

OpenAI frigav ikke nogen nye modeller på sit Dev Day-arrangement, men nye API-funktioner vil begejstre udviklere, som vil bruge deres modeller til at bygge stærke apps.
OpenAI har haft et par hårde uger, hvor virksomhedens tekniske direktør, Mira Murati, og andre ledende forskere har sluttet sig til den stadigt voksende liste over tidligere ansatte. Virksomheden er under stigende pres fra andre flagskibsmodeller, herunder open source-modeller, som tilbyder udviklere billigere og meget dygtige muligheder.
De nye funktioner, som OpenAI afslørede, var Realtime API (i beta), finjustering af synet og effektivitetsfremmende værktøjer som hurtig caching og modeldestillation.
API i realtid
Realtime API'en er den mest spændende nye funktion, omend den er i beta. Den gør det muligt for udviklere at bygge tale-til-tale-oplevelser med lav latenstid i deres apps uden at bruge separate modeller til talegenkendelse og tekst-til-tale-konvertering.
Med denne API kan udviklere nu skabe apps, der giver mulighed for realtidssamtaler med AI, f.eks. stemmeassistenter eller sprogindlæringsværktøjer, alt sammen gennem et enkelt API-opkald. Det er ikke helt den sømløse oplevelse, som GPT-4o's Advanced Voice Mode tilbyder, men det er tæt på.
Det er dog ikke billigt, ca. $0,06 pr. minut af lydinput og $0,24 pr. minut af lydoutput.
Den nye realtids-API fra OpenAI Det er utroligt.
Se den bestille 400 jordbær ved faktisk at RINGE til butikken med twillio. Alt sammen med stemmen. 🍓🎤 pic.twitter.com/J2BBoL9yFv
- Ty (@FieroTy) 1. oktober 2024
Finjustering af synet
Visuel finjustering i API'en giver udviklere mulighed for at forbedre deres modellers evne til at forstå og interagere med billeder. Ved at finjustere GPT-4o ved hjælp af billeder kan udviklere skabe applikationer, der udmærker sig i opgaver som visuel søgning eller objektregistrering.
Denne funktion udnyttes allerede af virksomheder som Grab, der forbedrede nøjagtigheden af sin kortlægningstjeneste ved at finjustere modellen til at genkende trafikskilte fra billeder på gadeniveau.
