

OpenAI hat auf dem Dev Day zwar keine neuen Modelle vorgestellt, aber neue API-Funktionen werden Entwickler begeistern, die ihre Modelle für die Entwicklung leistungsstarker Anwendungen nutzen wollen.
OpenAI hat ein paar harte Wochen hinter sich, in denen sich seine CTO Mira Murati und andere führende Forscher der immer länger werdenden Liste ehemaliger Mitarbeiter angeschlossen haben. Das Unternehmen steht unter zunehmendem Druck durch andere Flaggschiff-Modelle, einschließlich Open-Source-Modelle, die Entwicklern billigere und sehr leistungsfähige Optionen bieten.
Die neuen Funktionen, die OpenAI vorstellte, waren die Echtzeit-API (in der Betaversion), die Feinabstimmung der Vision und effizienzsteigernde Tools wie Prompt-Caching und Modelldestillation.
Echtzeit-API
Die Echtzeit-API ist die aufregendste neue Funktion, wenn auch noch im Beta-Stadium. Sie ermöglicht es Entwicklern, Spracherlebnisse mit niedriger Latenz in ihren Anwendungen zu erstellen, ohne separate Modelle für die Spracherkennung und die Text-zu-Sprache-Umwandlung zu verwenden.
Mit dieser API können Entwickler nun Apps erstellen, die Echtzeitgespräche mit KI ermöglichen, wie z. B. Sprachassistenten oder Sprachlerntools, und zwar über einen einzigen API-Aufruf. Es ist nicht ganz das nahtlose Erlebnis, das der Advanced Voice Mode von GPT-4o bietet, aber es ist nah dran.
Mit etwa $0,06 pro Minute Audioeingang und $0,24 pro Minute Audioausgang ist es allerdings nicht billig.
Das neue Realtime API von OpenAI ist unglaublich...
Sehen Sie zu, wie er 400 Erdbeeren bestellt, indem er tatsächlich mit twillio im Laden anruft. Alles mit Stimme. 🍓🎤 pic.twitter.com/J2BBoL9yFv
- Ty (@FieroTy) 1. Oktober 2024
Feinabstimmung der Vision
Die Feinabstimmung der Bildverarbeitung innerhalb der API ermöglicht es Entwicklern, die Fähigkeit ihrer Modelle zu verbessern, Bilder zu verstehen und mit ihnen zu interagieren. Durch die Feinabstimmung von GPT-4o mit Bildern können Entwickler Anwendungen erstellen, die sich durch Aufgaben wie visuelle Suche oder Objekterkennung auszeichnen.
Diese Funktion wird bereits von Unternehmen wie Grab genutzt, das die Genauigkeit seines Kartendienstes durch eine Feinabstimmung des Modells zur Erkennung von Verkehrsschildern aus Bildern auf Straßenebene verbessert hat.
