

Aktuelle KI-Modelle sind in der Lage, eine Menge unsicherer oder unerwünschter Dinge zu tun. Menschliche Aufsicht und Feedback halten diese Modelle auf Kurs, aber was wird passieren, wenn diese Modelle schlauer werden als wir?
OpenAI hält es für möglich, dass in den nächsten 10 Jahren eine KI entwickelt wird, die intelligenter ist als der Mensch. Mit der zunehmenden Intelligenz geht das Risiko einher, dass der Mensch nicht mehr in der Lage ist, diese Modelle zu überwachen.
Das Superalignment-Forschungsteam von OpenAI konzentriert sich auf die Vorbereitung auf diese Eventualität. Das Team wurde im Juli dieses Jahres ins Leben gerufen und wird von Ilya Sutskever geleitet, der seit der Sam-Altman-Ära ein Schattendasein führt. Entlassung und anschließende Wiedereinstellung.
Die Beweggründe für das Projekt wurden von OpenAI in einen ernüchternden Kontext gestellt: "Derzeit haben wir keine Lösung, um eine potenziell superintelligente KI zu steuern oder zu kontrollieren und zu verhindern, dass sie abtrünnig wird."
Aber wie bereitet man sich darauf vor, etwas zu kontrollieren, das es noch gar nicht gibt? Das Forschungsteam hat gerade seine erste experimentelle Ergebnisse und versucht, genau das zu tun.
Schwache bis starke Verallgemeinerung
Im Moment ist der Mensch noch intelligenter als KI-Modelle. Modelle wie GPT-4 werden mit Hilfe von Reinforcement Learning Human Feedback (RLHF) gelenkt oder ausgerichtet. Wenn die Leistung eines Modells unerwünscht ist, sagt der menschliche Trainer dem Modell: "Tu das nicht", und belohnt es mit einer Bestätigung der gewünschten Leistung.