OpenAI gav også et eksempel på, hvordan GPT-4o kunne generere yderligere indhold til et websted efter at være blevet finjusteret til stilistisk at matche webstedets eksisterende indhold.
Prompt caching
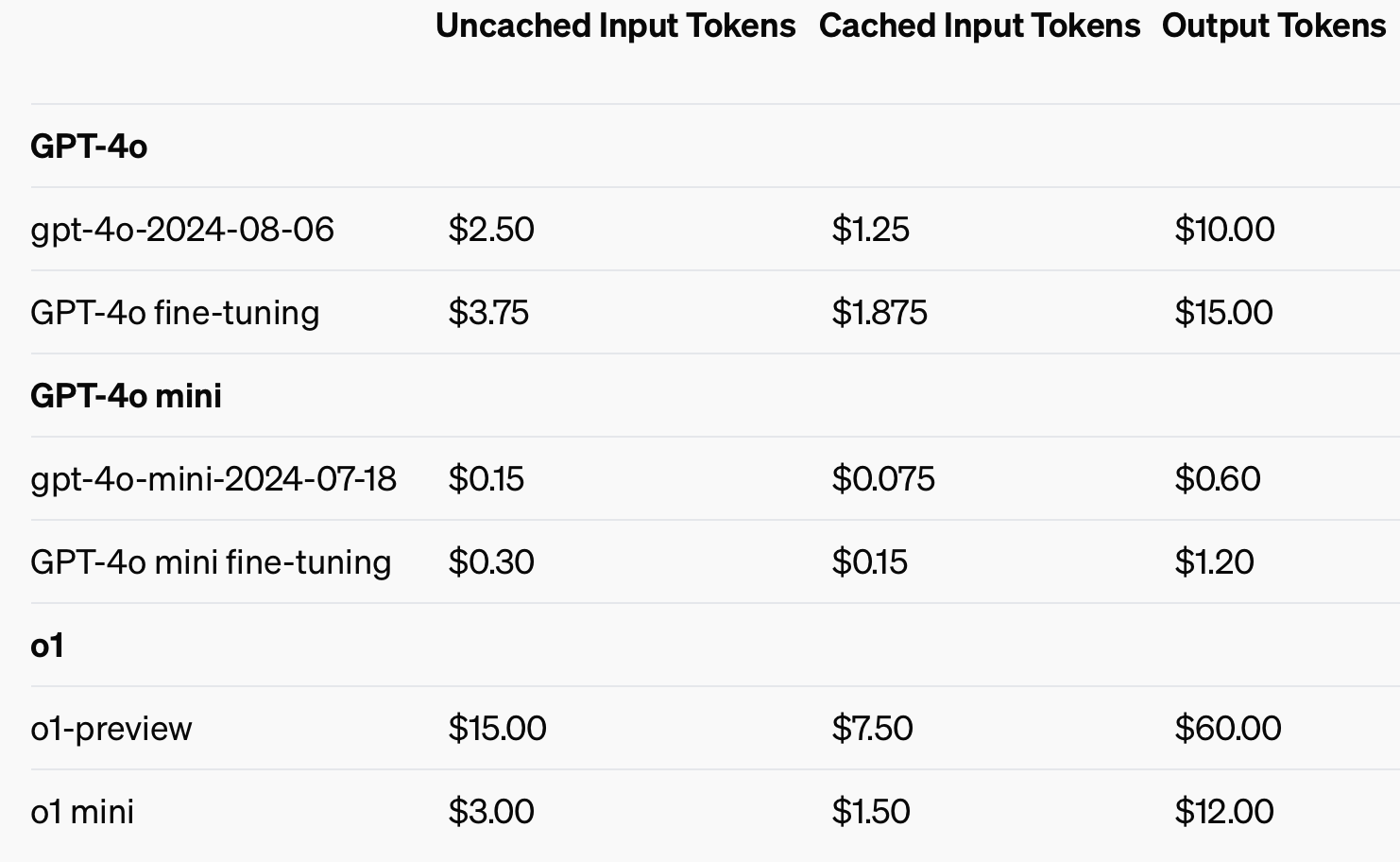
For at forbedre omkostningseffektiviteten introducerede OpenAI prompt caching, et værktøj, der reducerer omkostningerne og ventetiden for ofte anvendte API-opkald. Ved at genbruge nyligt behandlede input kan udviklere reducere omkostningerne med 50% og reducere svartiderne. Denne funktion er især nyttig for applikationer, der kræver lange samtaler eller gentagne kontekster, som chatbots og kundeserviceværktøjer.
Ved at bruge cachelagrede input kan man spare op til 50% i omkostninger til input-tokens.
Model destillation
Modeldestillation giver udviklere mulighed for at finjustere mindre, mere omkostningseffektive modeller ved hjælp af output fra større, mere effektive modeller. Dette er en game-changer, fordi destillation tidligere krævede flere adskilte trin og værktøjer, hvilket gjorde det til en tidskrævende og fejlbehæftet proces.
Før OpenAI's integrerede modeldestillationsfunktion måtte udviklere manuelt orkestrere forskellige dele af processen, som f.eks. at generere data fra større modeller, forberede finjusterende datasæt og måle ydeevne med forskellige værktøjer.
Udviklere kan nu automatisk gemme outputpar fra større modeller som GPT-4o og bruge disse par til at finjustere mindre modeller som GPT-4o-mini. Hele processen med oprettelse af datasæt, finjustering og evaluering kan udføres på en mere struktureret, automatiseret og effektiv måde.
Den strømlinede udviklerproces, den lavere ventetid og de reducerede omkostninger vil gøre OpenAI's GPT-4o-model attraktiv for udviklere, der ønsker at implementere kraftfulde apps hurtigt. Det bliver interessant at se, hvilke applikationer de multimodale funktioner muliggør.



