

Das Technology Innovation Institute (TII) der Vereinigten Arabischen Emirate hat letzte Woche seine Falcon 180B LLM auf Hugging Face vorgestellt, die in ersten Tests beeindruckende Leistungen zeigte.
Das Modell, das Forschern und kommerziellen Nutzern offen steht, ist das Ergebnis einer aufkeimenden KI-Industrie im Nahen Osten.
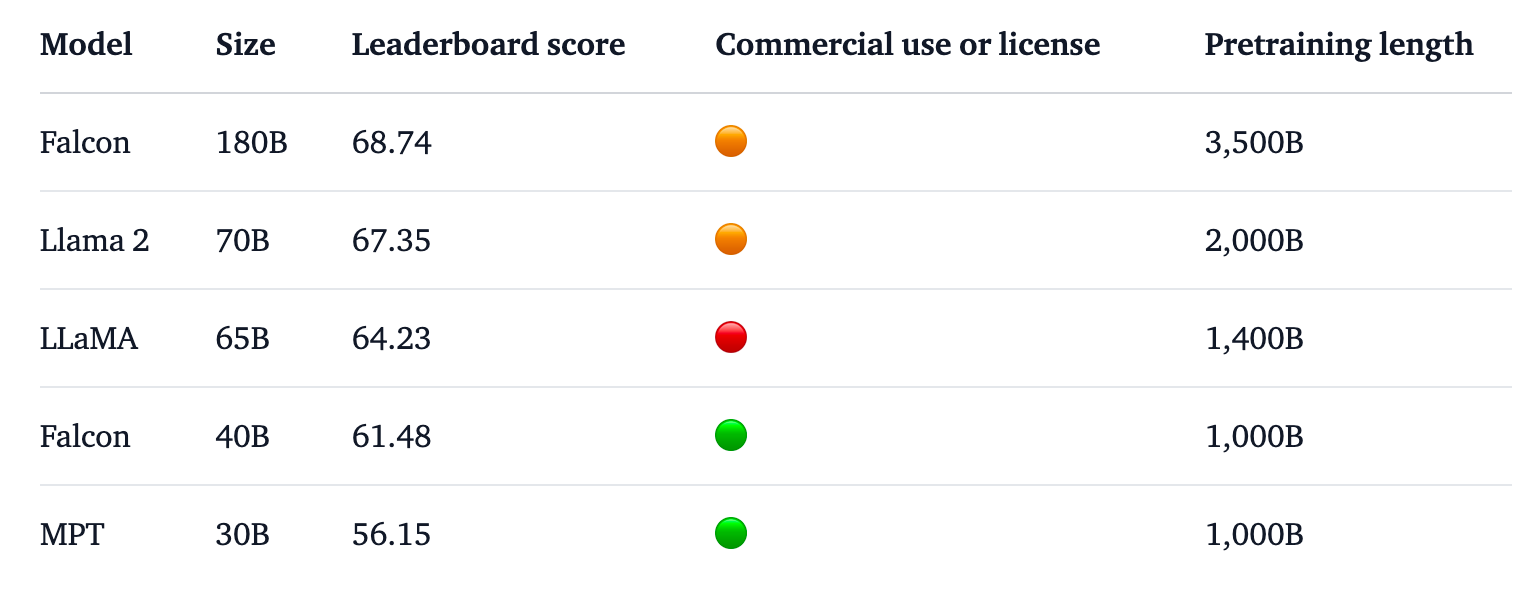
Falcon 180B ist 2,5 Mal größer als Metas Lama 2 und wurde mit viermal mehr Rechenleistung trainiert. Das TII trainierte das Modell mit einer riesigen Menge von 3,5 Billionen Token. Es ist der einzigartige Ansatz des Datensatzes, der weitgehend für die beeindruckende Leistung des Modells verantwortlich ist.
Um ein Modell zu trainieren, braucht man nicht nur eine Menge Daten, sondern in der Regel auch eine Menge kuratierter Daten von guter Qualität. Das kostet viel Geld, und es gibt nicht viele wirklich große kuratierte Datensätze, die öffentlich zugänglich sind. TII beschloss, einen neuartigen Ansatz zu verfolgen, um die Notwendigkeit der Kuratierung zu vermeiden.
Im Juni verwendeten die Forscher sorgfältige Filterung und Deduplizierung der öffentlich verfügbaren CommonCrawl-Daten, um den RefinedWeb-Datensatz zu erstellen. Dieser Datensatz war nicht nur einfacher zu erstellen, sondern er bietet auch eine bessere Leistung als die Verwendung von kuratierten Korpora oder Webdaten.
Falcon 180B wurde auf 3,5 Billionen Token des RefinedWeb-Datensatzes trainiert, deutlich mehr als die 2 Billionen Token des Llama 2-Vortrainingsdatensatzes.
Leistung der Falcon 180B
Falcon 180B steht an der Spitze der Hugging Face Rangliste für Open Access LLMs. Das Modell übertrifft Llama 2, den bisherigen Spitzenreiter, in einer Reihe von Benchmarks, darunter Tests zum logischen Denken, zur Codierung, zu den Fähigkeiten und zum Wissen.
Der Falcon 180B schneidet sogar im Vergleich mit proprietären Closed-Source-Modellen gut ab. Es rangiert knapp hinter GPT-4 und ist gleichauf mit Googles PaLM 2 Large, das doppelt so groß ist wie Falcon 180B.
Quelle: Gesicht umarmen
Das TII sagt, dass es trotz der bereits beeindruckenden Leistung seines vortrainierten Modells beabsichtigt, "in Zukunft immer leistungsfähigere Versionen von Falcon bereitzustellen, die auf verbesserten Datensätzen und RLHF/RLAIF basieren."
Sie können eine Chat-Version des Modells wie folgt ausprobieren Falcon 180B Demo auf "Hugging Face".
Die Chat-Version ist feinabgestimmt und bereinigt, aber das Basismodell verfügt noch nicht über Anpassungsleitplanken. Die TII sagte, dass es "problematische" Antworten geben könnte, da es noch keinen Feinabstimmungs- oder Anpassungsprozess durchlaufen hat.
Es wird einige Zeit dauern, bis sie so ausgerichtet ist, dass sie mit Sicherheit kommerziell eingesetzt werden kann.
Dennoch verdeutlicht die beeindruckende Leistung dieses Modells die Möglichkeiten für Verbesserungen, die über eine einfache Skalierung der Rechenressourcen hinausgehen.
Falcon 180B zeigt, dass kleinere Modelle, die auf qualitativ hochwertigen Datensätzen trainiert werden, eine kostengünstigere und effizientere Richtung für die KI-Entwicklung darstellen können.
Die Veröffentlichung dieses beeindruckenden Modells unterstreicht das rasante Wachstum der KI-Entwicklung im Nahen Ostentrotz der jüngsten Ausfuhrbeschränkungen für GPUs in die Region.
Da Unternehmen wie TII und Meta ihre leistungsstarken Modelle weiterhin unter Open-Access-Lizenzen veröffentlichen, wird es interessant sein zu sehen, was Google und OpenAI tun, um die Akzeptanz ihrer geschlossenen Modelle zu fördern.
Die Leistungslücke zwischen Open-Access- und proprietären Modellen scheint sich definitiv zu schließen.



