

Eine neue Studie zeigt, dass das Trainieren von KI-Bildgeneratoren mit KI-generierten Bildern letztendlich zu einer deutlichen Verringerung der Ausgabequalität führt.
Baraniuk und sein Team zeigten, wie sich diese problematische KI-Trainingsschleife auf generative KI auswirkt, einschließlich StyleGAN und Diffusionsmodelle. Diese gehören zu den Modellen, die für KI-Bildgeneratoren wie Stable Diffusion, DALL-E und MidJourney verwendet werden.
In ihrem Experimenttrainierte das Team die KI entweder mit KI-generierten oder realen Bildern. 70.000 echte menschliche Gesichter von Flickr.
Als jede KI auf ihren eigenen, von ihr erzeugten Bildern trainiert wurde, begannen die Ergebnisse des StyleGAN-Bildgenerators verzerrte und wellige visuelle Muster zu zeigen, während die Ergebnisse des Diffusionsbildgenerators unschärfer wurden.
In beiden Fällen führte das Training von KI auf KI-generierten Bildern zu einem Qualitätsverlust.
Einer der Studie Der Autor Richard Baraniuk von der Rice University in Texas warnt: "Die Verwendung synthetischer Daten, ob wissentlich oder unwissentlich, ist eine schlüpfrige Angelegenheit".
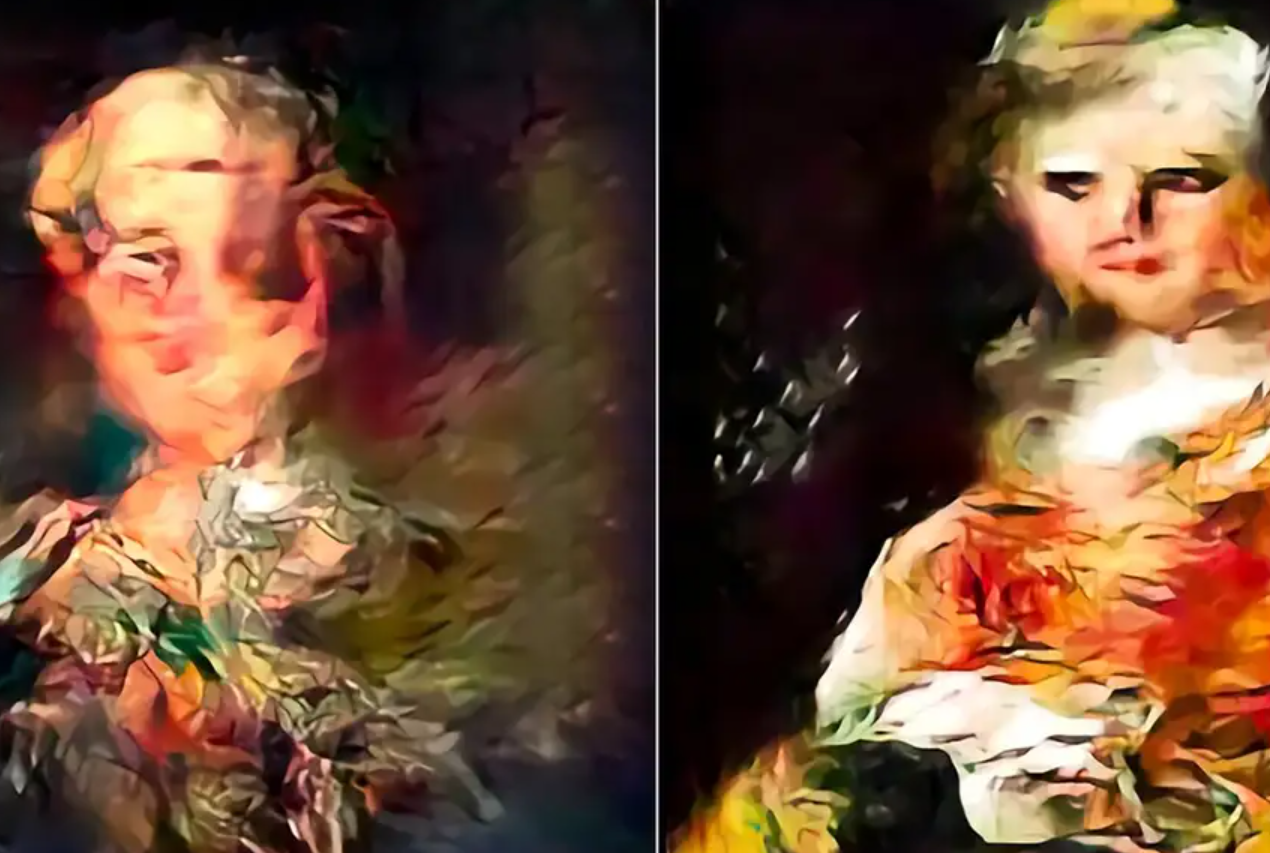
Der Rückgang der Bildqualität konnte zwar durch die Auswahl von KI-generierten Bildern höherer Qualität für das Training verringert werden, doch führte dies zu einem Verlust an Bildvielfalt.
Die Forscher versuchten auch, einen festen Satz echter Bilder in die Trainingssätze einzubauen, die hauptsächlich KI-generierte Bilder enthielten, eine Methode, die manchmal zur Ergänzung kleiner Trainingssätze verwendet wird.
Dies hat die Verschlechterung der Bildqualität jedoch nur verzögert - es scheint unvermeidlich, dass die Ergebnisse umso schlechter werden, je mehr KI-generierte Daten in die Trainingsdatensätze einfließen. Es ist nur eine Frage des Zeitpunkts.
