

Microsoft ha lanzado Phi-3 Mini, un minúsculo modelo de lenguaje que forma parte de la estrategia de la empresa para desarrollar modelos de IA ligeros y con funciones específicas.
La progresión de los modelos lingüísticos ha ido acompañada de parámetros, conjuntos de datos de entrenamiento y ventanas de contexto cada vez mayores. El aumento del tamaño de estos modelos ha proporcionado capacidades más potentes, pero a un coste.
El método tradicional para entrenar a un LLM consiste en hacer que consuma cantidades ingentes de datos, lo que requiere enormes recursos informáticos. Se calcula que entrenar un LLM como GPT-4, por ejemplo, ha llevado unos 3 meses y ha costado más de $21m.
GPT-4 es una gran solución para tareas que requieren un razonamiento complejo, pero excesiva para tareas más sencillas como la creación de contenidos o un chatbot de ventas. Es como utilizar una navaja suiza cuando lo único que necesitas es un simple abrecartas.
Con sólo 3,8 B de parámetros, Phi-3 Mini es diminuto. Aun así, Microsoft afirma que es una solución ligera y de bajo coste ideal para tareas como resumir un documento, extraer información de informes y redactar descripciones de productos o mensajes en redes sociales.
Las cifras de referencia de MMLU muestran que Phi-3 Mini y los modelos Phi de mayor tamaño aún por lanzar superan a modelos más grandes como Mistral 7B y Gemma 7B.
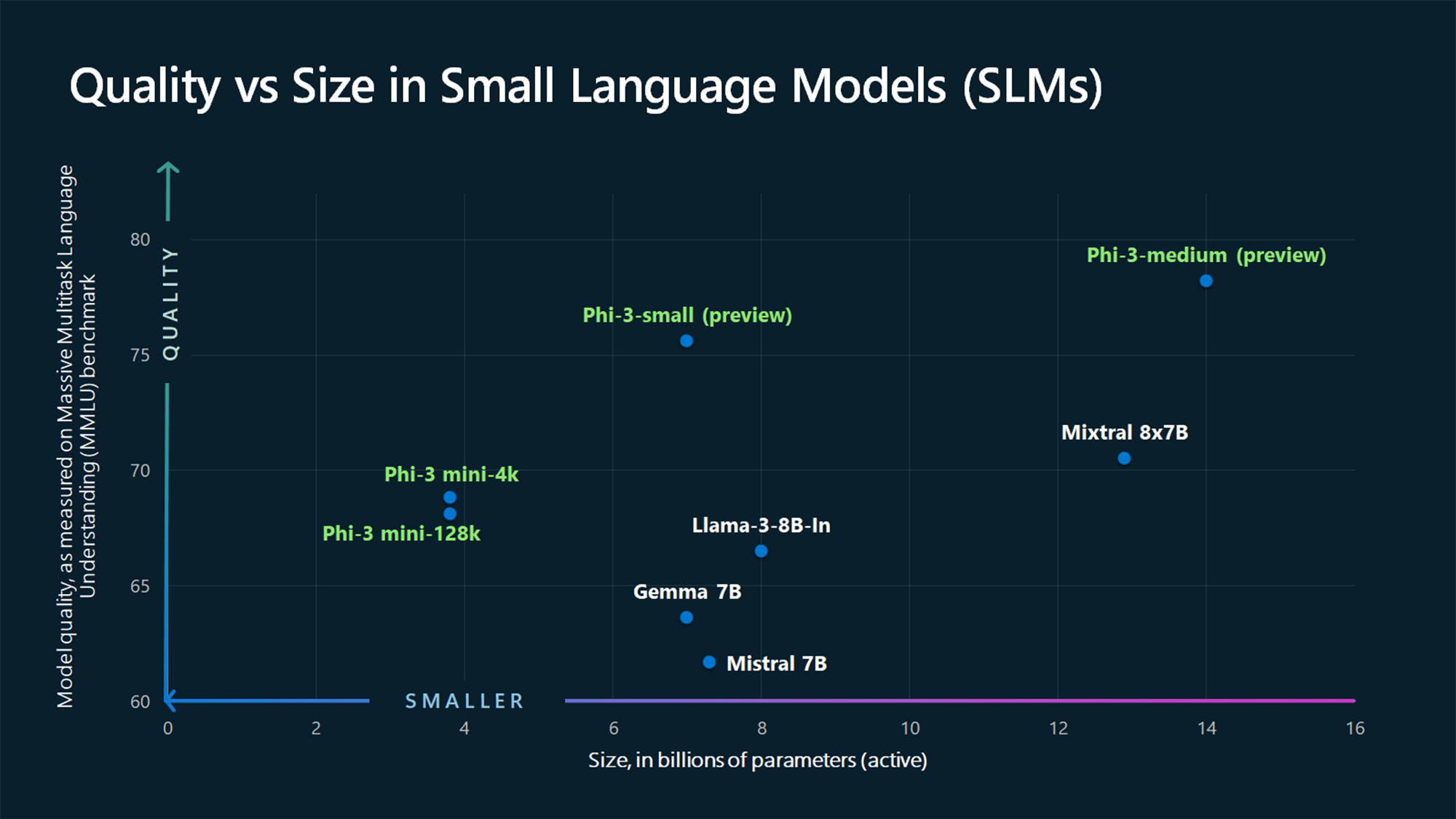
Microsoft afirma que Phi-3-small (7B parámetros) y Phi-3-medium (14B parámetros) estarán disponibles en el Azure AI Model Catalog "en breve".
