

Ein Forscherteam der New York University hat Fortschritte bei der neuronalen Sprachdekodierung erzielt, die uns einer Zukunft näher bringen, in der Menschen, die die Fähigkeit zu sprechen verloren haben, ihre Stimme wiedererlangen können.
Die Studie, veröffentlicht in Natur Maschinelle Intelligenzstellt ein neuartiges Deep-Learning-System vor, das Gehirnsignale präzise in verständliche Sprache umwandelt.
Menschen mit Hirnverletzungen aufgrund von Schlaganfällen, degenerativen Erkrankungen oder körperlichen Traumata können diese Systeme zur Kommunikation nutzen, indem sie ihre Gedanken oder die beabsichtigte Sprache aus neuronalen Signalen entschlüsseln.
Das System des NYU-Teams basiert auf einem Deep-Learning-Modell, das die Elektrokortikographie-Signale (EKoG) des Gehirns auf Sprachmerkmale wie Tonhöhe, Lautstärke und andere spektrale Inhalte abbildet.
Die zweite Stufe beinhaltet einen neuronalen Sprachsynthesizer, der die extrahierten Sprachmerkmale in ein hörbares Spektrogramm umwandelt, das dann in eine Sprachwellenform umgewandelt werden kann.
Diese Wellenform kann schließlich in natürlich klingende, synthetische Sprache umgewandelt werden.
Neue Veröffentlichung in @NatMachIntellin dem wir eine robuste neuronale Sprachdekodierung bei 48 Patienten zeigen. https://t.co/rNPAMr4l68 pic.twitter.com/FG7QKCBVzp
- Adeen Flinker
(@adeenflinker) 9. April 2024


Wie die Studie funktioniert
Im Rahmen dieser Studie wird ein KI-Modell trainiert, das ein Sprachsynthesegerät betreiben kann, das es Menschen mit Sprachverlust ermöglicht, mit Hilfe von elektrischen Impulsen ihres Gehirns zu sprechen.
Im Folgenden wird die Funktionsweise näher erläutert:
1. Erfassen von Gehirndaten
Der erste Schritt besteht darin, die Rohdaten zu sammeln, die für das Training des Sprachentschlüsselungsmodells benötigt werden. Die Forscher arbeiteten mit 48 Teilnehmern, die sich wegen Epilepsie einer neurochirurgischen Behandlung unterzogen.
Während der Studie wurden diese Teilnehmer aufgefordert, Hunderte von Sätzen laut zu lesen, während ihre Gehirnaktivität mit Hilfe von EKG-Gittern aufgezeichnet wurde.
Diese Gitter werden direkt auf der Hirnoberfläche platziert und erfassen elektrische Signale aus den Hirnregionen, die an der Sprachproduktion beteiligt sind.
2. Abbildung von Gehirnsignalen auf Sprache
Anhand von Sprachdaten entwickelten die Forscher ein ausgeklügeltes KI-Modell, das die aufgezeichneten Gehirnsignale bestimmten Sprachmerkmalen wie Tonhöhe, Lautstärke und den einzelnen Frequenzen zuordnet, die verschiedene Sprachlaute ausmachen.
3. Synthese von Sprache aus Merkmalen
Der dritte Schritt besteht darin, die aus den Gehirnsignalen extrahierten Sprachmerkmale wieder in hörbare Sprache umzuwandeln.
Die Forscher verwendeten einen speziellen Sprachsynthesizer, der aus den extrahierten Merkmalen ein Spektrogramm erzeugt - eine visuelle Darstellung der Sprachlaute.
4. Auswertung der Ergebnisse
Die Forscher verglichen die von ihrem Modell generierte Sprache mit der von den Teilnehmern gesprochenen Originalsprache.
Sie verwendeten objektive Kriterien, um die Ähnlichkeit zwischen den beiden zu messen, und stellten fest, dass die generierte Sprache dem Inhalt und dem Rhythmus des Originals sehr ähnlich war.
5. Testen von neuen Wörtern
Um sicherzustellen, dass das Modell mit neuen Wörtern umgehen kann, die es noch nicht kennt, wurden in der Trainingsphase des Modells bestimmte Wörter absichtlich ausgelassen und anschließend die Leistung des Modells bei diesen ungesehenen Wörtern getestet.
Die Fähigkeit des Modells, selbst neue Wörter korrekt zu dekodieren, zeigt sein Potenzial zur Verallgemeinerung und Verarbeitung unterschiedlicher Sprachmuster.
