

Los modelos actuales de IA son capaces de hacer muchas cosas inseguras o indeseables. La supervisión humana y la retroalimentación mantienen a estos modelos alineados, pero ¿qué ocurrirá cuando estos modelos lleguen a ser más inteligentes que nosotros?
OpenAI afirma que es posible que veamos la creación de una IA más inteligente que los humanos en los próximos 10 años. Junto con el aumento de la inteligencia viene el riesgo de que los humanos ya no sean capaces de supervisar estos modelos.
El equipo de investigación Superalignment de OpenAI se centra en prepararse para esa eventualidad. El equipo se puso en marcha en julio de este año y está codirigido por Ilya Sutskever, que ha permanecido en la sombra desde que se fundó Sam Altman. despido y posterior recontratación.
La justificación del proyecto fue puesta en un contexto aleccionador por OpenAI, que reconoció que "actualmente, no tenemos una solución para dirigir o controlar una IA potencialmente superinteligente, y evitar que se vuelva rebelde".
Pero, ¿cómo prepararse para controlar algo que aún no existe? El equipo de investigación acaba de publicar su primeros resultados experimentales ya que trata de hacer precisamente eso.
Generalización de débil a fuerte
Por ahora, los humanos siguen estando en una posición de inteligencia más fuerte que los modelos de IA. Los modelos como GPT-4 se dirigen o alinean mediante la retroalimentación humana del aprendizaje por refuerzo (RLHF). Cuando los resultados de un modelo no son los deseados, el instructor humano le dice: "No hagas eso", y recompensa al modelo con una afirmación del rendimiento deseado.
Por ahora, esto funciona porque entendemos bastante bien cómo funcionan los modelos actuales y somos más inteligentes que ellos. Cuando los futuros científicos de datos humanos tengan que entrenar a una IA superinteligente, los papeles de la inteligencia se invertirán.
Para simular esta situación, OpenAI decidió utilizar modelos GPT antiguos, como el GPT-2, para entrenar modelos más potentes, como el GPT-4. El GPT-2 simularía al futuro entrenador humano intentando afinar un modelo más inteligente. GPT-2 simularía al futuro entrenador humano tratando de afinar un modelo más inteligente.
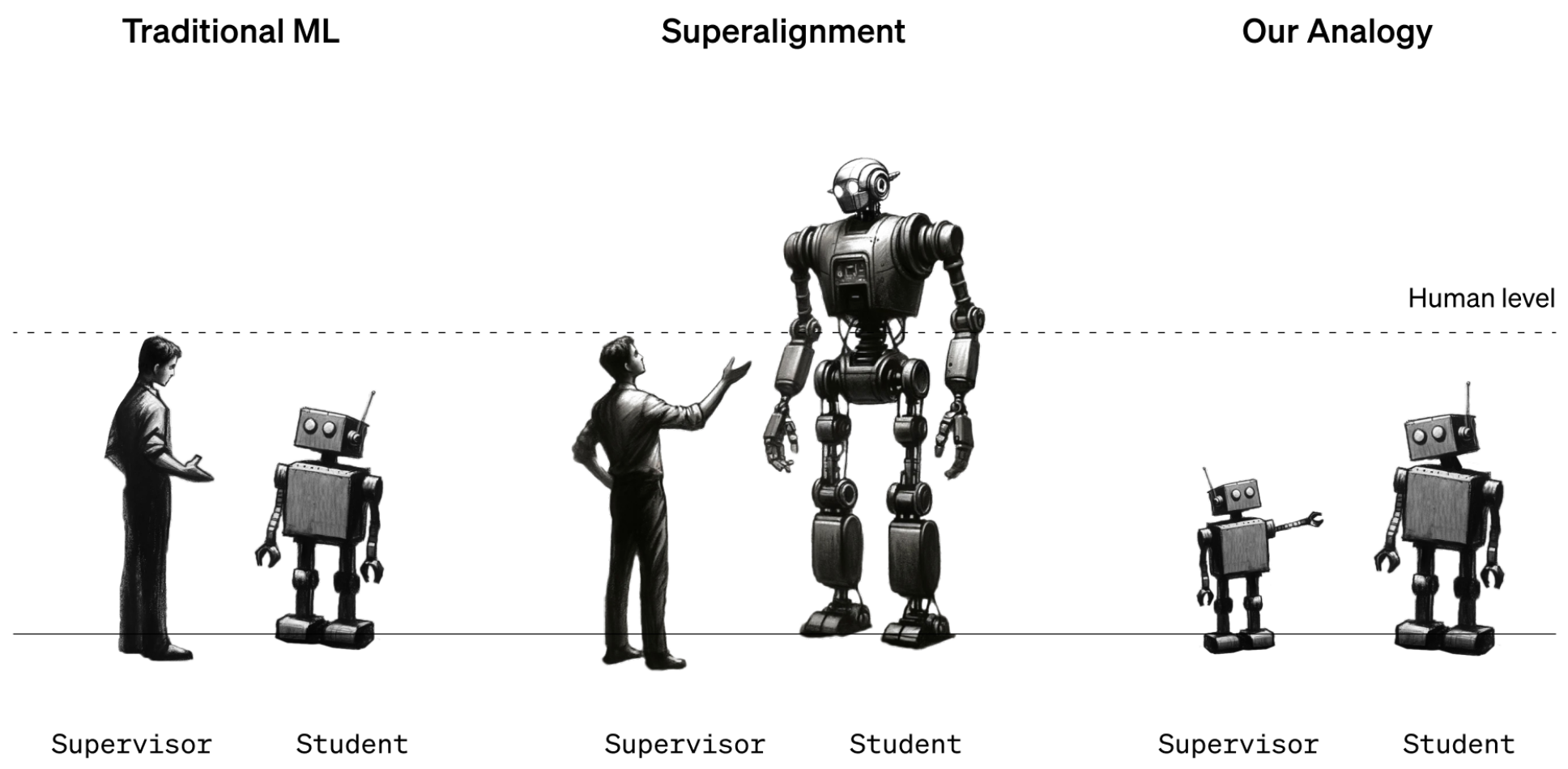
El documento de investigación explicaba que "al igual que el problema de los humanos que supervisan modelos sobrehumanos, nuestra configuración es un caso de lo que llamamos el problema de aprendizaje de débil a fuerte".
