

Trotz der rasanten Fortschritte bei den LLMs wissen wir immer noch nicht genau, wie diese Modelle mit längeren Inputs umgehen.
Mosh Levy, Alon Jacoby und Yoav Goldberg von der Bar-Ilan-Universität und dem Allen Institute for AI untersuchten, wie die Leistung großer Sprachmodelle (LLMs) mit der Länge des Eingabetextes, den sie verarbeiten sollen, variiert.
Zu diesem Zweck entwickelten sie einen Rahmen für das logische Denken, der es ihnen ermöglichte, den Einfluss der Eingabelänge auf das logische Denken in einer kontrollierten Umgebung zu untersuchen.
Der Fragerahmen schlug verschiedene Versionen ein und derselben Frage vor, die jeweils die für die Beantwortung der Frage erforderlichen Informationen enthielten und mit zusätzlichem, irrelevantem Text unterschiedlicher Länge und Art angereichert waren.
Dies ermöglicht die Isolierung der Eingabelänge als Variable, wodurch sichergestellt wird, dass Änderungen in der Modellleistung direkt auf die Länge des Eingangs zurückgeführt werden können.
Wichtigste Ergebnisse
Levy, Jacoby und Goldberg fanden heraus, dass LLMs bei Eingabelängen, die weit unter dem liegen, was die Entwickler behaupten, dass sie damit umgehen können, einen bemerkenswerten Rückgang der Denkleistung aufweisen. Sie dokumentierten ihre Ergebnisse in dieser Studie.
Der Rückgang wurde durchgängig bei allen Versionen des Datensatzes beobachtet, was eher auf ein systemisches Problem bei der Verarbeitung längerer Eingaben als auf ein Problem hinweist, das mit spezifischen Datenproben oder Modellarchitekturen zusammenhängt.
Die Forscher beschreiben: "Unsere Ergebnisse zeigen eine bemerkenswerte Verschlechterung der Argumentationsleistung von LLMs bei viel kürzeren Eingabelängen als ihrem technischen Maximum. Wir zeigen, dass der Verschlechterungstrend in jeder Version unseres Datensatzes auftritt, wenn auch in unterschiedlicher Intensität".

Darüber hinaus zeigt die Studie, dass traditionelle Metriken wie Perplexität, die üblicherweise zur Bewertung von LLMs verwendet werden, nicht mit der Leistung der Modelle bei logischen Aufgaben mit langen Eingaben korrelieren.
Weitere Untersuchungen ergaben, dass die Leistungsverschlechterung nicht nur vom Vorhandensein irrelevanter Informationen (Polster) abhing, sondern auch dann zu beobachten war, wenn diese Polster aus doppelten relevanten Informationen bestanden.
Wenn wir die beiden Kernabschnitte zusammenhalten und Text um sie herum hinzufügen, sinkt die Genauigkeit bereits. Wenn wir Absätze zwischen den Abschnitten einfügen, sinken die Ergebnisse noch stärker. Der Rückgang tritt sowohl auf, wenn die hinzugefügten Texte den Aufgabentexten ähnlich sind, als auch, wenn sie völlig anders sind. 3/7 pic.twitter.com/c91l9uzyme
- Mosh Levy (@mosh_levy) 26. Februar 2024
Dies deutet darauf hin, dass die Herausforderung für LLMs im Herausfiltern von Rauschen und der inhärenten Verarbeitung längerer Textsequenzen liegt.
Ignorieren von Anweisungen
Ein kritischer Bereich, der in der Studie hervorgehoben wurde, ist die Tendenz der LLMs, in die Eingabe eingebettete Anweisungen zu ignorieren, wenn die Eingabelänge zunimmt.
Die Modelle geben manchmal auch Antworten, die auf Unsicherheit oder unzureichende Informationen hinweisen, wie z. B. "Der Text enthält nicht genügend Informationen", obwohl alle erforderlichen Informationen vorhanden sind.
Insgesamt scheint es den LLMs mit zunehmender Eingabelänge immer schwerer zu fallen, Prioritäten zu setzen und sich auf die wichtigsten Informationen, einschließlich direkter Anweisungen, zu konzentrieren.
Voreingenommenheit bei Antworten
Ein weiteres bemerkenswertes Problem waren die zunehmenden Verzerrungen in den Antworten der Modelle, wenn die Eingaben länger wurden.
Insbesondere neigten die LLMs dazu, mit zunehmender Eingabelänge "Falsch" zu antworten. Diese Verzerrung deutet auf eine Schieflage in der Wahrscheinlichkeitsschätzung oder in den Entscheidungsprozessen innerhalb des Modells hin, möglicherweise als Abwehrmechanismus als Reaktion auf die erhöhte Unsicherheit aufgrund längerer Eingabelängen.
Die Neigung, "falsche" Antworten zu bevorzugen, könnte auch ein zugrunde liegendes Ungleichgewicht in den Trainingsdaten oder ein Artefakt des Trainingsprozesses der Modelle widerspiegeln, bei dem negative Antworten überrepräsentiert sind oder mit Kontexten von Unsicherheit und Mehrdeutigkeit in Verbindung gebracht werden.
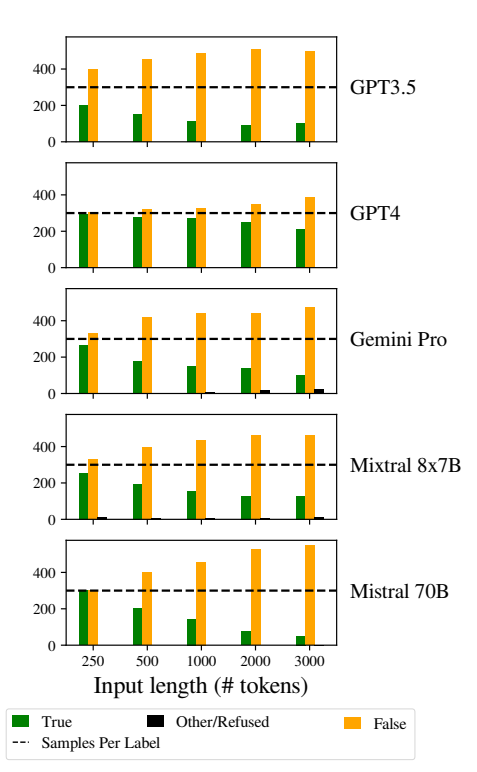
Diese Verzerrung beeinträchtigt die Genauigkeit der Modellergebnisse und gibt Anlass zu Bedenken hinsichtlich der Zuverlässigkeit und Fairness von LLM bei Anwendungen, die ein differenziertes Verständnis und Unparteilichkeit erfordern.
Die Umsetzung robuster Strategien zur Erkennung und Abschwächung von Verzerrungen während der Modellschulungs- und Feinabstimmungsphasen ist unerlässlich, um ungerechtfertigte Verzerrungen in den Modellreaktionen zu reduzieren.
EDie Sicherstellung, dass die Trainingsdatensätze vielfältig, ausgewogen und repräsentativ für ein breites Spektrum von Szenarien sind, kann ebenfalls dazu beitragen, Verzerrungen zu minimieren und die Modellgeneralisierung zu verbessern.
Dies trägt dazu bei andere aktuelle Studien die in ähnlicher Weise grundlegende Probleme in der Funktionsweise von LLMs aufzeigen und so zu einer Situation führen, in der diese "technischen Schulden" die Funktionalität und Integrität des Modells im Laufe der Zeit gefährden könnten.



