

Google hat zwei Modelle aus seiner Familie leichter, offener Modelle namens Gemma veröffentlicht.
Während es sich bei den Gemini-Modellen von Google um proprietäre, also geschlossene Modelle handelt, wurden die Gemma-Modelle als "offene Modelle" veröffentlicht und Entwicklern frei zugänglich gemacht.
Google hat Gemma-Modelle in zwei Größen, 2B und 7B Parameter, mit vortrainierten und anweisungsabgestimmten Varianten für jedes Modell veröffentlicht. Google veröffentlicht die Modellgewichte sowie eine Reihe von Tools für Entwickler, um die Modelle an ihre Bedürfnisse anzupassen.
Google sagt, dass die Gemma-Modelle mit der gleichen Technologie entwickelt wurden, mit der auch das Flaggschiff-Modell Gemini arbeitet. Mehrere Unternehmen haben 7B-Modelle in dem Bemühen veröffentlicht, ein LLM zu liefern, das brauchbare Funktionen beibehält, aber möglicherweise lokal statt in der Cloud läuft.
Llama-2-7B und Mistral-7B sind bemerkenswerte Konkurrenten in diesem Bereich, aber Google sagt, dass "Gemma deutlich größere Modelle bei wichtigen Benchmarks übertrifft", und bietet diesen Benchmark-Vergleich als Beweis an.
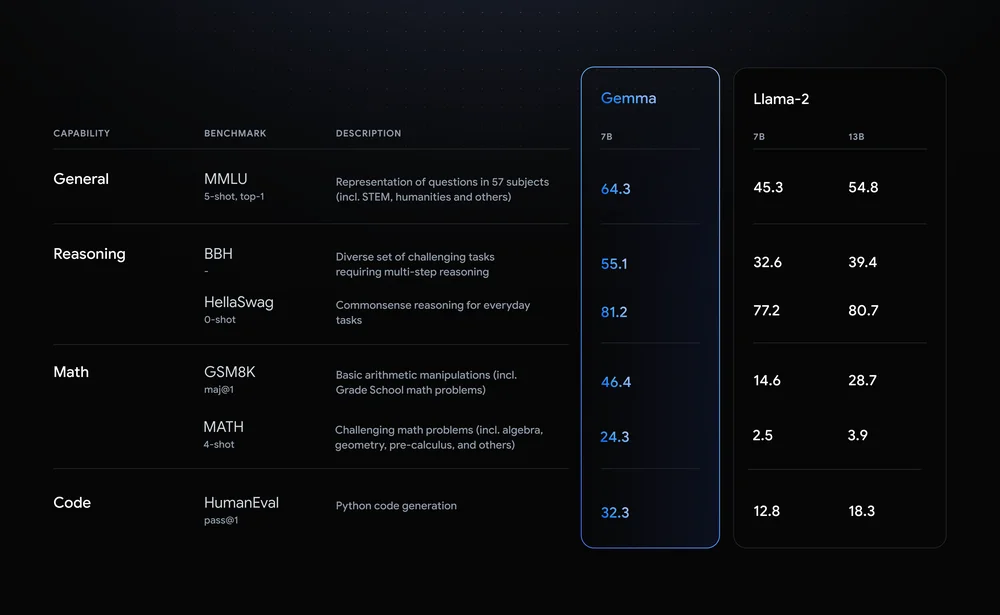
Die Benchmark-Ergebnisse zeigen, dass Gemma sogar die größere 12B-Version von Llama 2 in allen vier Bereichen übertrifft.
Das wirklich Spannende an Gemma ist die Aussicht, es lokal auszuführen. Google ist eine Partnerschaft mit NVIDIA eingegangen, um Gemma für NVIDIA-GPUs zu optimieren. Wenn Sie einen PC mit einem RTX-Grafikprozessor von NVIDIA haben, können Sie Gemma auf Ihrem Gerät ausführen.
NVIDIA gibt an, eine Basis von über 100 Millionen NVIDIA RTX GPUs installiert zu haben. Das macht Gemma zu einer attraktiven Option für Entwickler, die sich entscheiden müssen, welches leichtgewichtige Modell sie als Basis für ihre Produkte verwenden wollen.
NVIDIA wird auch die Unterstützung für Gemma auf seinen Chat mit RTX Plattform, die es einfach macht, LLMs auf RTX-PCs auszuführen.
Technisch gesehen handelt es sich zwar nicht um Open Source, aber nur die Nutzungsbeschränkungen in der Lizenzvereinbarung verhindern, dass Gemma-Modelle diese Bezeichnung tragen. Kritiker der offenen Modelle weisen auf die Risiken hin, die damit verbunden sind, sie aufeinander abzustimmen, aber Google sagt, dass es ein umfassendes Red-Teaming durchgeführt hat, um sicherzustellen, dass Gemma sicher war.
Google sagt, dass es "umfangreiche Feinabstimmung und Verstärkungslernen aus menschlichem Feedback (RLHF) verwendet hat, um unsere auf Anweisungen abgestimmten Modelle auf verantwortungsbewusstes Verhalten auszurichten". Außerdem wurde ein Toolkit für verantwortungsbewusste generative KI veröffentlicht, um Entwicklern zu helfen, Gemma nach der Feinabstimmung weiter zu optimieren.
Anpassbare, leichtgewichtige Modelle wie Gemma bieten Entwicklern möglicherweise mehr Nutzen als größere Modelle wie GPT-4 oder Gemini Pro. Die Möglichkeit, LLMs lokal auszuführen, ohne dass die Kosten für Cloud-Computing oder API-Aufrufe anfallen, wird von Tag zu Tag besser zugänglich.
Da Gemma für Entwickler offen zugänglich ist, wird es interessant sein zu sehen, welche Palette von KI-gestützten Anwendungen bald auf unseren PCs laufen könnte.



