

Forskere fra University of Surrey har udviklet en metode til at omdanne fotografier af hunde til detaljerede 3D-modeller.
Træningsmaterialet? Ikke rigtige hunde, men derimod computergenererede billeder fra den virtuelle verden i hitspillet Grand Theft Auto V (GTA V).
Moira Shooter, en forskerstuderende, der var involveret i undersøgelsen, delt af undersøgelsen"Vores model blev trænet på CGI-hunde - men vi var i stand til at bruge den til at lave 3D-skeletmodeller ud fra fotografier af rigtige dyr. Det kunne give naturfredningsfolk mulighed for at spotte skadede dyr eller hjælpe kunstnere med at skabe mere realistiske dyr i metaverse."
Hidtil har metoder til at lære AI om 3D-strukturer involveret brug af rigtige fotos sammen med data om objekternes faktiske 3D-positioner, ofte opnået gennem motion capture-teknologi.
Men når man anvender disse teknikker på hunde eller andre dyr, er der ofte for mange bevægelser at spore, og det er svært at få hundene til at opføre sig ordentligt i tilstrækkelig lang tid.
For at opbygge deres hundedatasæt ændrede forskerne GTA V's kode for at erstatte de menneskelige figurer med hundeavatarer gennem en proces kendt som "modding".

Forskerne producerede 118 videoer, der fangede disse virtuelle hunde i forskellige handlinger - siddende, gående, gøende og løbende - under forskellige miljøforhold.
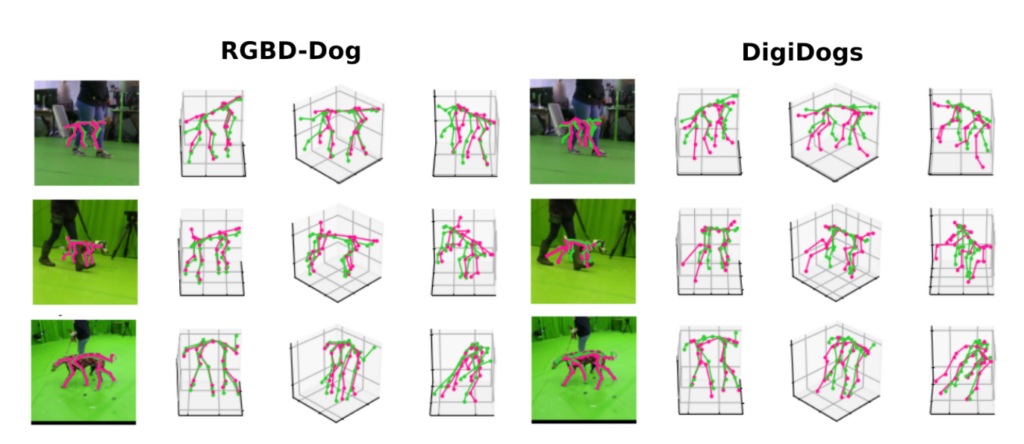
Dette kulminerede i oprettelsen af 'DigiDogs', en omfattende database med 27.900 billeder af hundebevægelser, der er indfanget på en måde, som dataindsamling i den virkelige verden ikke havde tilladt.
Med datasættet i hånden brugte de næste trin Metas DINOv2 AI-model for dens stærke generaliseringsevner og finjusterede den med DigiDogs for nøjagtigt at forudsige 3D-positurer fra RGB-billeder med en enkelt visning.
Forskerne demonstrerede, at brugen af DigiDogs datasæt til træning resulterede i mere nøjagtige og livagtige 3D-hundepositurer end dem, der blev trænet på datasæt fra den virkelige verden, takket være variationen i hundens udseende og handlinger, der blev fanget.
Modellens forbedrede ydeevne blev bekræftet gennem grundige kvalitative og kvantitative evalueringer.
Selvom denne undersøgelse var et stort skridt fremad inden for 3D-dyrmodellering, erkender holdet, at der er mere arbejde at gøre, især med at forbedre, hvordan modellen forudsiger dybdeaspektet af billederne (z-koordinaten).
Shooter beskrev den potentielle effekt af deres arbejde og sagde: "3D-poser indeholder så meget mere information end 2D-fotografier. Fra økologi til animation - denne smarte løsning har så mange anvendelsesmuligheder."
Den papir vandt prisen for bedste artikel ved IEEE/CVF Winter Conference on Applications of Computer Vision.
Det åbner døren til bedre modelydelse inden for områder som bevarelse af dyreliv og gengivelse af 3D-objekter til VR.