OpenAI gab auch ein Beispiel dafür, wie GPT-4o zusätzliche Inhalte für eine Website generieren kann, nachdem es stilistisch auf die bestehenden Inhalte der Website abgestimmt wurde.
Prompt-Caching
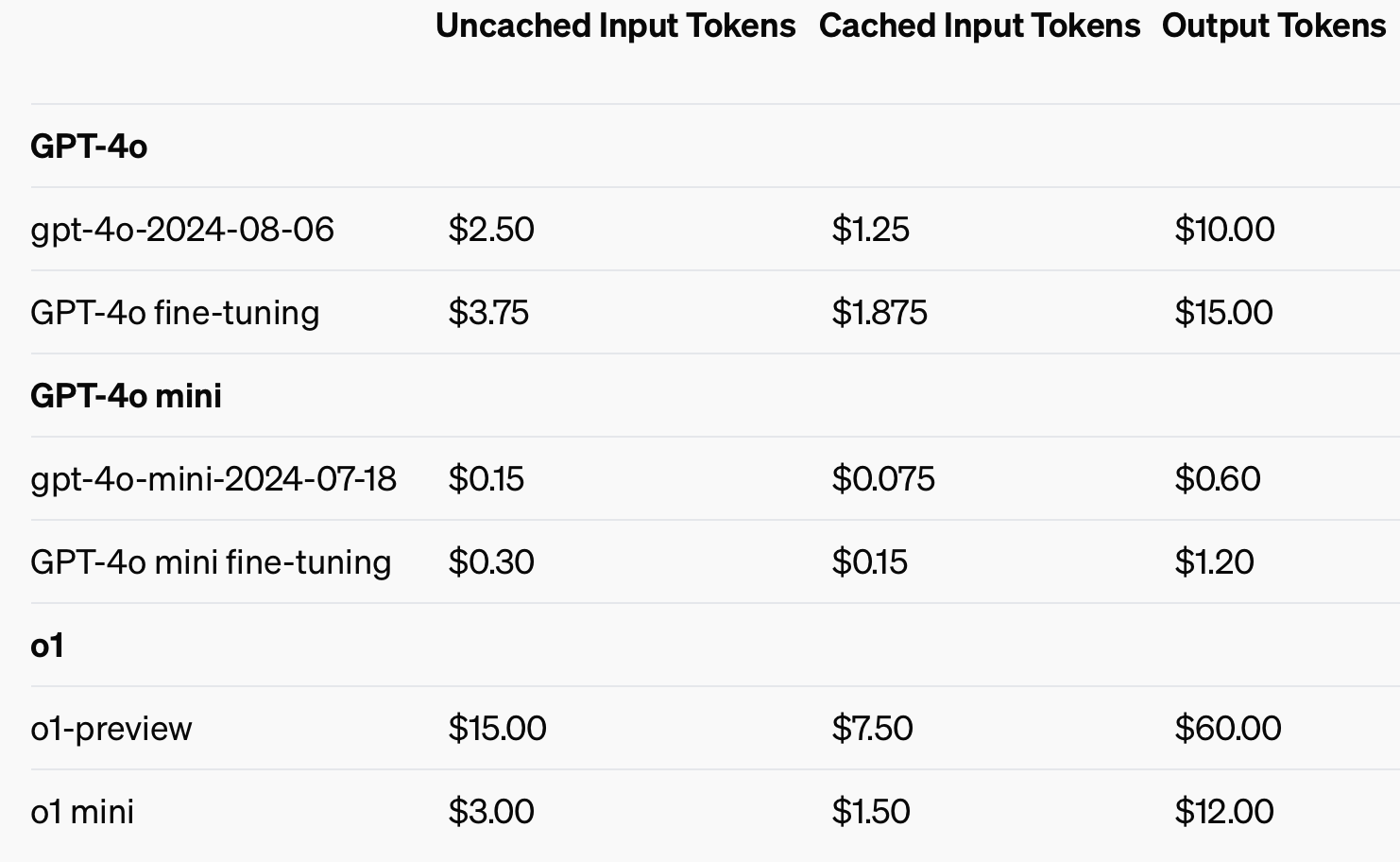
Um die Kosteneffizienz zu verbessern, hat OpenAI das Prompt-Caching eingeführt, ein Tool, das die Kosten und die Latenz von häufig verwendeten API-Aufrufen reduziert. Durch die Wiederverwendung kürzlich verarbeiteter Eingaben können Entwickler die Kosten um 50% senken und die Antwortzeiten verkürzen. Diese Funktion ist besonders nützlich für Anwendungen, die lange Konversationen oder wiederholten Kontext erfordern, wie Chatbots und Kundendienst-Tools.
Die Verwendung von zwischengespeicherten Eingaben könnte bis zu 50% an Kosten für Eingabe-Token einsparen.
Modell Destillation
Die Modelldestillation ermöglicht Entwicklern die Feinabstimmung kleinerer, kostengünstigerer Modelle unter Verwendung der Ergebnisse größerer, leistungsfähigerer Modelle. Dies ist ein entscheidender Fortschritt, denn bisher waren für die Destillation mehrere voneinander getrennte Schritte und Tools erforderlich, was den Prozess zeitaufwändig und fehleranfällig machte.
Vor der integrierten Funktion Model Distillation von OpenAI mussten die Entwickler verschiedene Teile des Prozesses manuell orchestrieren, wie z. B. die Generierung von Daten aus größeren Modellen, die Vorbereitung von Feinabstimmungsdatensätzen und die Leistungsmessung mit verschiedenen Tools.
Entwickler können nun automatisch Ausgabepaare von größeren Modellen wie GPT-4o speichern und diese Paare zur Feinabstimmung kleinerer Modelle wie GPT-4o-mini verwenden. Der gesamte Prozess der Erstellung von Datensätzen, der Feinabstimmung und der Bewertung kann auf strukturiertere, automatisierte und effizientere Weise durchgeführt werden.
Der gestraffte Entwicklerprozess, die geringere Latenzzeit und die reduzierten Kosten machen das GPT-4o-Modell von OpenAI zu einer attraktiven Perspektive für Entwickler, die schnell leistungsstarke Anwendungen bereitstellen möchten. Es wird interessant sein zu sehen, welche Anwendungen die multimodalen Funktionen möglich machen.