Im Moment funktioniert das, weil wir ziemlich gut verstehen, wie die aktuellen Modelle funktionieren, und wir sind schlauer als sie. Wenn künftige menschliche Datenwissenschaftler eine superintelligente KI trainieren müssen, werden die Rollen der Intelligenz vertauscht sein.
Um diese Situation zu simulieren, beschloss OpenAI, ältere GPT-Modelle wie GPT-2 zu verwenden, um leistungsfähigere Modelle wie GPT-4 zu trainieren. GPT-2 würde den zukünftigen menschlichen Trainer simulieren, der versucht, ein intelligenteres Modell zu verfeinern.
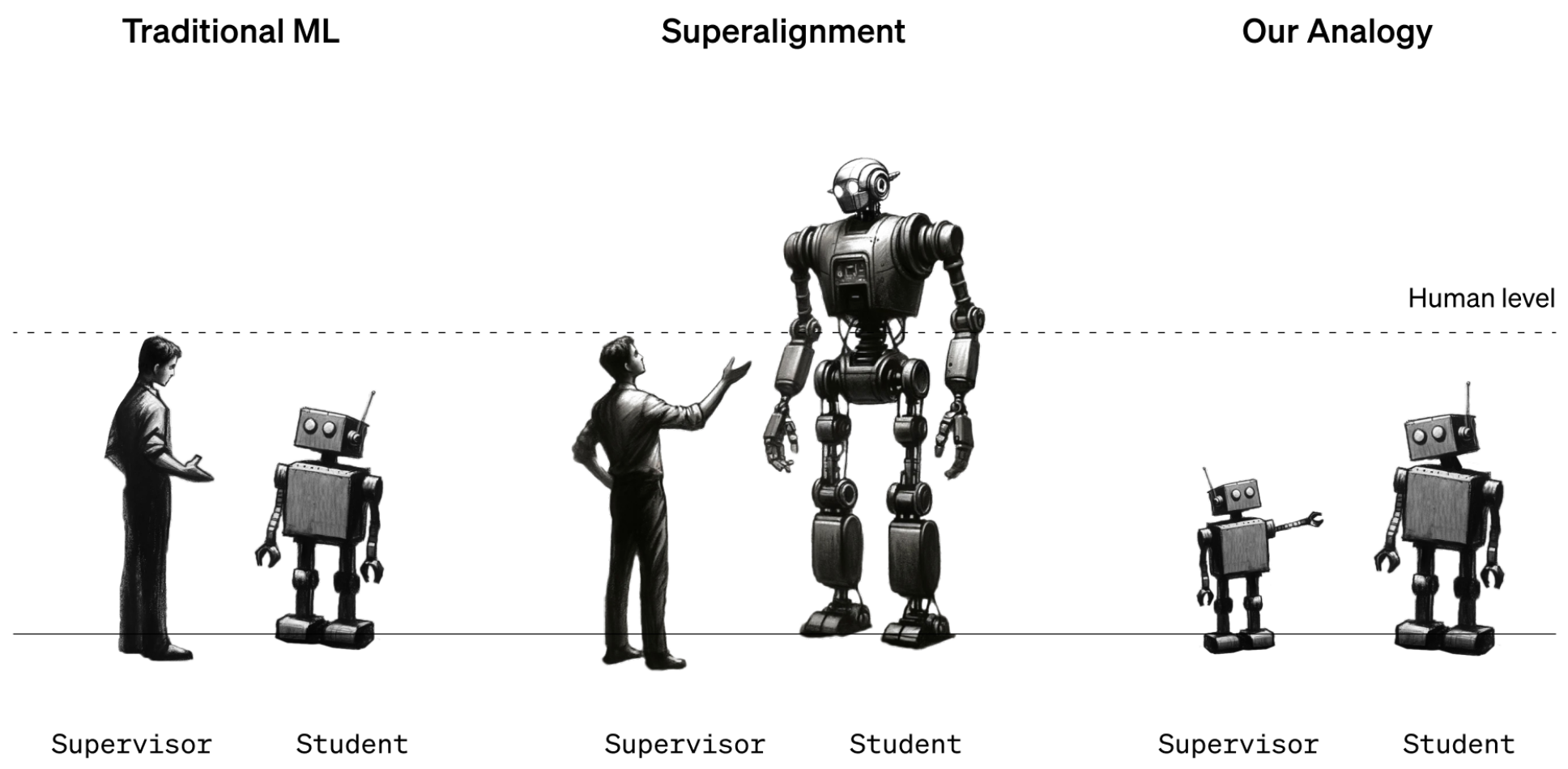
In dem Forschungspapier heißt es: "Genau wie das Problem, dass Menschen übermenschliche Modelle überwachen, ist unser System ein Beispiel für das so genannte "weak-to-strong learning"-Problem.
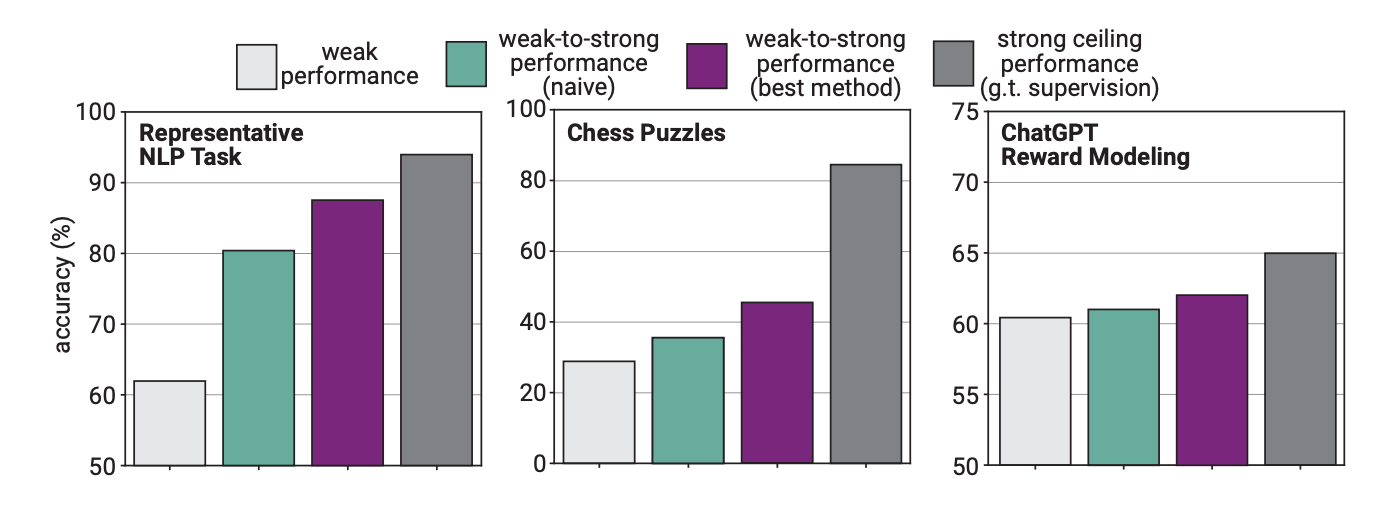
In dem Experiment verwendete OpenAI GPT-2 zur Feinabstimmung von GPT-4 bei NLP-Aufgaben, Schachrätseln und der Modellierung von Belohnungen. Anschließend wurde die Leistung von GPT-4 bei diesen Aufgaben getestet und mit einem GPT-4-Modell verglichen, das mit der "Grundwahrheit" oder den richtigen Antworten auf die Aufgaben trainiert worden war.
Die Ergebnisse waren insofern vielversprechend, als GPT-4, wenn es von dem schwächeren Modell trainiert wurde, in der Lage war, stark zu verallgemeinern und das schwächere Modell zu übertreffen. Dies zeigt, dass eine schwächere Intelligenz eine stärkere anleiten kann, die dann auf diesem Training aufbauen kann.
Stellen Sie sich das so vor, dass ein Drittklässler einem wirklich klugen Kind etwas Mathematik beibringt und das kluge Kind dann auf der Grundlage des anfänglichen Unterrichts die Mathematik der 12ten Klasse beherrscht.
