

Nvidia har annonceret ny open source-software, som de siger vil øge inferensydelsen på deres H100 GPU'er.
En stor del af den nuværende efterspørgsel efter Nvidias GPU'er er at opbygge computerkraft til træning af nye modeller. Men når modellerne er trænet, skal de bruges. Inferens i AI refererer til evnen hos en LLM som ChatGPT til at drage konklusioner eller komme med forudsigelser ud fra data, den er blevet trænet på, og generere output.
Når du prøver at bruge ChatGPT, og der dukker en besked op om, at serverne er overbelastede, er det, fordi computerhardwaren har svært ved at følge med efterspørgslen efter slutninger.
Nvidia siger, at deres nye software, TensorRT-LLM, kan få deres eksisterende hardware til at køre meget hurtigere og mere energieffektivt.
Softwaren indeholder optimerede versioner af de mest populære modeller, herunder Meta Llama 2, OpenAI GPT-2 og GPT-3, Falcon, Mosaic MPT og BLOOM.
Den bruger nogle smarte teknikker som mere effektiv batching af inferensopgaver og kvantificeringsteknikker til at opnå den øgede ydeevne.
LLM'er bruger generelt 16-bit floating point-værdier til at repræsentere vægte og aktiveringer. Kvantisering tager disse værdier og reducerer dem til 8-bit floating point-værdier under inferens. De fleste modeller formår at bevare deres nøjagtighed med denne reducerede præcision.
Virksomheder, der har en computerinfrastruktur baseret på Nvidias H100 GPU'er, kan forvente en enorm forbedring af inferensydelsen uden at skulle bruge en krone ved at bruge TensorRT-LLM.
Nvidia brugte et eksempel på at køre en lille open source-model, GPT-J 6, til at opsummere artikler i CNN/Daily Mail-datasættet. Den ældre A100-chip bruges som basishastighed og sammenlignes derefter med H100 uden og derefter med TensorRT-LLM.
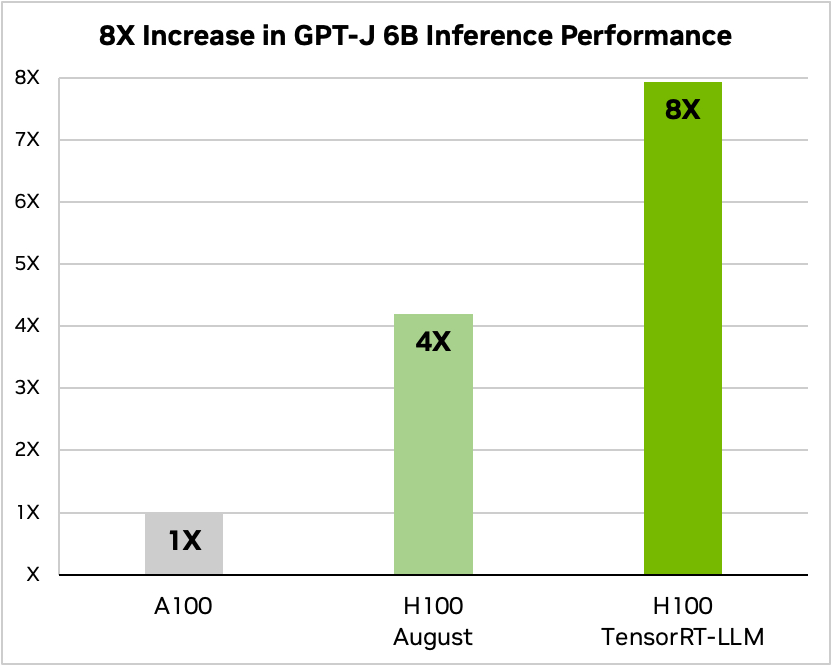
Kilde: Nvidia
Og her er en sammenligning, når du kører Meta's Llama 2
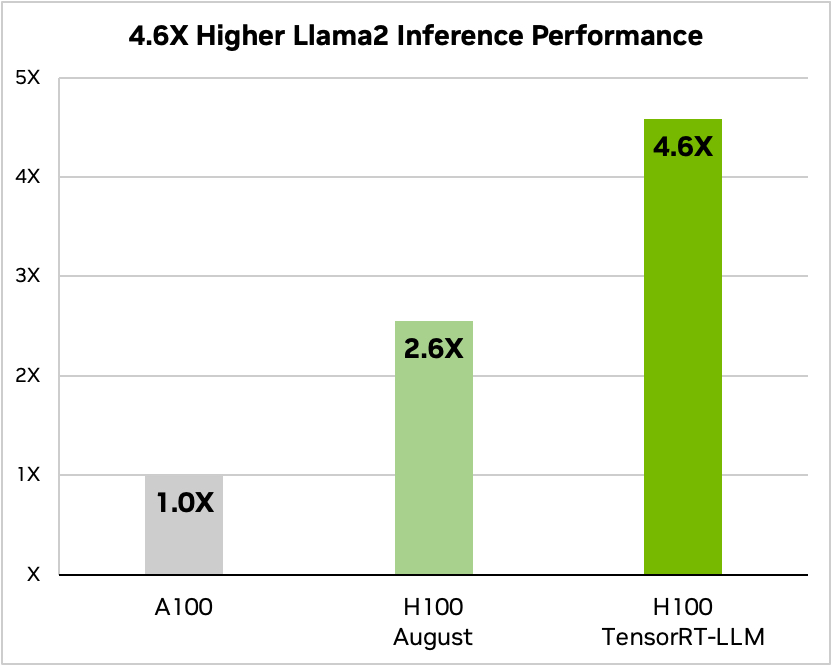
Kilde: Nvidia
Nvidia sagde, at deres test viste, at en H100, der kører TensorRT-LLM, afhængigt af modellen, bruger mellem 3,2 og 5,6 gange mindre energi end en A100 under inferens.
Hvis du kører AI-modeller på H100-hardware, betyder det ikke kun, at din slutningsydelse bliver næsten fordoblet, men også at din energiregning bliver meget mindre, når du har installeret denne software.
TensorRT-LLM vil også blive gjort tilgængelig for Nvidias Grace Hopper Superchips men virksomheden har ikke frigivet præstationstal for GH200, der kører den nye software.
Den nye software var endnu ikke klar, da Nvidia sendte sin GH200 Superchip gennem industristandarden MLPerf AI performance benchmarking tests. Resultaterne viste, at GH200 klarede sig op til 17% bedre end en single-chip H100 SXM.
Hvis Nvidia opnår blot en beskeden forbedring af inferensydelsen ved hjælp af TensorRT-LLM med GH200, vil det bringe virksomheden langt foran sine nærmeste konkurrenter. At være salgsrepræsentant for Nvidia må være det nemmeste job i verden lige nu.



