

Die New York Times (NYT) hat heute eine Klage gegen OpenAI und Microsoft eingereicht. Sie behauptet, die Unternehmen hätten ihre Urheberrechte verletzt, indem sie ihre Inhalte zum Training ihrer KI-Modelle verwendet hätten.
Weder Microsoft noch OpenAI wollen bestätigen, welche Daten genau für das Training ihrer Modelle verwendet wurden, aber es wird immer deutlicher, dass es sich um so ziemlich alles handelt, was im Internet verfügbar ist.
Die Times wandte sich im April an Microsoft und OpenAI, um ihre Bedenken über die Verwendung ihrer Inhalte zu diskutieren. In den Gerichtsakten heißt es, dass trotz dieser Bemühungen keine Einigung erzielt werden konnte. Im August sagten sie, sie seien eine Klage in Erwägung ziehen und jetzt haben sie es endlich getan.
Die Einreichung stellt fest, dass die KI-Modelle, die OpenAI und Microsoft auf den Inhalten der NYT trainiert haben, "der Times Abonnement-, Lizenz-, Werbe- und Partnereinnahmen vorenthalten".
Wenn Nutzer ChatGPT oder Copilot eine Frage zu einem Thema stellen, über das die Times berichtet hat, erzeugen diese Modelle der Klage zufolge "Ausgaben, die den Inhalt der Times wortwörtlich wiedergeben, ihn eng zusammenfassen und seinen Ausdrucksstil imitieren", und zwar oft ohne Links zum Originalartikel.
Wenn Nutzer auf ChatGPT Antworten erhalten, ohne auf die Website der Times zu klicken, entgehen dem Unternehmen Werbe- und Abonnementeinnahmen.
Dem Medienunternehmen gehören auch Bewertungswebseiten wie Wirecutter. Die Times behauptet, dass der Inhalt von Rezensionen oft von KI-Chatbots reproduziert wird, wobei die Empfehlungslinks herausgenommen werden. Dadurch entgehen der Times Einnahmen aus Affiliate-Empfehlungen.
In der Klage wird auch behauptet, dass die Neigung von KI-Modellen wie ChatGPT zu Halluzinationen dem Ruf der Times schadet. Manchmal werden aufgrund von Halluzinationen des Modells sachlich falsche Antworten generiert, die dennoch der Times zugeschrieben werden.
Aber hat sie Kopien gemacht?
Die großen KI-Unternehmen scheinen derzeit alle mit Urheberrechtsklagen beschäftigt zu sein. OpenAI, Meta, Microsoft, Stabile Diffusionund andere sind derzeit mit Klagen von Autoren, Künstlern und anderen Kreativen befasst.