Leistungslücke
Die Forscher stellten fest, dass das GPT-4 durch ein weniger intelligentes Modell trainiert wurde und dadurch nur eine Leistung erbrachte, die der eines gut trainierten GPT-3.5-Modells entsprach.
Das liegt daran, dass das intelligentere Modell einige der Fehler oder schlechten Denkprozesse von seinem schwächeren Vorgesetzten lernt. Dies scheint darauf hinzudeuten, dass der Einsatz von Menschen zur Ausbildung einer superintelligenten KI die KI daran hindern würde, ihr volles Potenzial auszuschöpfen.
Die Forscher schlugen vor, Zwischenmodelle in einem Bootstrapping-Ansatz zu verwenden. In dem Papier heißt es: "Anstatt sehr übermenschliche Modelle direkt abzugleichen, könnten wir zunächst ein nur leicht übermenschliches Modell abgleichen, das wir dann verwenden, um ein noch intelligenteres Modell abzugleichen, und so weiter."
OpenAI stellt eine Menge Ressourcen für dieses Projekt zur Verfügung. Das Forschungsteam sagt, dass es "20% der Rechenleistung, die wir uns bis heute gesichert haben, in den nächsten vier Jahren für die Lösung des Problems der Anpassung der Superintelligenz verwendet".
Sie bietet auch $10 Millionen an Zuschüssen für Einzelpersonen oder Organisationen, die die Forschung unterstützen wollen.
Sie sollten das besser bald herausfinden. Eine superintelligente KI könnte möglicherweise eine Million Zeilen komplizierten Codes schreiben, die kein menschlicher Programmierer verstehen könnte. Woher sollen wir wissen, ob der erzeugte Code sicher ist oder nicht? Hoffen wir, dass wir das nicht auf die harte Tour herausfinden.