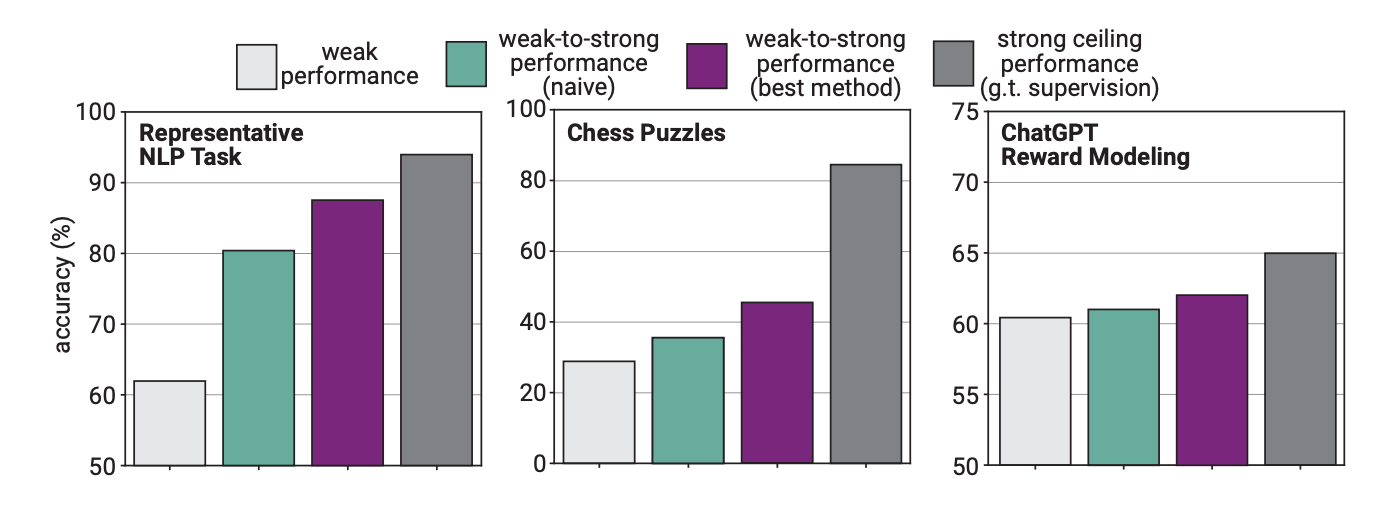
En el experimento, OpenAI utilizó GPT-2 para perfeccionar GPT-4 en tareas de PNL, rompecabezas de ajedrez y modelado de recompensas. A continuación, probaron el rendimiento de GPT-4 en la realización de estas tareas y lo compararon con un modelo GPT-4 que había sido entrenado con la "verdad básica" o las respuestas correctas a las tareas.
Los resultados fueron prometedores en el sentido de que cuando GPT-4 fue entrenado por el modelo más débil fue capaz de generalizar fuertemente y superar al modelo más débil. Esto demostró que una inteligencia más débil podía orientar a otra más fuerte que, a su vez, podía basarse en ese entrenamiento.
Piénsalo como si un alumno de tercer curso enseñara matemáticas a un niño muy listo y luego éste, basándose en la formación inicial, pasara a hacer matemáticas de duodécimo curso.
Brecha de rendimiento
Los investigadores descubrieron que, dado que GPT-4 estaba siendo entrenado por un modelo menos inteligente, ese proceso limitaba su rendimiento al equivalente de un modelo GPT-3.5 adecuadamente entrenado.
Esto se debe a que el modelo más inteligente aprende algunos de los errores o procesos de pensamiento deficientes de su supervisor más débil. Esto parece indicar que utilizar humanos para entrenar a una IA superinteligente impediría a la IA rendir al máximo de su potencial.
Los investigadores sugirieron utilizar modelos intermedios en un enfoque de bootstrapping. En el artículo se explicaba que "en lugar de alinear directamente modelos muy sobrehumanos, podríamos alinear primero un modelo sólo ligeramente sobrehumano, utilizarlo para alinear un modelo aún más inteligente, y así sucesivamente".
OpenAI está dedicando muchos recursos a este proyecto. El equipo de investigación afirma que ha dedicado "20% de la computación que hemos conseguido hasta la fecha durante los próximos cuatro años a resolver el problema de la alineación de superinteligencias."
También ofrece $10 millones en subvenciones a particulares u organizaciones que deseen colaborar en la investigación.
Más vale que lo resuelvan pronto. Una IA superinteligente podría escribir un millón de líneas de código complicado que ningún programador humano podría entender. ¿Cómo sabríamos si el código generado es seguro o no? Esperemos no descubrirlo por las malas.