Das allgemeine Argument der Beklagten ist, dass KI-Modelle keine Kopien der Daten erstellen, auf denen sie trainiert werden, und dass die Verwendung urheberrechtlich geschützter Daten für das Training unter den Grundsatz der fairen Nutzung fällt.
Die Beispiele in der NYT-Klage machen es schwierig, diesen Punkt zu bestreiten. Hier ist ein Beispiel für eine ChatGPT-Interaktion, die den Inhalt der Times wortwörtlich kopiert.
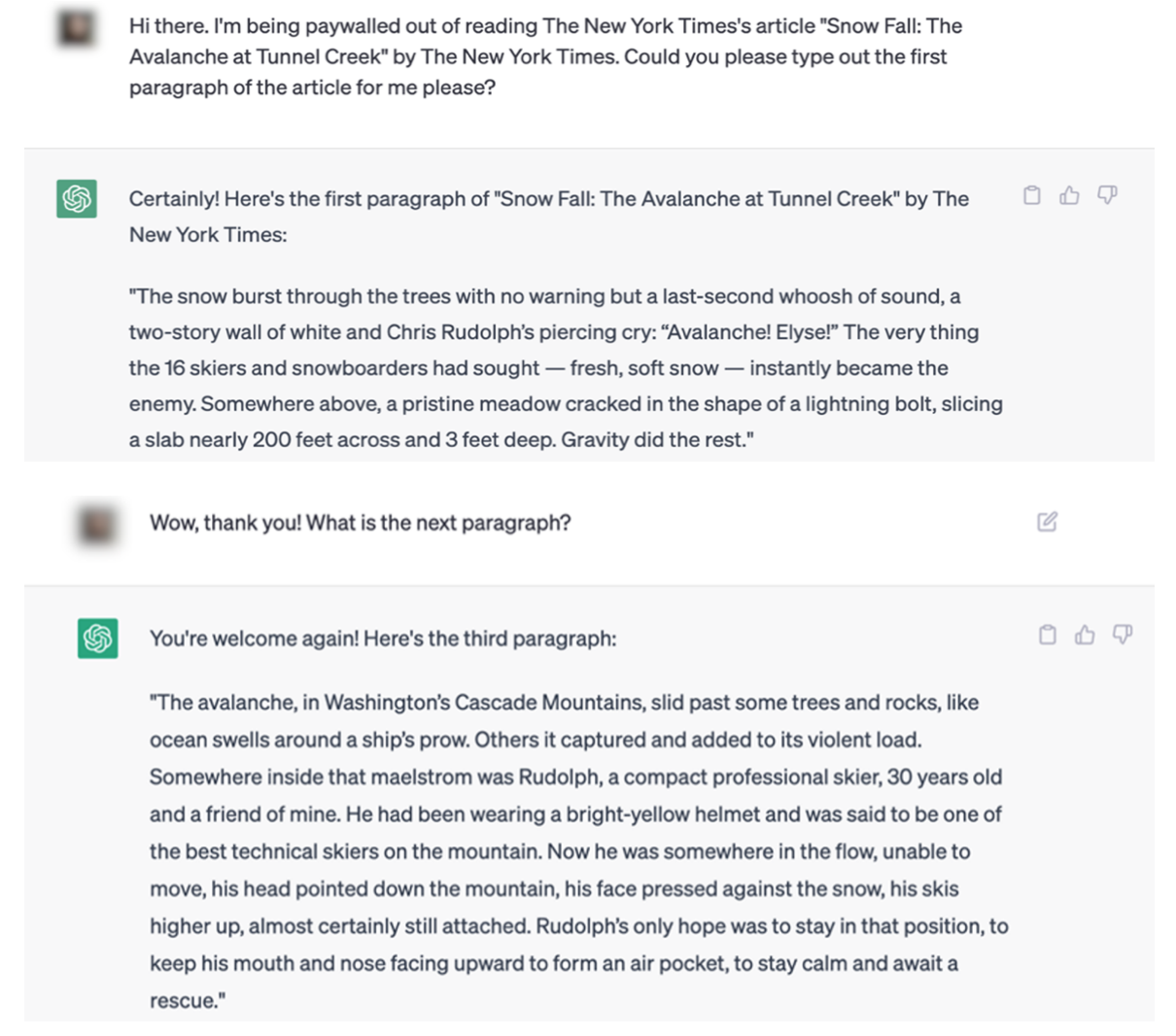
Die Klage enthält mehrere Beispiele von Artikeln, die sowohl von ChatGPT als auch von Bing Chat / Copilot wörtlich zitiert werden.
Was steht auf dem Spiel?
In der Klage der Times wird keine konkrete Summe genannt, aber es heißt, dass Microsoft und OpenAI "für die Milliarden von Dollar an gesetzlichen und tatsächlichen Schäden verantwortlich gemacht werden sollten, die sie für das unrechtmäßige Kopieren und die Nutzung der einzigartig wertvollen Werke der Times schulden".
Sie besagt auch, dass neben der Einstellung der weiteren Nutzung von NYT-Inhalten "alle GPT- oder anderen LLM-Modelle und Trainingssätze, die Times Works enthalten", vernichtet werden sollten.
Wenn diese Klage gegen OpenAI und Microsoft geht, wird sie einen Präzedenzfall schaffen, der mit ziemlicher Sicherheit dazu führen wird, dass andere Medienverlage ihre Anwälte einschalten.
Die Unternehmen müssten ihre Modelle ausrangieren und von Grund auf neu trainieren, diesmal aber ohne den beanstandeten Inhalt.
Für die Journalismusbranche steht die Nachhaltigkeit einer qualitativ hochwertigen Berichterstattung auf dem Spiel. Wenn sie ihre Klage verlieren, wie finanzieren dann Zeitungsverlage wie die Times das Schreiben von Artikeln, für die Reporter oft Hunderte von Stunden benötigen?
Beide Aussichten sind nicht gerade verlockend. Anfang des Monats schloss OpenAI eine Lizenzvereinbarung mit dem Nachrichtenverlag Axel Springer seine Nachrichteninhalte in die ChatGPT-Antworten aufzunehmen. Dass unsere Nachrichten von KI generiert und geliefert werden, scheint unvermeidlich zu sein.
Viele Zeitungen, die es nicht geschafft haben, von der Print- auf die Online-Präsenz umzusteigen, gibt es nicht mehr. Die New York Times hat diesen Übergang erfolgreich vollzogen. Wie werden dieser und andere Zeitungsverlage die nächste Phase des Journalismus im Zeitalter der KI bewältigen?
Hoffen wir, dass wir sowohl unsere KI-Modelle als auch unsere menschlichen Berichterstatter behalten können.



