

Benchmarks har svært ved at følge med udviklingen af AI-modeller, og projektet Humanity's Last Exam ønsker din hjælp til at løse dette problem.
Projektet er et samarbejde mellem Center for AI Safety (CAIS) og AI-datavirksomheden Scale AI. Projektet har til formål at måle, hvor tæt vi er på at opnå AI-systemer på ekspertniveau, noget eksisterende benchmarks ikke er i stand til.
OpenAI og CAIS udviklede det populære MMLU-benchmark (Massive Multitask Language Understanding) i 2021. Dengang sagde CAIS, at "AI-systemer ikke klarede sig bedre end tilfældigt."
Den imponerende præstation af OpenAI's o1-model har "ødelagt de mest populære ræsonnement-benchmarks", ifølge Dan Hendrycks, administrerende direktør for CAIS.
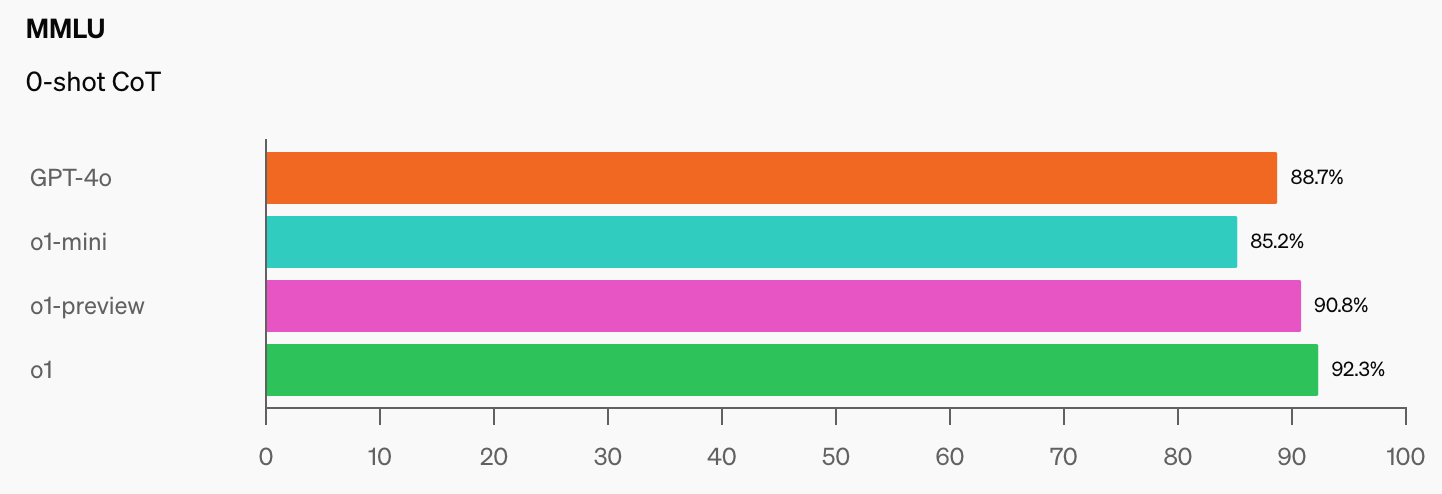
Når AI-modeller når 100% på MMLU, hvordan vil vi så måle dem? CAIS siger: "Eksisterende tests er nu blevet for lette, og vi kan ikke længere følge AI-udviklingen godt, eller hvor langt de er fra at blive ekspertniveau."
Når man ser det spring i benchmarkresultater, som o1 tilføjede til de allerede imponerende GPT-4o-tallene, varer det ikke længe, før en AI-model klarer MMLU.
Det er objektivt sandt. pic.twitter.com/gorahh86ee
- Ethan Mollick (@emollick) 17. september 2024
Humanity's Last Exam beder folk om at indsende spørgsmål, som virkelig ville overraske dig, hvis en AI-model leverede det rigtige svar. De vil have eksamensspørgsmål på ph.d.-niveau, ikke af typen "hvor mange R'er er der i jordbær", som får nogle modeller til at snuble.
Scale forklarede, at "når de eksisterende tests bliver for lette, mister vi evnen til at skelne mellem AI-systemer, der kan klare sig til eksamen, og dem, der virkelig kan bidrage til frontlinjeforskning og problemløsning."
Hvis du har et originalt spørgsmål, der kan gøre en avanceret AI-model stum, kan du få dit navn tilføjet som medforfatter til projektets artikel og få del i en pulje på $500.000, der uddeles til de bedste spørgsmål.
For at give dig en idé om det niveau, projektet sigter mod, forklarede Scale, at "hvis en tilfældigt udvalgt bachelor kan forstå, hvad der bliver spurgt om, er det sandsynligvis for let for nutidens og fremtidens kandidatstuderende."
Der er et par interessante begrænsninger på den slags spørgsmål, der kan indsendes. De vil ikke have noget, der er relateret til kemiske, biologiske, radiologiske og nukleare våben eller cybervåben, der bruges til at angribe kritisk infrastruktur.
Hvis du mener, at du har et spørgsmål, der opfylder kravene, kan du indsende det her.