Los modelos más grandes, como el GPT-4, siguen siendo el estándar de oro y probablemente podemos esperar que el GPT-5 sea aún mayor.
Las SLM como Phi-3 Mini ofrecen algunas ventajas importantes que los modelos más grandes no tienen. Los SLM son más baratos de ajustar, requieren menos computación y pueden funcionar en el dispositivo incluso en situaciones en las que no se dispone de acceso a Internet.
El despliegue de un SLM en el perímetro reduce la latencia y maximiza la privacidad, ya que no es necesario enviar datos de un lado a otro de la nube.
Aquí está Sebastien Bubeck, vicepresidente de investigación GenAI en Microsoft AI con una demostración de Phi-3 Mini. Es superrápido e impresionante para un modelo tan pequeño.
phi-3 ya está aquí, y es... bueno :-).
He hecho una breve demostración para que os hagáis una idea de lo que phi-3-mini (3.8B) puede hacer. Estén atentos al lanzamiento de pesos abiertos y a más anuncios mañana por la mañana.
(Y, por supuesto, esto no estaría completo sin la habitual tabla de puntos de referencia). pic.twitter.com/AWA7Km59rp
- Sebastien Bubeck (@SebastienBubeck) 23 de abril de 2024
Datos sintéticos conservados
Phi-3 Mini es el resultado de descartar la idea de que grandes cantidades de datos son la única forma de entrenar un modelo.
Sebastien Bubeck, vicepresidente de investigación de IA generativa de Microsoft, preguntó: "En lugar de entrenar sólo con datos web sin procesar, ¿por qué no se buscan datos de altísima calidad?".
Ronen Eldan, experto en aprendizaje automático de Microsoft Research, estaba leyendo cuentos a su hija cuando se preguntó si un modelo lingüístico podría aprender utilizando sólo palabras que un niño de 4 años pudiera entender.
Esto les llevó a un experimento en el que crearon un conjunto de datos a partir de 3.000 palabras. Utilizando solo este vocabulario limitado, incitaron a un LLM a crear millones de cuentos infantiles cortos que se recopilaron en un conjunto de datos llamado TinyStories.
A continuación, los investigadores utilizaron TinyStories para entrenar un modelo extremadamente pequeño de 10 millones de parámetros que, posteriormente, fue capaz de generar "narraciones fluidas con una gramática perfecta".
Continuaron iterando y ampliando este enfoque de generación de datos sintéticos para crear conjuntos de datos sintéticos más avanzados, pero cuidadosamente seleccionados y filtrados, que finalmente se utilizaron para entrenar Phi-3 Mini.
El resultado es un modelo diminuto que será más asequible y ofrecerá un rendimiento comparable al de GPT-3.5.
Con modelos más pequeños pero más capaces, las empresas dejarán de recurrir por defecto a grandes LLM como GPT-4. También podríamos ver pronto soluciones en las que un LLM se encargue del trabajo pesado, pero delegue tareas más sencillas en modelos ligeros. También podríamos ver pronto soluciones en las que un LLM se encargue del trabajo pesado pero delegue las tareas más sencillas en modelos ligeros.



