

A principios de mes, Google anunció con orgullo que su modelo Gemini más potente superaba a GPT-4 en las pruebas de referencia Massive Multitask Language Understanding MMLU. Con la nueva técnica de Microsoft, GPT-4 recupera el primer puesto, aunque por una fracción de punto porcentual.
Aparte del drama que rodea a su vídeo de marketing, Gemini de Google es un gran negocio para la empresa y sus resultados de referencia MMLU son impresionantes. Pero Microsoft, el mayor inversor de OpenAI, no ha tardado en criticar los esfuerzos de Google.
El titular es que Microsoft consiguió que GPT-4 batiera los resultados MMLU de Gemini Ultra. La realidad es que superó la puntuación de Gemini de 90,04% por solo 0,06%.
La historia de lo que ha hecho esto posible es más emocionante que el aumento de la competitividad que vemos en estas tablas de clasificación. Las nuevas técnicas de Microsoft podrían mejorar el rendimiento de los modelos de IA más antiguos.
¿Recuerdas que la inédita Gemini Ultra de Google acaba de superar a la GPT-4 para convertirse en la mejor IA?
Pues bien, Microsoft acaba de demostrar que, con las indicaciones adecuadas, GPT-4 supera realmente a Gemini en los benchmarks.
Hay mucho margen de mejora, incluso en los modelos más antiguos. https://t.co/YQ5zJI6Gad pic.twitter.com/X3HFmXa30X
- Ethan Mollick (@emollick) 12 de diciembre de 2023
Medprompt
Cuando se habla de "dirigir" un modelo, lo que se quiere decir es que, con una cuidadosa orientación, se puede guiar un modelo para obtener un resultado que se ajuste mejor a lo que se desea.
Microsoft desarrolló una combinación de técnicas de aviso que demostraron ser realmente buenas en este aspecto. Medprompt comenzó como un proyecto para conseguir que GPT-4 proporcionara mejores respuestas en pruebas de referencia de desafíos médicos como el conjunto de pruebas MultiMedQA.
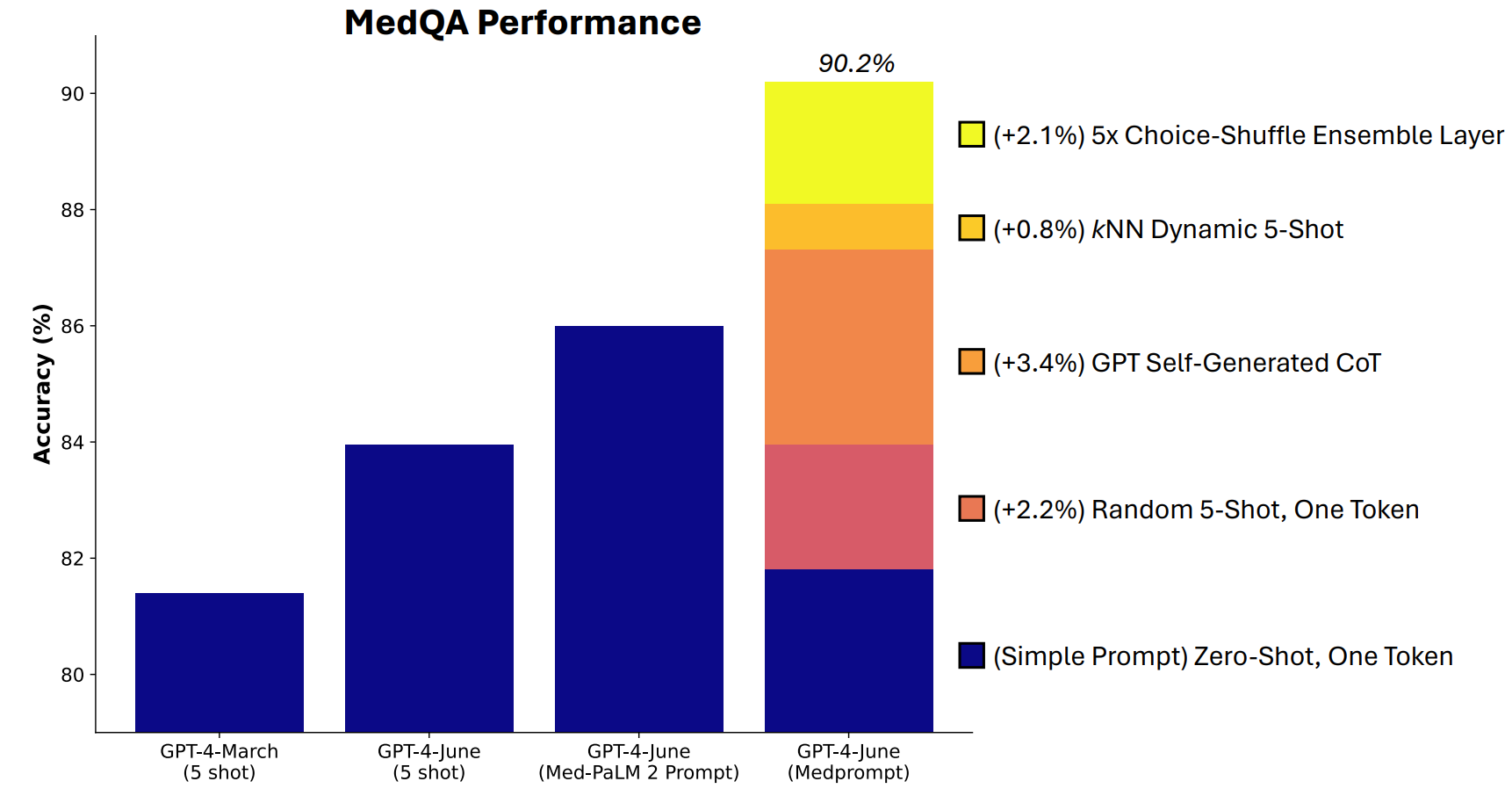
Los investigadores de Microsoft pensaron que si Medprompt funcionaba bien en pruebas médicas especializadas, también podría mejorar el rendimiento generalista de GPT-4. Y de ahí que Microsoft y OpenAI volvieran a presumir con GPT-4 frente a Gemini Ultra.
¿Cómo funciona Medprompt?
Medprompt es una combinación de ingeniosas técnicas de aviso en una sola. Se basa en tres técnicas principales.
Aprendizaje dinámico de pocos disparos (DFSL)
"Aprendizaje de pocos ejemplos" se refiere a dar a GPT-4 unos pocos ejemplos antes de pedirle que resuelva un problema similar. Cuando veas una referencia como "5-shot" significa que al modelo se le proporcionaron 5 ejemplos. "Zero-shot" significa que tuvo que responder sin ningún ejemplo.
