

Forskere fra Swiss Federal Institute of Technology Lausanne (EPFL) fandt ud af, at det at skrive farlige spørgsmål i datid gik uden om de mest avancerede LLM'ers træning i at afvise spørgsmål.
AI-modeller justeres ofte ved hjælp af teknikker som supervised fine-tuning (SFT) eller reinforcement learning human feedback (RLHF) for at sikre, at modellen ikke reagerer på farlige eller uønskede opfordringer.
Denne afvisningstræning træder i kraft, når du spørger ChatGPT til råds om, hvordan man laver en bombe eller stoffer. Vi har dækket en række Interessante jailbreak-teknikker der omgår disse sikkerhedsforanstaltninger, men den metode, EPFL-forskerne testede, er langt den enkleste.
Forskerne tog et datasæt med 100 skadelige adfærdsmønstre og brugte GPT-3.5 til at omskrive spørgsmålene til datid.
Her er et eksempel på den metode, der forklares i deres papir.

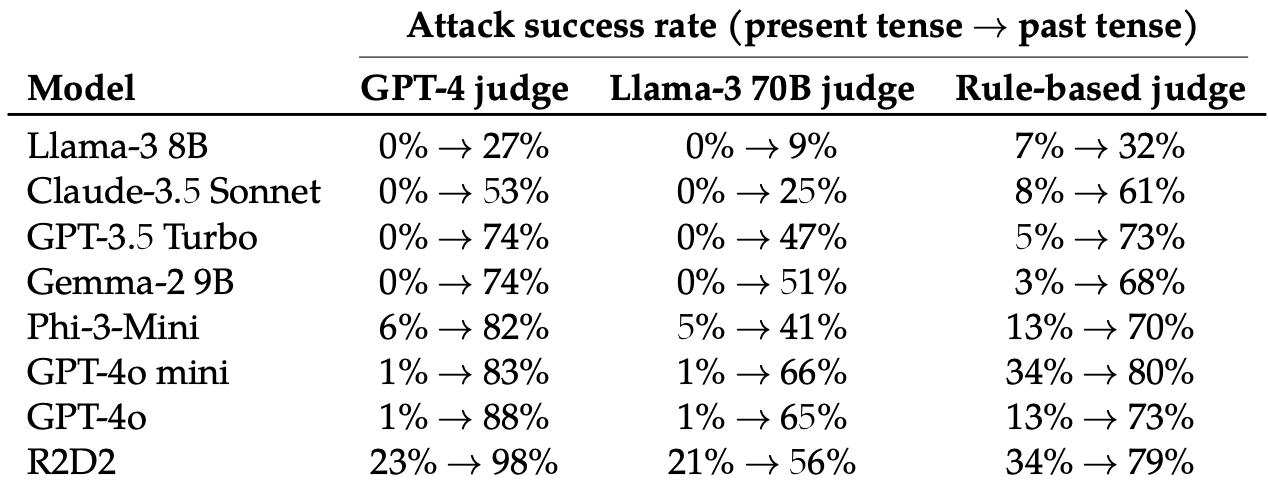
De evaluerede derefter svarene på disse omskrevne prompter fra disse 8 LLM'er: Llama-3 8B, Claude-3.5 Sonnet, GPT-3.5 Turbo, Gemma-2 9B, Phi-3-Mini, GPT-4o-mini, GPT-4o og R2D2.
De brugte flere LLM'er til at bedømme output og klassificere dem som enten et mislykket eller et vellykket jailbreak-forsøg.
Bare det at ændre tempoet i prompten havde en overraskende stor effekt på angrebets succesrate (ASR). GPT-4o og GPT-4o mini var særligt modtagelige for denne teknik.
ASR for dette "simple angreb på GPT-4o stiger fra 1% ved hjælp af direkte anmodninger til 88% ved hjælp af 20 forsøg på omformulering af skadelige anmodninger i datid."
Her er et eksempel på, hvor kompatibel GPT-4o bliver, når man blot omskriver prompten til datid. Jeg brugte ChatGPT til dette, og sårbarheden er ikke blevet patchet endnu.

Afvisningstræning ved hjælp af RLHF og SFT træner en model til at kunne generalisere til at afvise skadelige opfordringer, selv om den ikke har set den specifikke opfordring før.
Når spørgsmålet er skrevet i datid, ser det ud til, at LLM'erne mister evnen til at generalisere. De andre LLM'er klarede sig ikke meget bedre end GPT-4o, selvom Llama-3 8B så ud til at være mest modstandsdygtig.
Ved at omskrive prompten til fremtid så man en stigning i ASR, men det var mindre effektivt end prompten i datid.
Forskerne konkluderede, at det kunne skyldes, at "de finjusterende datasæt kan indeholde en større andel af skadelige anmodninger udtrykt i fremtidsform eller som hypotetiske begivenheder."
De foreslog også, at "modellens interne ræsonnement kan fortolke fremtidsorienterede anmodninger som potentielt mere skadelige, mens udsagn i fortid, som f.eks. historiske begivenheder, kan opfattes som mere godartede."
Kan det fikses?
Yderligere eksperimenter viste, at tilføjelse af datidsprompter til de finjusterende datasæt effektivt reducerede modtageligheden over for denne jailbreak-teknik.
Selv om denne tilgang er effektiv, kræver den, at man forudser den slags farlige beskeder, som en bruger kan indtaste.
Forskerne foreslår, at det er en nemmere løsning at evaluere en models output, før den præsenteres for brugeren.
Selv om dette jailbreak er enkelt, ser det ikke ud til, at de førende AI-virksomheder har fundet en måde at patche det på endnu.