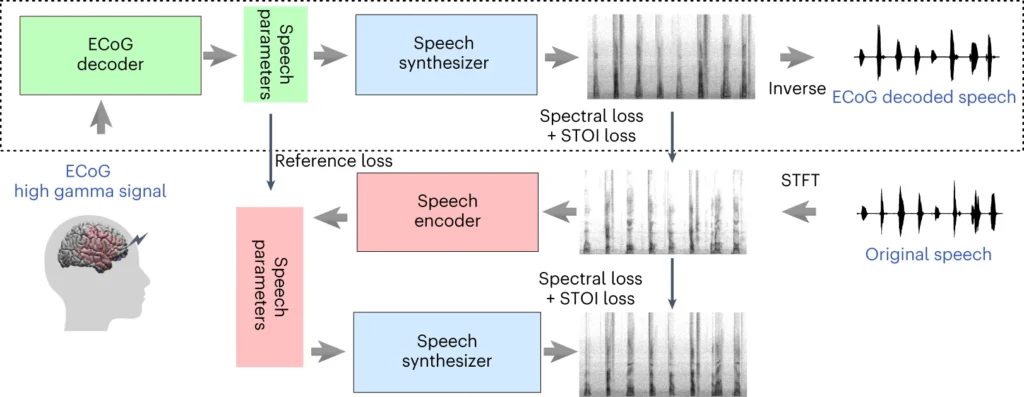
Der obere Teil des obigen Diagramms beschreibt einen Prozess zur Umwandlung von Gehirnsignalen in Sprache. Zunächst wandelt ein Decoder diese Signale im Laufe der Zeit in Sprachparameter um. Dann erzeugt ein Synthesizer aus diesen Parametern Klangbilder (Spektrogramme). Ein weiteres Werkzeug wandelt diese Bilder wieder in Schallwellen um.
Im unteren Abschnitt wird ein System erörtert, mit dem der Signaldecoder des Gehirns durch Nachahmung von Sprache trainiert wird. Es nimmt ein Klangbild, wandelt es in Sprachparameter um und verwendet diese dann, um ein neues Klangbild zu erzeugen. Dieser Teil des Systems lernt von tatsächlichen Sprachklängen, um sich zu verbessern.
Nach dem Training ist nur noch der oberste Prozess erforderlich, um die Gehirnsignale in Sprache umzuwandeln.
Ein entscheidender Vorteil des NYU-Systems besteht darin, dass es eine qualitativ hochwertige Sprachdekodierung ermöglicht, ohne dass extrem dichte Elektrodenarrays erforderlich sind, die für einen langfristigen Einsatz unpraktisch sind.
Im Wesentlichen handelt es sich um eine leichtere, tragbare Lösung.
Eine weitere Errungenschaft ist die erfolgreiche Dekodierung von Sprache sowohl aus der linken als auch aus der rechten Gehirnhälfte, was für Patienten mit Hirnschäden auf einer Seite wichtig ist.
Umwandlung von Gedanken in Sprache mithilfe von KI
Die Studie der NYU stützt sich auf frühere Forschungen zur neuronalen Sprachdekodierung und zu Gehirn-Computer-Schnittstellen (BCI).
Im Jahr 2023 ermöglichte ein Team der University of California, San Francisco, einem gelähmten Schlaganfallüberlebenden Sätze bilden mit einer Geschwindigkeit von 78 Wörtern pro Minute mit Hilfe eines BCI, das sowohl Vokalisationen als auch Gesichtsausdrücke aus Gehirnsignalen synthetisiert.
Andere neuere Studien haben sich mit dem Einsatz von KI zur Interpretation verschiedener Aspekte des menschlichen Denkens anhand von Gehirnaktivitäten befasst. Forscher haben gezeigt, dass sie in der Lage sind, aus MRT- und EEG-Daten des Gehirns Bilder, Texte und sogar Musik zu erzeugen.
Zum Beispiel, ein Studie der Universität von Helsinki nutzten EEG-Signale, um ein generatives adversariales Netzwerk (GAN) bei der Erstellung von Gesichtsbildern anzuleiten, die den Gedanken der Teilnehmer entsprachen.
Meta AI auch eine Technik entwickelt zur teilweisen Dekodierung dessen, was jemand hörte, anhand von nicht-invasiv erfassten Gehirnströmen.
Chancen und Herausforderungen
Die NYU-Methode verwendet mehr verfügbare und klinisch brauchbare Elektroden als frühere Methoden, was sie leichter zugänglich macht.
Das ist zwar aufregend, aber es gibt noch große Hindernisse zu überwinden, wenn wir eine breite Anwendung erleben wollen.
Zum einen ist die Erhebung hochwertiger Hirndaten ein komplexes und zeitaufwändiges Unterfangen. Individuelle Unterschiede in der Hirnaktivität erschweren die Verallgemeinerung, d. h. ein Modell, das für eine Gruppe von Teilnehmern trainiert wurde, funktioniert möglicherweise nicht gut für eine andere.
Dennoch stellt die NYU-Studie einen Schritt in diese Richtung dar, indem sie eine hochpräzise Sprachdekodierung mit leichteren Elektrodenarrays demonstriert.
In Zukunft will das NYU-Team seine Modelle für die Sprachdekodierung in Echtzeit weiter verfeinern, um dem Ziel näher zu kommen, natürliche, flüssige Gespräche für Menschen mit Sprachbehinderungen zu ermöglichen.
Sie beabsichtigen auch, das System an implantierbare drahtlose Geräte anzupassen, die im täglichen Leben verwendet werden können.



