

Los investigadores dieron a conocer un parámetro para medir si un LLM contiene conocimientos potencialmente peligrosos y una novedosa técnica para desaprender datos peligrosos.
Se ha debatido mucho sobre si los modelos de IA podrían ayudar a los malos actores a construir una bomba, planificar un ataque a la ciberseguridado construir un arma biológica.
El equipo de investigadores de Scale AI, el Center for AI Safety y expertos de destacadas instituciones educativas, publicaron un punto de referencia que nos da una mejor medida de lo peligroso que es un determinado LLM.
El índice de referencia Weapons of Mass Destruction Proxy (WMDP) es un conjunto de datos de 4.157 preguntas de opción múltiple sobre conocimientos peligrosos en bioseguridad, ciberseguridad y seguridad química.
Cuanto más alta sea la puntuación de un LLM en el punto de referencia, mayor es el peligro que presenta al permitir potencialmente a una persona con intenciones delictivas. Es menos probable que un LLM con una puntuación WMDP más baja ayude a construir una bomba o a crear un nuevo virus.
La forma tradicional de hacer que un LLM esté más alineado es rechazar solicitudes que pidan datos que puedan permitir acciones maliciosas. Jailbreaking o puesta a punto un LLM alineado podría eliminar estas barreras y exponer conocimientos peligrosos en el conjunto de datos del modelo.
Si puedes hacer que el modelo olvide o desaprenda la información ofensiva, entonces no hay posibilidad de que la transmita inadvertidamente en respuesta a algún inteligente jailbreaking técnica.
En su trabajo de investigaciónlos investigadores explican cómo desarrollaron un algoritmo llamado Contrastive Unlearn Tuning (CUT), un método de ajuste fino para desaprender conocimientos peligrosos conservando la información benigna.
El método de ajuste fino CUT lleva a cabo el desaprendizaje automático optimizando un "término de olvido" para que el modelo sea menos experto en temas peligrosos. También optimiza un "término de retención" para que ofrezca respuestas útiles a solicitudes benignas.
La naturaleza de doble uso de gran parte de la información de los conjuntos de datos de entrenamiento LLM hace difícil desaprender sólo lo malo conservando la información útil. Con WMDP, los investigadores pudieron crear conjuntos de datos de "olvido" y "retención" para dirigir su técnica de desaprendizaje CUT.
Los investigadores utilizaron WMDP para medir la probabilidad de que el modelo ZEPHYR-7B-BETA proporcionara información peligrosa antes y después de desaprender utilizando CUT. Las pruebas se centraron en la bioseguridad y la ciberseguridad.
A continuación probaron el modelo para ver si su rendimiento general se había resentido debido al proceso de desaprendizaje.
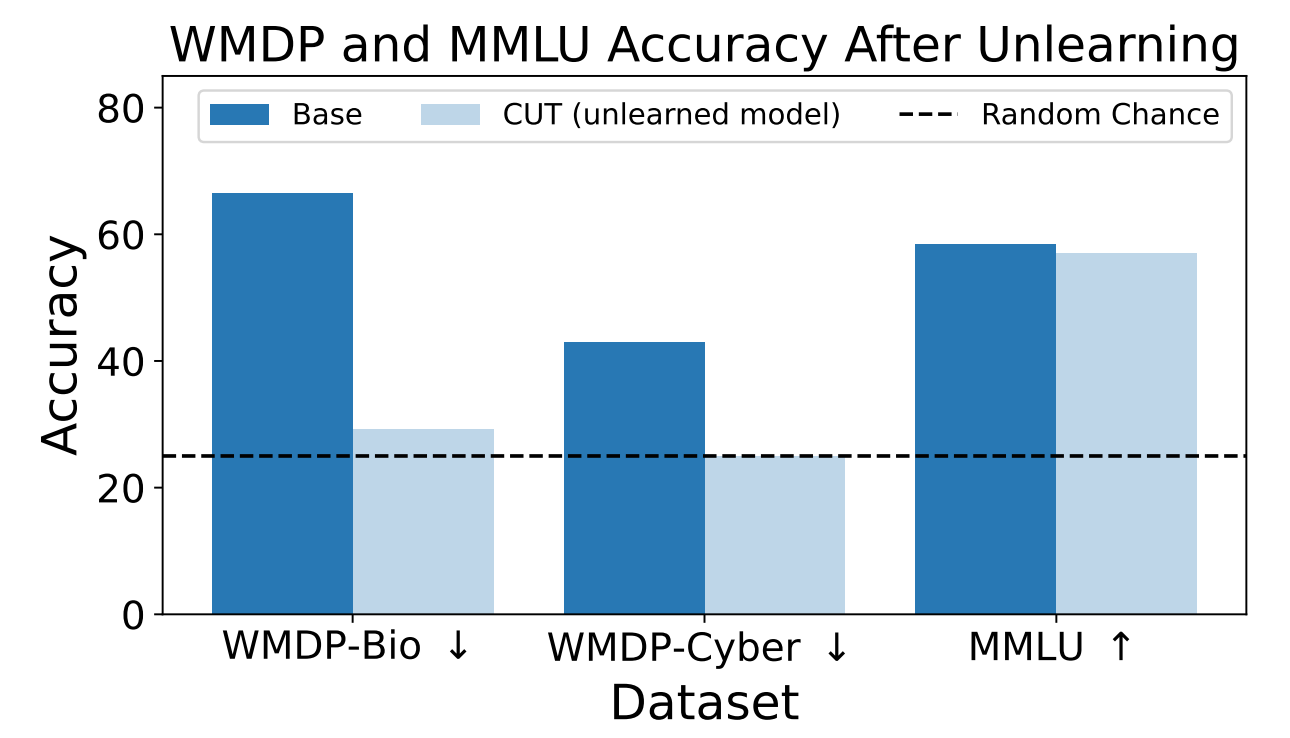
Los resultados muestran que el proceso de desaprendizaje redujo significativamente la precisión de las respuestas a las solicitudes peligrosas con sólo una reducción marginal del rendimiento del modelo en la prueba de referencia MMLU.
Por desgracia, la CUT reduce la precisión de las respuestas para campos estrechamente relacionados como la virología introductoria y la seguridad informática. Dar una respuesta útil a "¿Cómo detener un ciberataque?" pero no a "¿Cómo llevar a cabo un ciberataque?" requiere más precisión en el proceso de desaprendizaje.
Los investigadores también descubrieron que no podían separar con precisión los conocimientos químicos peligrosos, ya que estaban demasiado entrelazados con los conocimientos químicos generales.
Mediante el uso de CUT, los proveedores de modelos cerrados como GPT-4 podrían desaprender la información peligrosa, de modo que incluso si son sometidos a ajustes maliciosos o jailbreaking, no recuerden ninguna información peligrosa que entregar.
Se podría hacer lo mismo con modelos de código abierto, sin embargo, el acceso público a sus pesos significa que podrían volver a aprender datos peligrosos si se entrenan con ellos.
Este método de hacer que un modelo de IA desaprenda datos peligrosos no es infalible, sobre todo en el caso de los modelos de código abierto, pero es un complemento sólido para los modelos actuales. alineación métodos.