Angemessene Ergebnisse wurden erzielt, wenn jede KI mit einer Mischung aus KI-generierten Bildern und einer ständig wechselnden Menge authentischer Bilder trainiert wurde. Dies trug dazu bei, die Qualität und Vielfalt der Bilder zu erhalten.
Es ist schwierig, ein Gleichgewicht zwischen Quantität und Qualität zu finden - synthetische Bilder sind im Vergleich zu echten Bildern potenziell unbegrenzt, aber ihre Verwendung hat ihren Preis.
KIs gehen die Daten aus
KI sind datenhungrig, aber echte, hochwertige Daten sind eine endliche Ressource.
Die Ergebnisse dieser Untersuchung spiegeln ähnliche Studien zur TexterstellungDie KI-Ergebnisse leiden in der Regel, wenn Modelle auf KI-generierten Text trainiert werden.
Die Forscher betonen, dass kleinere Organisationen mit begrenzten Möglichkeiten, authentische Daten zu sammeln, die größten Herausforderungen beim Herausfiltern von KI-generierten Bildern aus ihren Datenbeständen haben.
Erschwerend kommt hinzu, dass das Internet mit KI-generierten Inhalten überschwemmt wird, so dass es erstaunlich schwierig ist, die Art der Daten zu bestimmen, auf denen die Modelle trainiert wurden.
Sina Alemohammad von der Rice University schlägt vor, dass die Entwicklung von Wasserzeichen zur Identifizierung von KI-generierten Bildern hilfreich sein könnte, warnt aber davor, dass übersehene versteckte Wasserzeichen die Qualität von KI-generierten Bildern beeinträchtigen können.
Alemohammad schlussfolgert: "Man ist verdammt, wenn man es tut, und verdammt, wenn man es nicht tut. Aber es ist auf jeden Fall besser, das Bild mit einem Wasserzeichen zu versehen als nicht.
Die langfristigen Folgen des KI-Konsums werden kontrovers diskutiert, aber im Moment müssen KI-Entwickler Lösungen finden, um die Qualität ihrer Modelle zu gewährleisten.



