

Das Genie von Google DeepMind ist ein generatives Modell, das einfache Bilder oder Texteingaben in dynamische, interaktive Welten übersetzt.
Genie wurde mit einem umfangreichen Datensatz von über 200.000 Stunden Videomaterial aus Spielen trainiert, darunter Gameplay aus 2D-Plattformern und realen Roboterinteraktionen.
Dieser umfangreiche Datensatz ermöglichte es Genie, die Physik, Dynamik und Ästhetik zahlreicher Umgebungen und Objekte zu verstehen und zu erzeugen.
Das endgültige Modell, dokumentiert in einer Forschungsarbeitenthält 11 Milliarden Parameter, um interaktive virtuelle Welten entweder aus Bildern in verschiedenen Formaten oder aus Textvorgaben zu erzeugen.
So können Sie Genie mit einem Bild Ihres Wohnzimmers oder Gartens füttern und es in einen spielbaren 2D-Plattform-Level verwandeln.
Oder kritzeln Sie eine 2D-Umgebung auf ein Blatt Papier und wandeln Sie sie in eine spielbare Spielumgebung um.
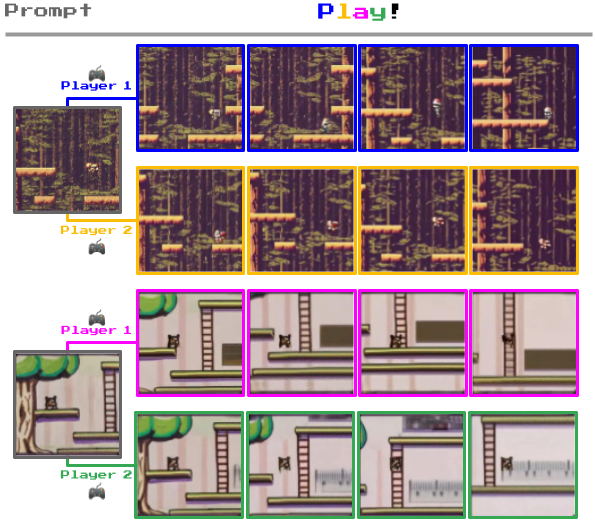
Was Genie von anderen Weltmodellen unterscheidet, ist die Möglichkeit, mit den generierten Umgebungen Frame für Frame zu interagieren.
Unten sehen Sie zum Beispiel, wie Genie Fotos von realen Umgebungen aufnimmt und sie in 2D-Spielebenen verwandelt.

Wie Genie funktioniert
Genie ist ein "Basisweltmodell" mit drei Schlüsselkomponenten: einem raum-zeitlichen Video-Tokenizer, einem autoregressiven Dynamikmodell und einem einfachen, skalierbaren latenten Aktionsmodell (LAM).
Und so funktioniert es:
- Räumlich-zeitliche Transformatoren: Das Herzstück von Genie sind spatiotemporale (ST) Transformatoren, die Sequenzen von Videobildern verarbeiten. Im Gegensatz zu herkömmlichen Transformatoren, die Text oder statische Bilder verarbeiten, sind ST-Transformatoren darauf ausgelegt, den zeitlichen Verlauf visueller Daten zu verstehen, was sie ideal für die Erzeugung von Videos und dynamischen Umgebungen macht.
- Latentes Handlungsmodell (LAM): Genie versteht und prognostiziert Aktionen innerhalb der von ihm generierten Welten durch den LAM. Daraus werden die potenziellen Aktionen abgeleitet, die zwischen den Einzelbildern eines Videos auftreten könnten, wobei eine Reihe von "latenten Aktionen" direkt aus den visuellen Daten gelernt wird. Dadurch ist Genie in der Lage, den Ablauf von Ereignissen in interaktiven Umgebungen zu steuern, auch wenn in den Trainingsdaten keine expliziten Aktionsbezeichnungen vorhanden sind.
- Video-Tokenizer und Dynamikmodell: Zur Verwaltung der Videodaten setzt Genie einen Video-Tokenizer ein, der Videorohbilder in ein handlicheres Format diskreter Token komprimiert. Nach der Tokenisierung prognostiziert das Dynamikmodell den nächsten Satz von Frame-Tokens und generiert die nachfolgenden Frames in der interaktiven Umgebung.
Das DeepMind-Team erklärte zu Genie: "Genie könnte es einer großen Anzahl von Menschen ermöglichen, ihre eigenen spielähnlichen Erfahrungen zu machen. Dies könnte sich positiv auf diejenigen auswirken, die ihre Kreativität auf neue Weise zum Ausdruck bringen wollen, z. B. Kinder, die ihre eigenen Fantasiewelten entwerfen und betreten können.
In einem Nebenexperiment zeigte Genie bei der Vorführung von Videos echter Roboterarme, die mit realen Objekten interagieren, eine unheimliche Fähigkeit, die Aktionen zu entschlüsseln, die diese Arme ausführen könnten. Dies zeigt, dass es in der Robotikforschung eingesetzt werden kann.
Tim Rocktäschel vom Genie-Team beschrieb das unbegrenzte Potenzial von Genie: "Es ist schwer vorherzusagen, welche Anwendungsfälle möglich sein werden. Wir hoffen, dass Projekte wie Genie den Menschen neue Werkzeuge an die Hand geben, mit denen sie ihre Kreativität zum Ausdruck bringen können".
DeepMind war sich der Risiken bewusst, die mit der Veröffentlichung dieses Basismodells verbunden sind, und erklärte in dem Papier: "Wir haben uns entschieden, die Kontrollpunkte des trainierten Modells, den Trainingsdatensatz des Modells oder Beispiele aus diesen Daten nicht zu veröffentlichen, um dieses Papier oder die Website zu begleiten."
"Wir würden uns freuen, wenn wir die Möglichkeit hätten, uns weiter mit der Forschungsgemeinschaft (und der Videospielgemeinschaft) zu engagieren und sicherzustellen, dass alle zukünftigen Veröffentlichungen dieser Art respektvoll, sicher und verantwortungsvoll sind.
Spiele nutzen, um reale Anwendungen zu simulieren
DeepMind hat Videospiele für mehrere Projekte zum maschinellen Lernen verwendet.
Zum Beispiel im Jahr 2021, DeepMind baute XLandeine virtuelle Spielwiese zur Erprobung von Ansätzen des verstärkenden Lernens (Reinforcement Learning, RL) für generalistische KI-Agenten. Hier meisterten die KI-Modelle Kooperation und Problemlösung, indem sie Aufgaben wie das Verschieben von Hindernissen in offenen Spielumgebungen ausführten.
Dann, erst letzten Monat, SIMA (Scalable, Instructable, Multiworld Agent) wurde entwickelt, um menschliche Sprachanweisungen in verschiedenen Spielen und Szenarien zu verstehen und auszuführen.
SIMA wurde anhand von neun Videospielen trainiert, die unterschiedliche Fähigkeiten erfordern, von der grundlegenden Navigation bis zum Steuern von Fahrzeugen.
Spielumgebungen bieten einen kontrollierbaren, skalierbaren Sandkasten für das Training und Testen von KI-Modellen.
DeepMinds Gaming-Expertise reicht bis in die Jahre 2014-2015 zurück, als das Unternehmen einen Algorithmus entwickelte, der Menschen in Spielen wie Pong und Space Invaders besiegte, ganz zu schweigen von AlphaGo, das den Profispieler Fan Hui auf einem 19×19 großen Brett besiegte.