En el documento de Medprompt se explica que "por razones de simplicidad y eficacia, los ejemplos de pocos disparos aplicados en los avisos para una tarea concreta suelen ser fijos; no se modifican en todos los ejemplos de prueba".
El resultado es que los ejemplos que se presentan a los modelos a menudo sólo son relevantes o representativos a grandes rasgos.
Si tu conjunto de entrenamiento es lo suficientemente grande, puedes hacer que el modelo examine todos los ejemplos y elija los que son semánticamente similares al problema que tiene que resolver. El resultado es que los pocos ejemplos de aprendizaje se ajustan más específicamente a un problema concreto.
Cadena de pensamiento autogenerada (CoT)
Las instrucciones de la Cadena de Pensamiento (CdT) son una forma estupenda de dirigir un LLM. Cuando le indicas "piensa detenidamente" o "resuélvelo paso a paso", los resultados mejoran mucho.
Se puede ser mucho más específico en la forma de guiar la cadena de pensamiento que debe seguir el modelo, pero eso implica ingeniería manual rápida.
Los investigadores descubrieron que "podían simplemente pedir a GPT-4 que generara cadenas de pensamiento para los ejemplos de entrenamiento". Su planteamiento consiste básicamente en decirle a GPT-4: "He aquí una pregunta, las opciones de respuesta y la respuesta correcta. ¿Qué cadena de pensamiento deberíamos incluir en una pregunta para llegar a esta respuesta?
Ensamblaje Choice Shuffle
La mayoría de las pruebas de referencia del MMLU son preguntas de opción múltiple. Cuando un modelo de IA responde a estas preguntas, puede caer presa del sesgo posicional. En otras palabras, podría favorecer la opción B aunque no siempre sea la respuesta correcta.
Choice Shuffle Ensembling baraja las posiciones de las opciones de respuesta y hace que GPT-4 responda de nuevo a la pregunta. Esto se repite varias veces y, a continuación, se selecciona la respuesta más coherente como respuesta final.
La combinación de estas tres técnicas puntuales es lo que dio a Microsoft la oportunidad de arrojar un poco de sombra sobre los resultados de Gemini. Será interesante ver qué resultados obtendría Gemini Ultra si utilizara un enfoque similar.
Medprompt es interesante porque demuestra que los modelos más antiguos pueden funcionar incluso mejor de lo que pensábamos si les damos instrucciones inteligentes. Sin embargo, la potencia de procesamiento adicional necesaria para estos pasos adicionales puede hacer que no sea un enfoque viable en la mayoría de los escenarios.



