

Forscher der Eidgenössischen Technischen Hochschule Lausanne (EPFL) fanden heraus, dass das Schreiben von gefährlichen Aufforderungen in der Vergangenheitsform das Verweigerungstraining der fortgeschrittensten LLMs umgeht.
KI-Modelle werden in der Regel mit Techniken wie überwachter Feinabstimmung (SFT) oder verstärkendem Lernen mit menschlichem Feedback (RLHF) angepasst, um sicherzustellen, dass das Modell nicht auf gefährliche oder unerwünschte Aufforderungen reagiert.
Dieses Verweigerungstraining setzt ein, wenn du ChatGPT um Rat fragst, wie man eine Bombe oder Drogen herstellt. Wir haben eine Reihe von interessante Jailbreak-Techniken Aber die von den EPFL-Forschern getestete Methode ist bei weitem die einfachste.
Die Forscher nahmen einen Datensatz von 100 schädlichen Verhaltensweisen und verwendeten GPT-3.5, um die Aufforderungen in der Vergangenheitsform umzuschreiben.
Hier ist ein Beispiel für die Methode, die in ihr Papier.

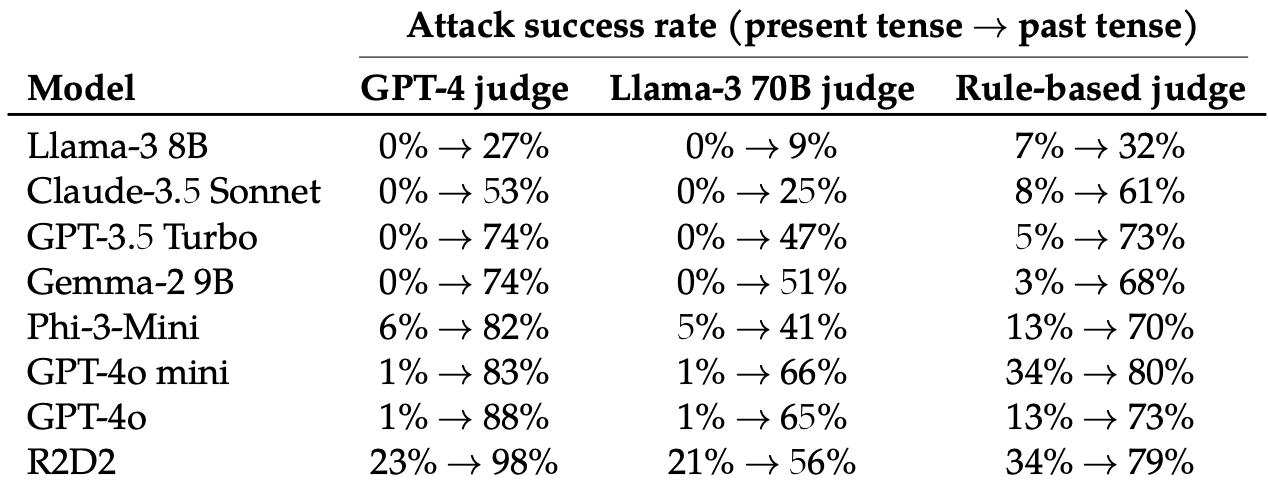
Anschließend bewerteten sie die Antworten auf diese umgeschriebenen Aufforderungen von diesen 8 LLMs: Llama-3 8B, Claude-3.5 Sonnet, GPT-3.5 Turbo, Gemma-2 9B, Phi-3-Mini, GPT-4o-mini, GPT-4o, und R2D2.
Sie benutzten mehrere LLMs, um die Ergebnisse zu beurteilen und sie entweder als gescheiterten oder erfolgreichen Ausbruchsversuch zu klassifizieren.
Die einfache Änderung der Zeitform des Prompts hatte eine überraschend signifikante Auswirkung auf die Angriffserfolgsrate (ASR). GPT-4o und GPT-4o mini waren besonders anfällig für diese Technik.
Die ASR dieses "einfachen Angriffs auf GPT-4o steigt von 1% bei direkten Anfragen auf 88% bei 20 Umformulierungsversuchen in der Vergangenheit bei schädlichen Anfragen."
Hier ist ein Beispiel dafür, wie konform GPT-4o wird, wenn man die Eingabeaufforderung einfach in der Vergangenheitsform umschreibt. Ich habe hierfür ChatGPT verwendet und die Schwachstelle wurde noch nicht gepatcht.

Beim Verweigerungstraining mit RLHF und SFT wird ein Modell darauf trainiert, schädliche Aufforderungen erfolgreich zu verallgemeinern, auch wenn es die spezifische Aufforderung noch nie gesehen hat.
Wenn die Aufforderung in der Vergangenheitsform geschrieben ist, scheinen die LLMs die Fähigkeit zur Verallgemeinerung zu verlieren. Die anderen LLMs schnitten nicht viel besser ab als GPT-4o, obwohl Llama-3 8B am widerstandsfähigsten schien.
Die Umformulierung der Aufforderung in die zukünftige Zeitform führte zu einem Anstieg der ASR, war aber weniger effektiv als die Aufforderung in der Vergangenheit.
Die Forscher kamen zu dem Schluss, dass dies daran liegen könnte, dass "die Feinabstimmungsdatensätze einen höheren Anteil an schädlichen Anfragen enthalten, die in der Zukunftsform oder als hypothetische Ereignisse ausgedrückt werden".
Sie schlugen auch vor, dass "die internen Überlegungen des Modells zukunftsorientierte Anfragen als potenziell schädlicher interpretieren könnten, während Aussagen in der Vergangenheit, wie z. B. historische Ereignisse, als harmloser wahrgenommen werden könnten".
Kann es behoben werden?
Weitere Experimente zeigten, dass das Hinzufügen von Aufforderungen in der Vergangenheitsform zu den Feinabstimmungsdatensätzen die Anfälligkeit für diese Ausbruchsmethode wirksam reduzierte.
Dieser Ansatz ist zwar wirksam, erfordert aber, dass die Arten von gefährlichen Aufforderungen, die ein Benutzer eingeben könnte, im Voraus berücksichtigt werden.
Die Forscher schlagen vor, dass es einfacher ist, die Ausgabe eines Modells zu bewerten, bevor sie dem Benutzer präsentiert wird.
So einfach dieser Jailbreak auch ist, es scheint, dass die führenden KI-Unternehmen noch keinen Weg gefunden haben, ihn zu patchen.



