es necesario el proceso superior para convertir las señales cerebrales en habla.
Una ventaja clave del sistema de la NYU es su capacidad para lograr una descodificación del habla de alta calidad sin necesidad de matrices de electrodos de altísima densidad, poco prácticas para un uso a largo plazo.
En esencia, ofrece una solución más ligera y portátil.
Otro logro es la descodificación satisfactoria del habla procedente tanto del hemisferio izquierdo como del derecho del cerebro, lo cual es importante para pacientes con daño cerebral en un lado del cerebro.
Convertir pensamientos en voz mediante la IA
El estudio de la NYU se basa en investigaciones anteriores sobre descodificación neural del habla e interfaces cerebro-ordenador (BCI).
En 2023, un equipo de la Universidad de California, en San Francisco, permitió a un superviviente de un ictus paralítico generar frases a una velocidad de 78 palabras por minuto utilizando una BCI que sintetizaba tanto vocalizaciones como expresiones faciales a partir de señales cerebrales.
Otros estudios recientes han explorado el uso de la IA para interpretar diversos aspectos del pensamiento humano a partir de la actividad cerebral. Los investigadores han demostrado la capacidad de generar imágenes, texto e incluso música a partir de datos de resonancias magnéticas y electroencefalogramas (EEG) tomados del cerebro.
Por ejemplo, un estudio de la Universidad de Helsinki utilizaron señales EEG para guiar una red generativa adversarial (GAN) en la producción de imágenes faciales que coincidían con los pensamientos de los participantes.
Meta AI también desarrolló una técnica para descodificar parcialmente lo que alguien estaba escuchando mediante ondas cerebrales recogidas de forma no invasiva.
Oportunidades y retos
El método de la NYU utiliza electrodos más accesibles y clínicamente viables que los métodos anteriores, lo que lo hace más accesible.
Aunque esto es apasionante, hay importantes obstáculos que superar si queremos presenciar un uso generalizado.
Por un lado, la recopilación de datos cerebrales de alta calidad es una tarea compleja y laboriosa. Las diferencias individuales en la actividad cerebral dificultan la generalización, lo que significa que un modelo entrenado para un grupo de participantes puede no funcionar bien para otro.
No obstante, el estudio de la NYU representa un paso adelante en esta dirección al demostrar una descodificación del habla de gran precisión utilizando haces de electrodos más ligeros.
De cara al futuro, el equipo de la NYU pretende perfeccionar sus modelos de descodificación del habla en tiempo real, lo que nos acercará al objetivo final de permitir conversaciones naturales y fluidas a las personas con deficiencias del habla.
También pretenden adaptar el sistema a dispositivos inalámbricos implantables que puedan utilizarse en la vida cotidiana.



